
Underwriting is a fundamental function within the insurance industry, serving as the foundation for risk assessment and management. Underwriters are responsible for evaluating insurance applications, determining the level of risk associated with each applicant, and making decisions on whether to accept or reject the application based on the insurer’s guidelines and risk appetite.
In this post, we discuss how to use AWS generative artificial intelligence (ai) solutions like amazon Bedrock to improve the underwriting process, including rule validation, underwriting guidelines adherence, and decision justification. We’ve also provided an accompanying ai” target=”_blank” rel=”noopener”>GitHub repo so you can try the solution.
The underwriting process typically involves several key steps:
- Gathering and verifying information – Underwriters collect and review various data points about the applicant, such as age, health status, occupation, and lifestyle habits for life insurance, or property location, construction type, and safety features for property insurance
- Risk assessment – Underwriters analyze the potential risk of insuring the applicant using statistical models, actuarial data, and their own expertise
- Premium determination – Based on the risk assessment, underwriters calculate the appropriate premium for the desired coverage, aiming to strike a balance between competitive pricing and ensuring the insurer’s profitability
- Policy customization – Underwriters may tailor insurance policies to meet the specific needs of applicants while aligning with the insurer’s risk management strategy
- Decision-making – After assessing the risk and determining the appropriate premium, underwriters decide whether to accept or reject the application
Effective underwriting is crucial for the financial stability and profitability of insurance companies. By accurately assessing risk and setting appropriate premiums, underwriters help insurers maintain a balanced risk portfolio and avoid adverse selection of potential policy holders.
Challenges in document understanding for underwriting
Document understanding is a critical and complex aspect of the underwriting process that poses significant challenges for insurers. Underwriters must review and analyze a wide range of documents submitted by applicants, and the manual extraction of relevant information is a time-consuming and error-prone task. The challenges in document understanding can be broadly categorized into three areas:
- Rule validation – Verifying that the information provided in the documents adheres to the insurer’s underwriting guidelines. This is a complex task when faced with unstructured data, varying document formats, and erroneous data.
- Underwriting guidelines adherence – Consistently applying the insurer’s underwriting guidelines across all decisions is crucial for maintaining fairness and regulatory compliance. However, manual interpretation can lead to inconsistencies and potential human bias. Also, inconsistent data can lead to flawed rule applications, especially when dealing with large volumes of information.
- Decision justification – Providing clear and concise explanations for underwriting decisions, especially in cases where an application is denied or offered modified terms or exceptions. This can be time-consuming and may lack the necessary clarity and objectivity.
The impact of these challenges on the underwriting process is significant. Manual data extraction and analysis can slow down the workflow, leading to longer processing times and lower customer retention. Errors in data interpretation or inconsistencies in applying guidelines can result in incorrect risk assessments, premium leakage, and lost customers for the insurer.
To address these challenges, insurers are increasingly turning to advanced technologies such as machine learning, natural language processing, and intelligent document processing solutions.
However, implementing these technologies has been challenging for carriers. Building rules and pipelines for each document or insurance product may require dedicated teams, subject matter expertise in new technologies, and security and compliance controls. Additionally, traditional approaches lack contextual understanding that come with underwriting, causing fragility in existing solutions. In the next section, we explore how generative ai and amazon Bedrock can help insurers overcome these challenges and streamline the underwriting process through intelligent document understanding and automation.
How generative ai and amazon Bedrock help solve these challenges
One of the key advantages of generative ai is its ability to understand and interpret context within documents. Unlike traditional rule-based systems that rely on strict pattern matching, generative ai models can grasp the nuances and semantics of language, allowing them to extract meaningful insights even from complex and varied document formats. This contextual understanding is particularly valuable in underwriting, where the interpretation of information often requires domain-specific knowledge and reasoning.
amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading ai companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral ai, Stability ai, and amazon through a single API, along with a broad set of capabilities to build generative ai applications with security, privacy, and responsible ai.
amazon Bedrock simplifies the deployment, scaling, implementation, and management of generative ai models for insurers. With amazon Bedrock, insurers can easily integrate pre-trained models or custom-built models into their existing underwriting workflows and systems, without the need for extensive ML expertise or infrastructure management. Using the power of ai to automate tedious and time-consuming tasks enables underwriters to focus on their core competencies.
To equip FMs with up-to-date and proprietary information, such as underwriting manuals, you can use Retrieval Augmented Generation (RAG), a technique that fetches data from company data sources and enriches the prompt to provide more relevant and accurate responses. Knowledge Bases for amazon Bedrock is a fully managed capability that helps you implement the entire RAG workflow, from ingestion to retrieval and prompt augmentation, without having to build custom integrations to data sources and manage data flows.
In this solution, we use the knowledge base capability offered by amazon Bedrock to enhance the reasoning and decision-making process of the generative ai models. Knowledge Bases for amazon Bedrock allows us to ingest and incorporate relevant underwriting guidelines and manuals into the models’ knowledge base. Knowledge Bases for amazon Bedrock simplifies the integration process by eliminating the need for custom integrations with data sources and the management of complex data flows. It streamlines the ingestion and retrieval of underwriting manuals, so models have access to the most current and relevant information. We can fetch specific information from the ingested underwriting manuals and enrich the prompts provided to the models. This makes sure the models have access to the most up-to-date and relevant information, enabling them to provide more accurate and context-aware responses. Knowledge Bases for amazon Bedrock provides a crucial advantage by allowing insurers to infuse their proprietary domain knowledge and underwriting policies into the generative ai models. This empowers the models to make decisions that are fully aligned with the insurer’s risk management strategies, guidelines, and regulatory requirements.
Generative ai and amazon Bedrock can address specific challenges in document understanding for underwriting:
- Rule validation – Generative ai models can automatically validate the information provided in application documents against an insurer’s underwriting guidelines. By using techniques like RAG or in-context prompting, these models can extract relevant information from documents and compare it against predefined rules, flagging any discrepancies or non-compliance. This reduces the risk of errors and provides consistency in the underwriting process.
- Underwriting guidelines adherence – Generative ai enables insurers to embed their underwriting guidelines directly into the prompts or instructions provided to the models. By engineering these prompts, insurers can align their ai-driven decision-making process with the company’s risk management strategy. This approach minimizes inconsistencies and potential bias in underwriting decisions.
- Decision justification – Generative ai models can generate clear and concise explanations for underwriting decisions, providing transparency and objectivity in the process. These models can articulate the reasoning behind each decision based on the information extracted from documents and the insurer’s guidelines, along with the source documents used in its decision. This makes it straightforward for underwriters to review predications, and improves communication with applicants, auditors, and regulators.
By adopting generative ai and amazon Bedrock, insurers can enhance underwriting efficiency, reduce processing times, minimize errors, adhere to fairness and regulatory compliance, and improve transparency and customer satisfaction. In this post, we show a simple use case of validating documents against a set of underwriting guidelines, and in future posts, we will show more complex scenarios across a large corpus of documents, and more advanced underwriting rules.
Solution overview
The following diagram illustrates the automated process for verifying driver’s license records and validating underwriting rules using various AWS services.
The solution includes the following steps:
- Users upload an image of a driver’s license record to an amazon Simple Storage Service (amazon S3) bucket. The bucket is configured to send event notifications to amazon EventBridge.
- An EventBridge rule is configured to start an AWS Step Functions state machine when objects are uploaded to the S3 bucket.
- EventBridge sends the event data to the Step Functions workflow, which will orchestrate multiple AWS services to perform the required tasks for underwriting rules validation.
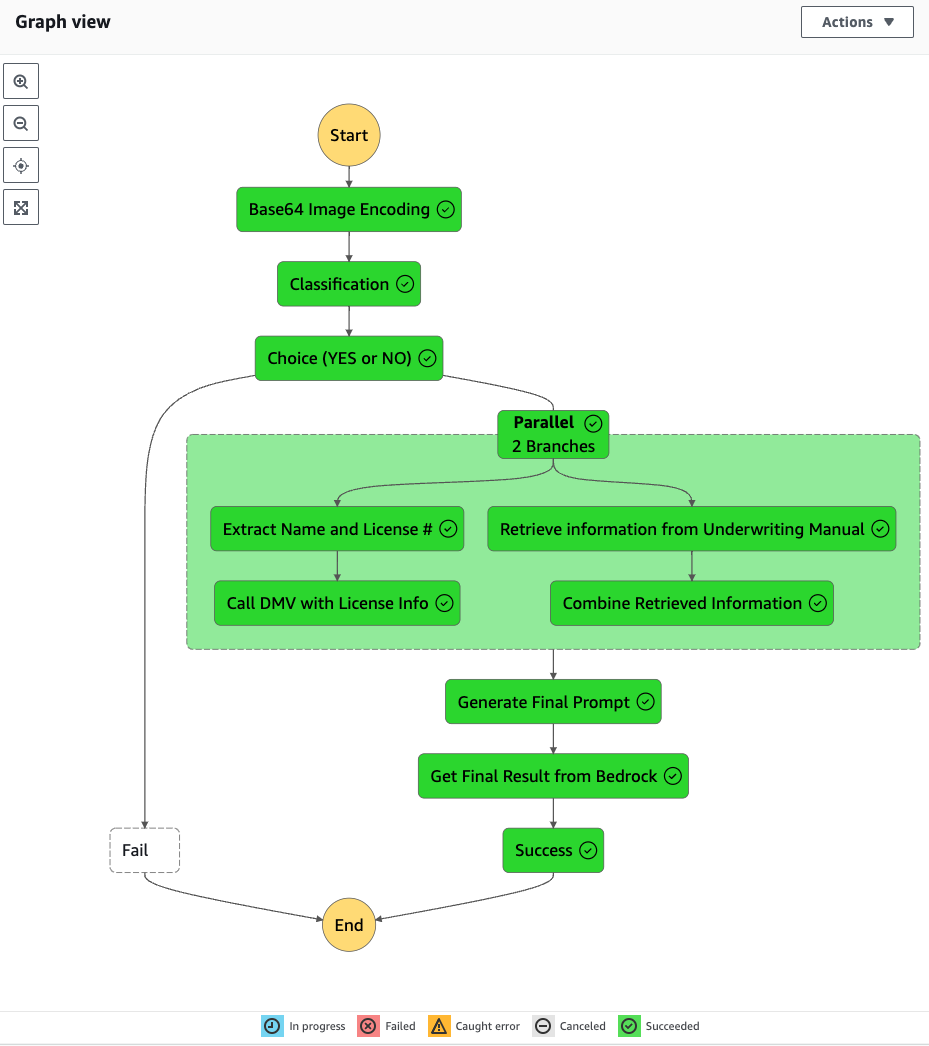
- The state machine starts and runs a series of event-driven steps:
- The workflow begins with the “Base64 Image Encoding” state, which encodes an image of the uploaded driver’s license into Base64 format.
- The Base64 encoding is then passed to the “Classification” state, which invokes Anthropic Claude 3 Haiku on amazon Bedrock to classify the image as a driver’s license.
- Based on the classification result, the workflow decides whether to proceed using the “Choice (YES or NO)” state.
- If classified as a driver’s license, the workflow proceeds to the “Parallel” state to run two amazon Bedrock tasks in parallel. If not classified as a driver’s license, the workflow will fail.
- Under the “Parallel” state, two tasks are run simultaneously:
- The first task proceeds to the “Extract Name and License #” workflow state, which uses amazon Bedrock to invoke Anthropic Claude 3 Haiku to extract the name and the driver’s license number from the image. The name and the license number are then passed to an AWS Lambda function “Call DMV API with License Info” state, which integrates with the relevant Department of Motor Vehicles (DMV) API to retrieve the driving record.
- The second task under the “Parallel” state performs a “Retrieve Information from Underwriting Manual” action to obtain the underwriting rules applicable for a driver to get insurance.
- The retrieved underwriting rules information is then passed to Lambda function “Combine Retrieved information” to compile under the same body of text all the relevant rules to be validated.
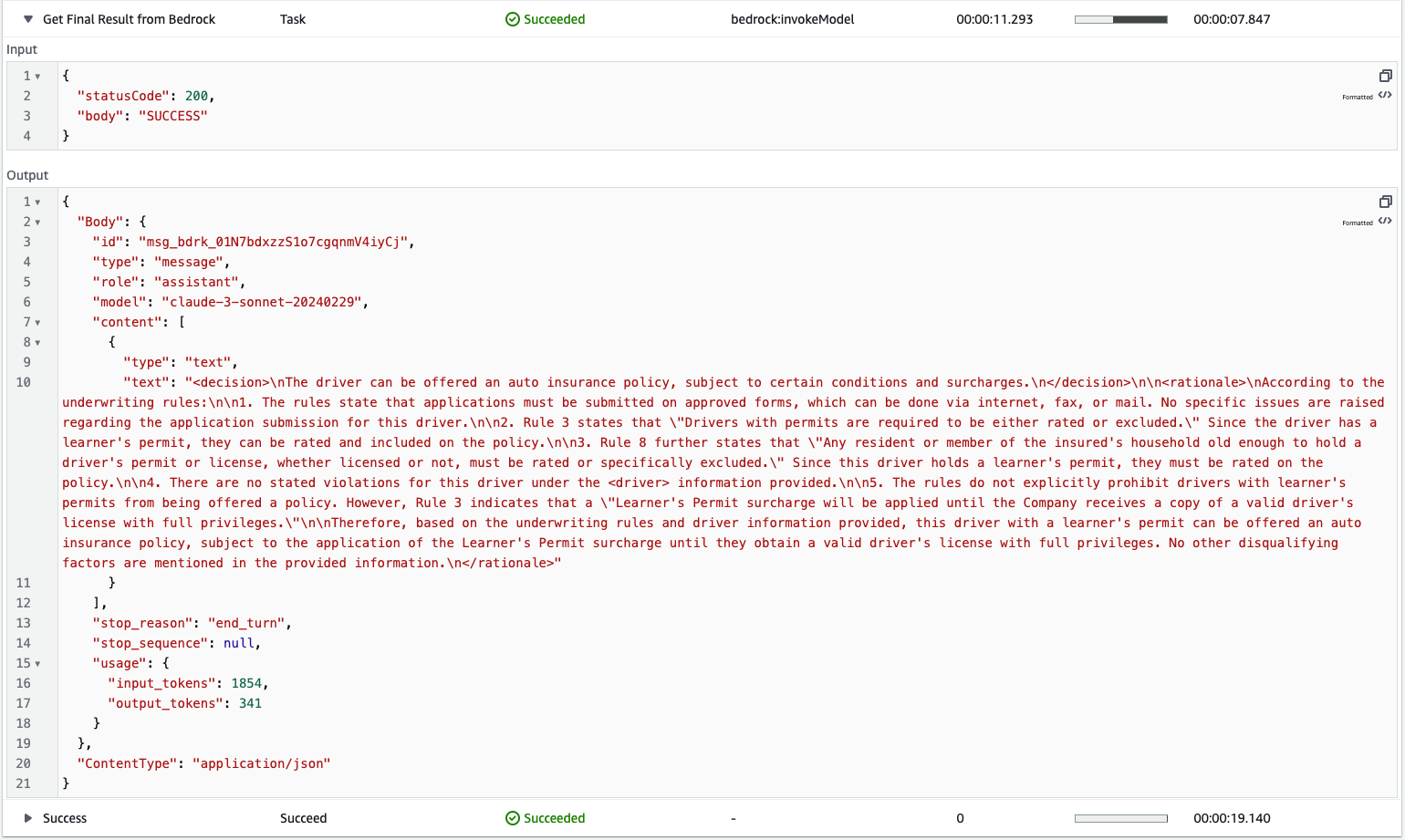
- The final step comprises two tasks: the Lambda function “Generate Final Prompt” creates the prompt to be used to perform the verification against the underwriting manual, considering also the driving record report, which is then used to invoke an amazon Bedrock model under the state “Get Final Result from Bedrock,” which generates the final report with the rules validation and recommendations.
By combining these AWS services and taking advantage of the capabilities of the Anthropic Claude 3 Haiku model, this solution offers a streamlined and intelligent approach to processing driver’s license records for underwriting rules validation purposes. It automates various tasks, reduces manual effort, and enhances the accuracy and efficiency of the underwriting process.
Prerequisites
You need to have the following to run the solution:
- An AWS account
- Basic understanding of how to download a repo from GitHub
- Basic knowledge of running a command on a terminal
- Underwriting guidelines
Deploy the solution
You can download all the necessary code with instructions from the ai/tree/main” target=”_blank” rel=”noopener”>GitHub repo. Follow the instructions in the GitHub repo README to deploy the solution.
Test the solution
To test the solution, upload a sample driver’s license to the underwriting document bucket.
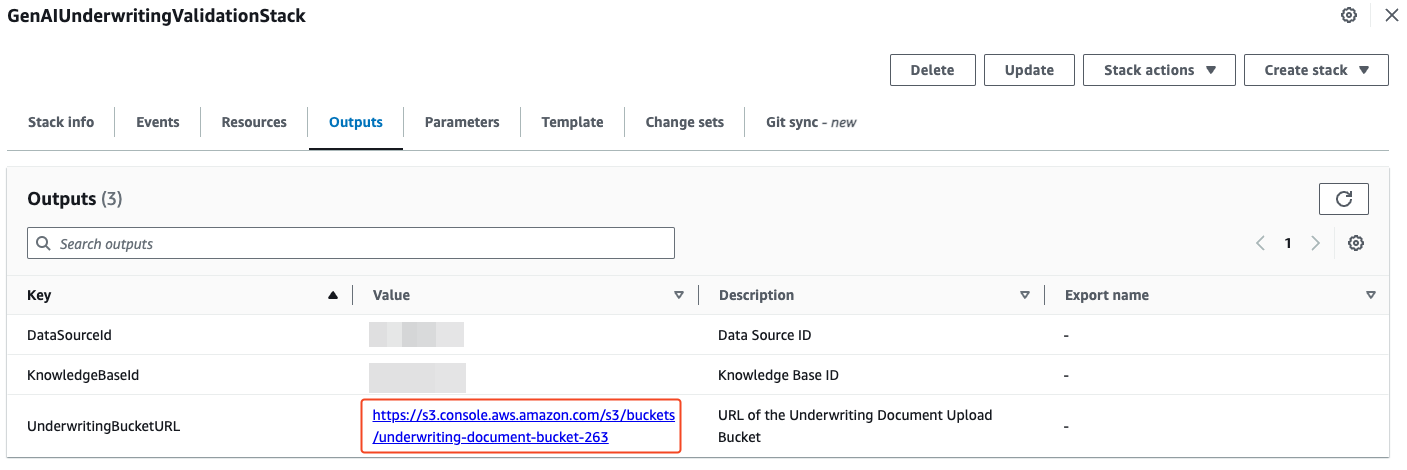
To find the URL of the underwriting document bucket, follow these steps:
- On the AWS CloudFormation console, choose Stacks in the navigation pane.
- Choose the stack GenAIUnderwritingValidationStack.
- On the Outputs tab, note the value for UnderwritingBucketURL.
To upload the sample driver’s license to the underwriting document bucket, follow these steps:
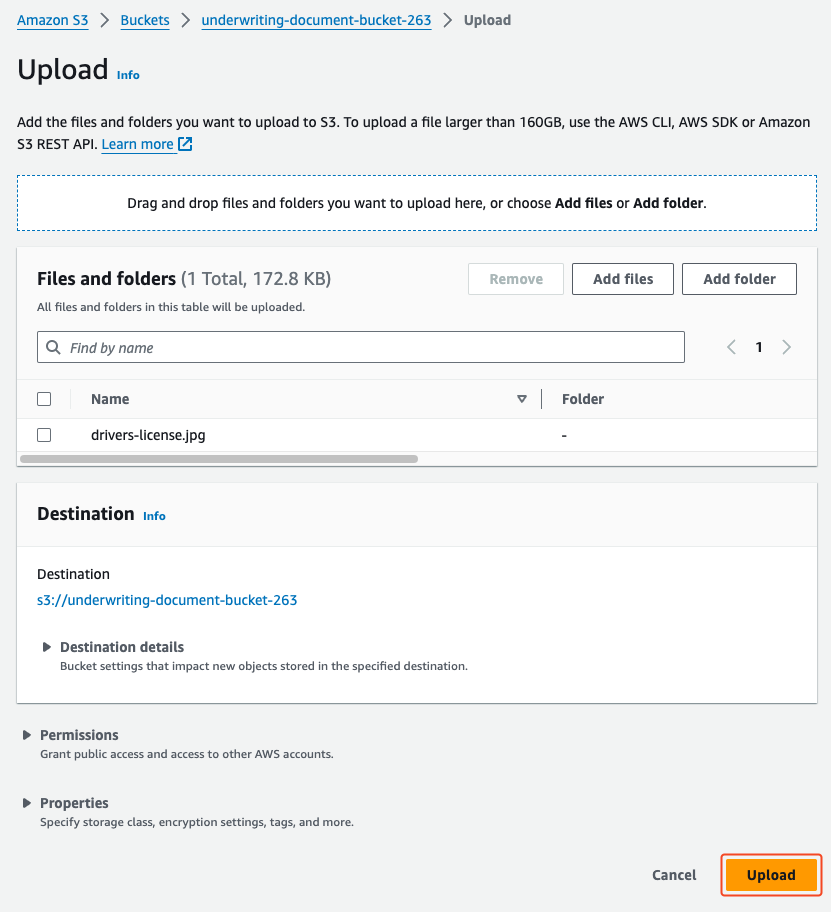
- On the amazon S3 console, navigate to the underwriting-document-bucket using the UnderwritingBucketURL.
- Choose Upload.
- Select the sample driver’s license and choose Upload.
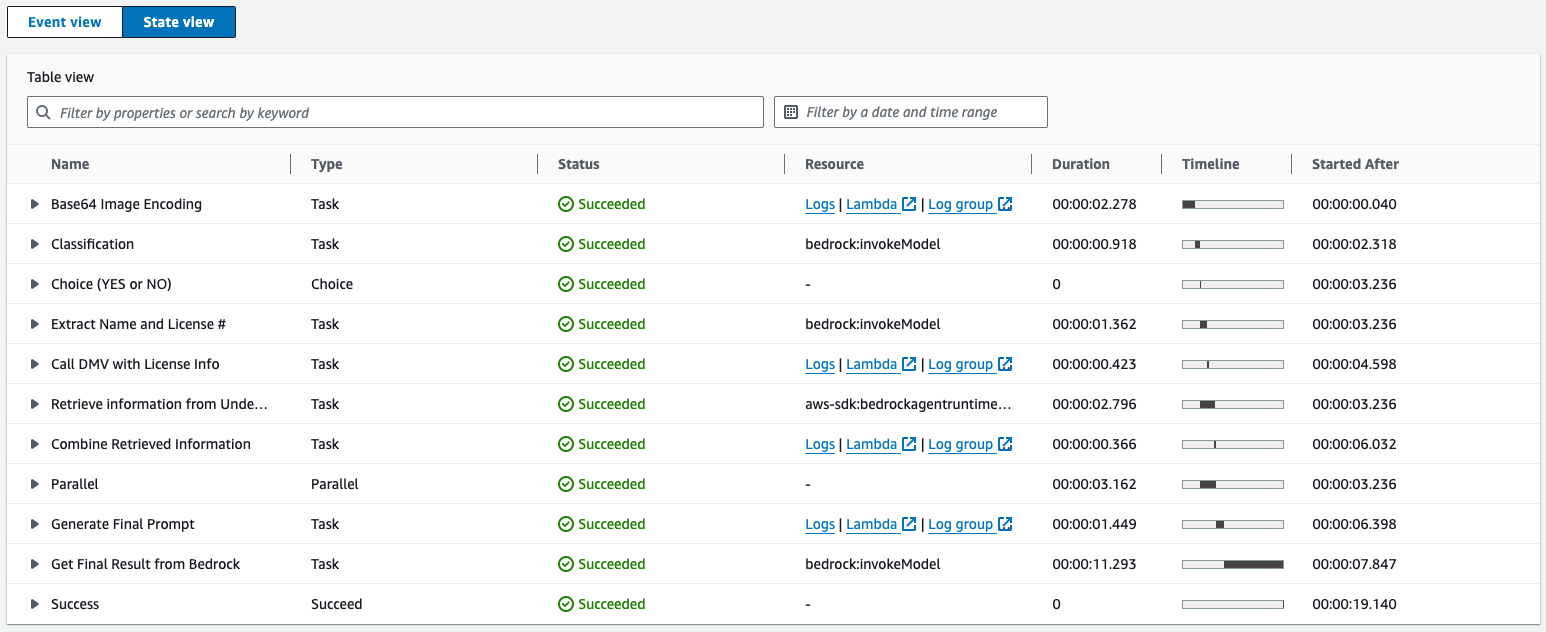
To review the workflow of the Step Functions state machine, follow these steps:
- On the Step Functions console, choose State machines in the navigation pane.
- Select UnderwritingValidationStateMachine and choose View details.
- Select the state machine and review the graph, event, and state views for more details.
Clean up
After you try out the solution, follow the cleanup instructions in the ai/tree/main” target=”_blank” rel=”noopener”>GitHub repo README to avoid accruing charges.
Pricing
This solution is composed of four primary services: amazon Bedrock, amazon S3, EventBridge, and Step Functions. We discuss On-Demand amazon Bedrock pricing in this post. For the other services, review the service’s pricing page.
With On-Demand mode, you pay only for what you use, with no time-based term commitments. For Anthropic Claude 3 models, you’re charged for every input token processed and every output token generated.
As shown in the following graph, pricing varies for each Anthropic models: Claude 3 Haiku, Claude 3 Sonnet, Claude 3 Opus.
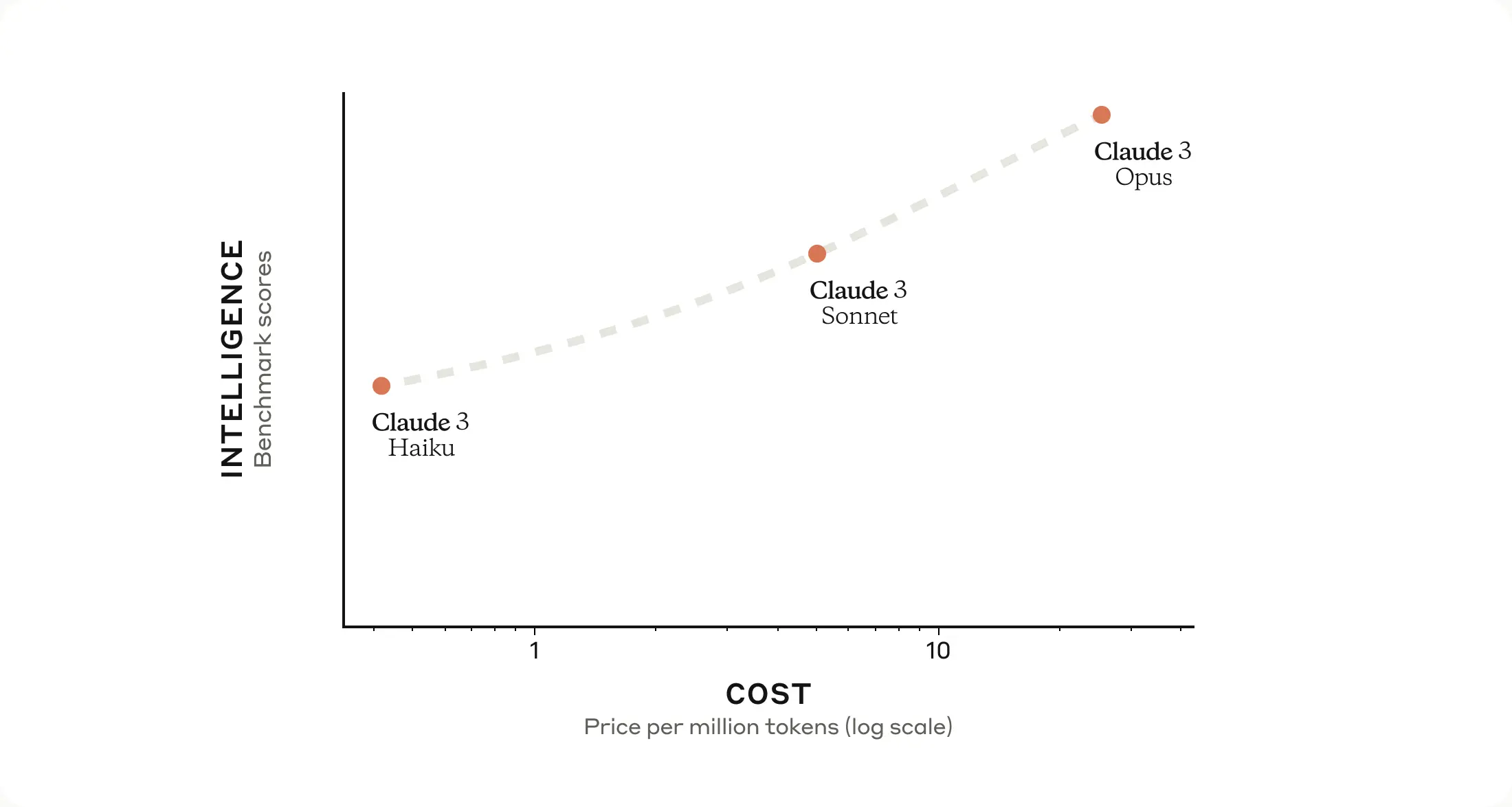
Claude 3 Haiku is Anthropic’s fastest, most compact model for near-instant responsiveness. Claude 3 Sonnet strikes the ideal balance between intelligence and speed—particularly for enterprise workloads. This solution uses the sophisticated vision capabilities of Haiku to process photos of drivers’ licenses and uses Sonnet to perform RAG-powered rule validation of a driver’s license record against an underwriting manual document.
Conclusion
In this post, we explored the critical and complex challenges of document understanding within the underwriting process for insurers. Manually extracting relevant information from applicant documents, validating adherence to underwriting guidelines, and providing clear justifications for decisions is time-consuming and error-prone, and can lead to inconsistencies. Generative ai and amazon Bedrock offer a powerful solution to help overcome these obstacles. We discussed how the reasoning and contextual understanding capabilities of generative ai models allow them to accurately interpret complex documents and extract meaningful insights aligned with an insurer’s specific domain knowledge (such as property and casualty, healthcare, and so on) and corresponding guidelines. We provided a reference architecture that uses amazon Bedrock FMs and RAG capabilities using Knowledge Bases for amazon Bedrock, along with orchestration services such as Step Functions, that allow insurers to improve automation in key underwriting tasks like rules validation.
Additionally, you learned about how you can use AWS generative ai solutions to extract relevant information, compare it against defined rules, and flag any non-compliance issues automatically. You can use this innovative approach to improve underwriting efficiency, reduce processing times, minimize human error, achieve fairness and regulatory compliance, and improve transparency with applicants. We showed how insurers can adopt generative ai and amazon Bedrock to modernize their underwriting processes through intelligent document understanding and automation, gaining a competitive edge through mitigating risks more effectively.
Lastly, we offered a ai/tree/main” target=”_blank” rel=”noopener”>working solution with code you can deploy within your sandbox environment to accelerate the development of your own intelligent document understanding solution using AWS generative ai.
About the Authors
 Paul Min is a Solutions Architect at AWS, where he works with customers to advance their mission and accelerate their cloud adoption. He is passionate about helping customers reimagine what’s possible with generative ai on AWS. Outside of work, Paul enjoys spending time with his wife and golfing.
Paul Min is a Solutions Architect at AWS, where he works with customers to advance their mission and accelerate their cloud adoption. He is passionate about helping customers reimagine what’s possible with generative ai on AWS. Outside of work, Paul enjoys spending time with his wife and golfing.
 Alfredo Castillo is a Sr. Solutions Architect at AWS, where he works with Financial Services customers on all aspects of internet-scale distributed systems, and specializes in Machine learning, Natural Language Processing, Intelligent Document Processing, and GenAI. Alfredo has a background in both electrical engineering and computer science. He is passionate about family, technology, and endurance sports.
Alfredo Castillo is a Sr. Solutions Architect at AWS, where he works with Financial Services customers on all aspects of internet-scale distributed systems, and specializes in Machine learning, Natural Language Processing, Intelligent Document Processing, and GenAI. Alfredo has a background in both electrical engineering and computer science. He is passionate about family, technology, and endurance sports.
 Max Tybar is a Solutions Architect at AWS with a background in computer science and application development. He enjoys leveraging DevOps practices to architect and build reliable cloud infrastructure that helps solve customer problems. His personal interests lie around leveraging Machine Learning and High-Performance Computing to help solve complex problems faced by Financial Service customers in Banking, Capital Markets and Life Insurance.
Max Tybar is a Solutions Architect at AWS with a background in computer science and application development. He enjoys leveraging DevOps practices to architect and build reliable cloud infrastructure that helps solve customer problems. His personal interests lie around leveraging Machine Learning and High-Performance Computing to help solve complex problems faced by Financial Service customers in Banking, Capital Markets and Life Insurance.
 Raj Pathak is a Principal Solutions Architect and Technical advisor to Fortune 50 and Mid-Sized FSI (Banking, Insurance, Capital Markets) customers across Canada and the United States. Raj specializes in Machine Learning with applications in Generative ai, Natural Language Processing, Intelligent Document Processing, and MLOps.
Raj Pathak is a Principal Solutions Architect and Technical advisor to Fortune 50 and Mid-Sized FSI (Banking, Insurance, Capital Markets) customers across Canada and the United States. Raj specializes in Machine Learning with applications in Generative ai, Natural Language Processing, Intelligent Document Processing, and MLOps.






{kind=link}