
The seamless integration of large language models (LLMs) into the fabric of specialized scientific research represents a fundamental shift in the landscape of computational biology, chemistry, and more. Traditionally, LLMs excel at broad natural language processing tasks but fail to navigate the complex terrain of domains rich in specialized terminologies and structured data formats, such as protein sequences and chemical compounds. This limitation limits the usefulness of LLMs in these critical areas and restricts the potential for ai-driven innovations that could revolutionize scientific discovery and application.
To address this challenge, an innovative framework developed at Microsoft Research, TAG-LLM, emerges. It is designed to leverage the general capabilities of LLMs while adapting their skills to specialized domains. At the heart of TAG-LLM is a system of metalinguistic input tags, which ingeniously condition the LLM to skillfully navigate domain-specific landscapes. These labels, conceptualized as continuous vectors, are cleverly added to the model's embedding layer, allowing it to recognize and process specialized content with unprecedented accuracy.
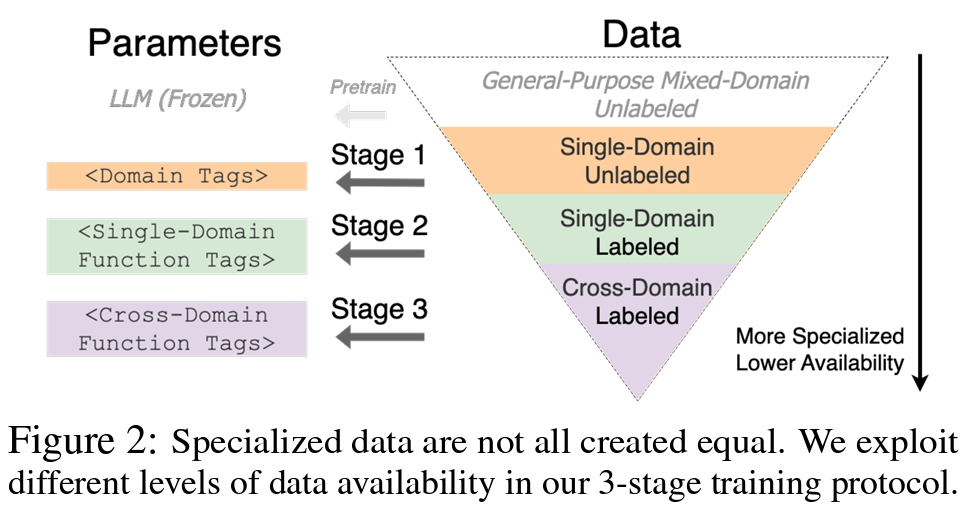
The ingenuity of TAG-LLM is developed through a meticulously structured methodology that comprises three stages. Initially, domain labels are cultivated using unsupervised data, capturing the essence of domain-specific knowledge. This fundamental step is crucial as it allows the model to become familiar with the unique linguistic and symbolic representations endemic to each specialized field. These domain labels are then subjected to an enrichment process, infusing them with task-relevant information that further refines their usefulness. The culmination of this process sees the introduction of feature labels designed to guide the LLM through a wide variety of tasks within these specialized domains. This tripartite approach leverages the inherent knowledge embedded in LLMs and equips them with the flexibility and precision needed for domain-specific tasks.
The prowess of TAG-LLM is vividly illustrated through its exemplary performance on a spectrum of tasks involving protein properties, chemical compound characteristics, and drug-target interactions. Compared to existing models and tuning approaches, TAG-LLM demonstrates superior effectiveness, underlined by its ability to outperform specialized models tailored to these tasks. This notable achievement is a testament to the strength of TAG-LLM and highlights its potential to catalyze significant advances in scientific research and applications.
Beyond its immediate applications, the implications of TAG-LLM extend far beyond scientific research and discovery. TAG-LLM opens new avenues to leverage ai to advance our understanding and capabilities within these fields by bridging the gap between general-purpose LLMs and the nuanced requirements of specialized domains. Its versatility and efficiency present a compelling solution to the challenges of applying ai to technical and scientific research, promising a future where ai-driven innovations are at the forefront of scientific advances and applications.
TAG-LLM is an innovation model that embodies the confluence of ai and specialized scientific research. Its development addresses a critical challenge in the application of LLM to technical domains and lays the foundation for a new era of ai-driven scientific discoveries. TAG-LLM's journey from concept to realization underscores the transformative potential of ai to revolutionize our approach to scientific research, heralding a future in which the limits of what can be achieved through science-driven ai are continually expanding.
Review the Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on Twitter and Google news. Join our 36k+ ML SubReddit, 41k+ Facebook community, Discord channeland LinkedIn Grabove.
If you like our work, you will love our Newsletter..
Don't forget to join our Telegram channel
![]()
Muhammad Athar Ganaie, consulting intern at MarktechPost, is a proponent of efficient deep learning, with a focus on sparse training. Pursuing an M.Sc. in Electrical Engineering, with a specialization in Software Engineering, he combines advanced technical knowledge with practical applications. His current endeavor is his thesis on “Improving Efficiency in Deep Reinforcement Learning,” which shows his commitment to improving ai capabilities. Athar's work lies at the intersection of “Sparse DNN Training” and “Deep Reinforcement Learning.”
<!– ai CONTENT END 2 –>






{kind=link}