 NEWSLETTER
NEWSLETTER
Evaluating model performance is essential in the fields of artificial intelligence and machine learning, which are advancing considerably, especially with the introduction of large language models (LLMs). This review procedure helps to understand the capabilities of these models and to create reliable systems based on them. However, what are known as questionable research practices (QRPs) frequently jeopardize the integrity of these evaluations. These methods have the potential to greatly exaggerate published results, misleading the scientific community and the general public about the real effectiveness of ML models.
The main driving force behind QRPs is the ambition to publish in prestigious journals or attract funding and users. Due to the complexity of ML research, which includes pre-training, post-training and evaluation stages, there is great potential for QRPs. Contamination, cherry-picking and misinformation are the three basic categories under which these actions fall.
Pollution
When test set data is used for training, evaluation, or even model guidance, this is known as contamination. High-capacity models, such as LLMs, can remember test data that is exposed to them during training. Researchers have provided extensive documentation on this problem, detailing cases where models were intentionally or unintentionally trained using test data. There are several ways in which contamination can occur, which are as follows.
- Training on the test set – This leads to overly optimistic performance predictions when test data is unintentionally added to the training set.
- Immediate contamination: During evaluations of a few shots, using test data in the request gives the model an unfair advantage.
- Recovery Augmented Generation (RAG) Pollution: Data leakage through recovery systems that use benchmarks.
- Dirty Paraphrases and Tainted Models: Reworded test data and tainted models are used to train models, while tainted models are used to generate training data.
- Over-hyping and meta-contamination: Over-hyping and meta-contaminating designs by recycling contaminated designs or tuning hyperparameters after obtaining test results.
Cherry harvest
Culling is the practice of adjusting experimental conditions to support the intended outcome. Researchers can test their models multiple times in different scenarios and publish only the best results. This includes the following:
- Baseline nerfing: The deliberate sub-optimization of baseline models to give the impression that the new model is better.
- Runtime hacking: This involves modifying inference parameters after the fact to improve performance metrics.
- Choosing simpler benchmarks or subsets of benchmarks to ensure that the model performs well is known as benchmark hacking.
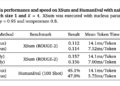
- Golden Seed: Report the highest performing seed after training with multiple random seeds.
Erroneous reports
Misreporting involves a variety of techniques when researchers present generalizations based on biased or limited parameters. For example, consider the following:
- Superfluous gear: Claiming originality by adding unnecessary modules.
- Whack-a-mole: Staying alert and adjusting certain flaws as needed.
- P-hacking: The selective presentation of statistically significant findings.
- Scores: Ignore variability by reporting results from a single run without error bars.
- Outright lies and over- or under-claims: creating false results or making incorrect claims about the model's capabilities.
Irreproducible research practices (IRPs), in addition to QRPs, increase the complexity of the machine learning evaluation environment. Subsequent researchers find it difficult to duplicate, extend, or examine prior research because of IRPs. A common example is dataset hiding, where researchers hide information about the training datasets they use, including metadata. The competitive nature of machine learning research and concerns about copyright infringement often motivate this technique. Validation and replication of discoveries, which are essential to advancing science, are hampered by a lack of transparency in dataset sharing.
In conclusion, the integrity of machine learning research and evaluation is critical. While QRPs and IRPs may benefit companies and researchers in the short term, they damage the credibility and trustworthiness of the field in the long term. Establishing and maintaining strict guidelines for research processes is essential as machine learning models become more widely used and have a greater impact on society. The full potential of machine learning models can only be realized with openness, accountability, and a dedication to moral research. It is imperative that the community works together to recognize and address these practices, ensuring that progress in machine learning is based on honesty and fairness.
Review the PaperAll credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter and join our Telegram Channel and LinkedIn GrAbove!. If you like our work, you will love our Newsletter..
Don't forget to join our Over 47,000 ML subscribers on Reddit
Find upcoming ai webinars here
Tanya Malhotra is a final year student of the University of Petroleum and Energy Studies, Dehradun, pursuing BTech in Computer Engineering with specialization in artificial intelligence and Machine Learning.
She is a data science enthusiast with good analytical and critical thinking, along with a keen interest in acquiring new skills, leading groups, and managing work in an organized manner.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>




{kind=link}