
Neural machine translation (NMT) is a sophisticated branch of natural language processing that automates the conversion of text between languages using machine learning models. Over the years, it has become an indispensable tool for global communication, with applications that cover various areas, such as the translation of technical documents and the localization of digital content. Despite its advances in translating simple texts, NMT faces persistent challenges in handling literary content rich in metaphors and similes. These expressions carry deep cultural and contextual nuances, which makes their translation much more complex. Conventional systems often resort to literal translations, which may not preserve the intended meaning and cultural essence, particularly in literature, where semantics are intertwined with artistic and emotional nuances.
Translating idiomatic expressions and metaphorical content involves unique difficulties arising from its dependence on cultural interpretation. Literal translations of such constructions often lead to a loss of nuance, making the result confusing or meaningless to native speakers. This problem persists even with the most advanced NMT systems, designed to excel at tasks involving structured or technical text but fail to interpret abstract and figurative language. Human translators invest considerable effort in reinterpreting these expressions to ensure that they align with the cultural framework of the target audience while preserving the original intent. Closing this gap in automated systems requires a novel approach capable of mimicking this human adaptability.
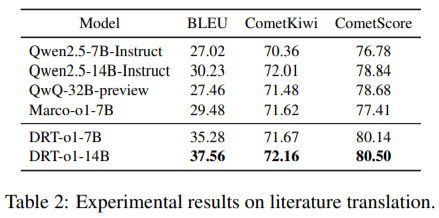
Existing NMT tools leverage supervised fine-tuning (SFT) techniques to improve translation capabilities. These tools typically rely on data sets optimized for technical or simple text, such as manuals or academic articles. However, its performance decreases when it comes to metaphorical or idiomatic language. Systems like Qwen2.5 and Marco-O1 improve the accuracy and fluency of basic translations, but they remain ill-equipped to handle the complexities of literary language. For example, Qwen2.5-7B achieves a BLEU score of 27.02 and Qwen2.5-14B improves it to 30.23, but neither comes close to meeting the high expectations of literary translation, where context and The nuances are essential.
Researchers at Tencent Inc. have developed an innovative system called DRT-o1 to overcome these limitations. It is made up of two variants:
They build on the backbone of Qwen2.5 and integrate a novel multi-agent framework to address the complexities of metaphorical and idiomatic translation. The researchers focused on literature as their primary domain and extracted approximately 400 public domain English books from Project Gutenberg. They extracted 577,600 sentences and filtered them to retain only 63,000 that contained similes and metaphors. These sentences were considered suitable for what the researchers describe as “long thinking” processes in machine translation. Unlike previous approaches, The DRT-o1 system is based on a collaborative method in which three agents participate:
- a translator
- an advisor
- an evaluator
Each agent iteratively refines the translation, ensuring that each result improves over the previous one.
The multi-agent framework at the core of DRT-o1 begins with the identification of key terms in a source sentence. These terms are translated individually to ensure contextual accuracy. The framework then generates a preliminary translation, which goes through multiple refinement cycles. During each iteration, the assessor provides feedback on the current translation and the evaluator assigns a score based on predefined quality metrics. This iterative process continues until the evaluator's score reaches a predefined threshold or the maximum number of iterations is reached. The results are then polished for fluency and readability using GPT-4o, creating a final data set of 22,264 long-thought-out machine translation samples.
The DRT-o1 system and its variants significantly improve performance over existing NMT models. Experimental results reveal that DRT-o1-7B achieves an 8.26-point increase in BLEU score and a 3.36-point increase in CometScore compared to its counterpart Qwen2.5-7B-Instruct. Similarly, DRT-o1-14B records a BLEU improvement of 7.33 and a CometScore increase of 1.66 over Qwen2.5-14B-Instruct. These results underscore the effectiveness of the multi-agent framework in capturing the subtleties of literary translation. In particular, DRT-o1-7B even outperforms larger models such as the QwQ-32B, demonstrating the scalability and efficiency of this system. For example, the 7B variant outperforms the QwQ-32B by 7.82 BLEU points and 1.46 CometScore, further establishing its capabilities in handling complex linguistic constructions.
Key findings from DRT-o1 research:
- Creating the dataset involved extracting 577,600 phrases from 400 public domain books, filtering them to 63,000 suitable for long-running processes.
- The multi-agent framework employs three roles (translator, assessor, and evaluator) to iteratively refine translations and ensure superior output quality.
- DRT-o1-7B improved its BLEU by 8.26 points, while DRT-o1-14B recorded an increase of 7.33 points, demonstrating the system's ability to outperform existing models.
- The integration of GPT-4o guarantees fluency and readability, further improving the quality of machine translations.
- DRT-o1-7B outperformed the larger QwQ-32B model by 7.82 BLEU points, highlighting its scalability and efficiency in translating complex literary content.
In conclusion, the DRT-o1 system and its variants (DRT-o1-7B and DRT-o1-14B) represent a transformative approach for neural machine translation. Researchers have addressed long-standing challenges by focusing on literary language and integrating a sophisticated multi-agent framework. The iterative refinement process preserves the meaning and cultural context of metaphors and similes and achieves performance metrics that surpass state-of-the-art models. This work highlights the potential of long-chain reasoning to improve NMT, providing a scalable and effective solution for translating nuanced texts with accuracy and cultural sensitivity.
Verify he Paper and GitHub page. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on <a target="_blank" href="https://twitter.com/Marktechpost”>twitter and join our Telegram channel and LinkedIn Grabove. Don't forget to join our SubReddit over 60,000 ml.
Trending: LG ai Research launches EXAONE 3.5 – three frontier-level bilingual open-source ai models that deliver unmatched instruction following and broad context understanding for global leadership in generative ai excellence….
Sana Hassan, a consulting intern at Marktechpost and a dual degree student at IIT Madras, is passionate about applying technology and artificial intelligence to address real-world challenges. With a strong interest in solving practical problems, he brings a new perspective to the intersection of ai and real-life solutions.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}