 NEWSLETTER
NEWSLETTER
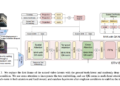
Learning in context with large language models (LLM) has emerged as a promising avenue of research in Dialog State Tracking (DST). However, the best performing in-context learning methods involve retrieving and adding similar examples to the message, which requires access to labeled training data. Obtaining such training data for a wide range of domains and applications is time-consuming, expensive, and sometimes infeasible. While zero-shot learning requires no training data, it lags significantly behind the few-shot configuration. Therefore, “Can we efficiently generate synthetic data for any dialogue scheme to enable short prompts?” To address this question, we propose SynthDST, a data generation framework designed for DST, using LLM. Our approach only requires the dialogue schema and some handcrafted dialogue templates to synthesize natural, coherent and fluid dialogues with DST annotations. Few-shot learning using SynthDST data results in a 4-5% improvement in joint target accuracy over the zero-shot baseline in MultiWOZ 2.1 and 2.4. Surprisingly, our few-shot learning approach recovers almost 98% of the performance compared to the few-shot setup using human-annotated training data.




{kind=link}