 NEWSLETTER
NEWSLETTER
A critical challenge in artificial intelligence, specifically as it relates to large language models (LLMs), is balancing model performance and practical constraints such as privacy, cost, and device compatibility. While large cloud-based models offer high accuracy, their dependence on constant Internet connectivity, potential privacy violations, and high costs pose limitations. Furthermore, implementing these models on edge devices presents challenges in maintaining low latency and high accuracy due to hardware limitations.
Existing work includes models such as Gemma-2B, Gemma-7B and Llama-7B, as well as frameworks such as Llama cpp and MLC LLM, which aim to improve the efficiency and accessibility of ai. Projects like NexusRaven, Toolformer, and ToolAlpaca have advanced function calls in ai, striving for GPT-4-like efficiency. Techniques like LoRA have made it easier to tune under GPU limitations. However, these efforts often must face a crucial limitation: striking a balance between model size and operational efficiency, particularly for low-latency, high-precision applications on constrained devices.
Researchers at Stanford University have introduced Octopus v2, an advanced on-device language model aimed at addressing the prevalent latency, accuracy, and privacy issues associated with today's LLM applications. Unlike previous models, Octopus v2 significantly reduces latency and improves the accuracy of on-device applications. Its uniqueness lies in the fine-tuning method with functional tokens, which allows calling precise functions and surpassing GPT-4 in efficiency and speed, while drastically reducing the context length by 95%.
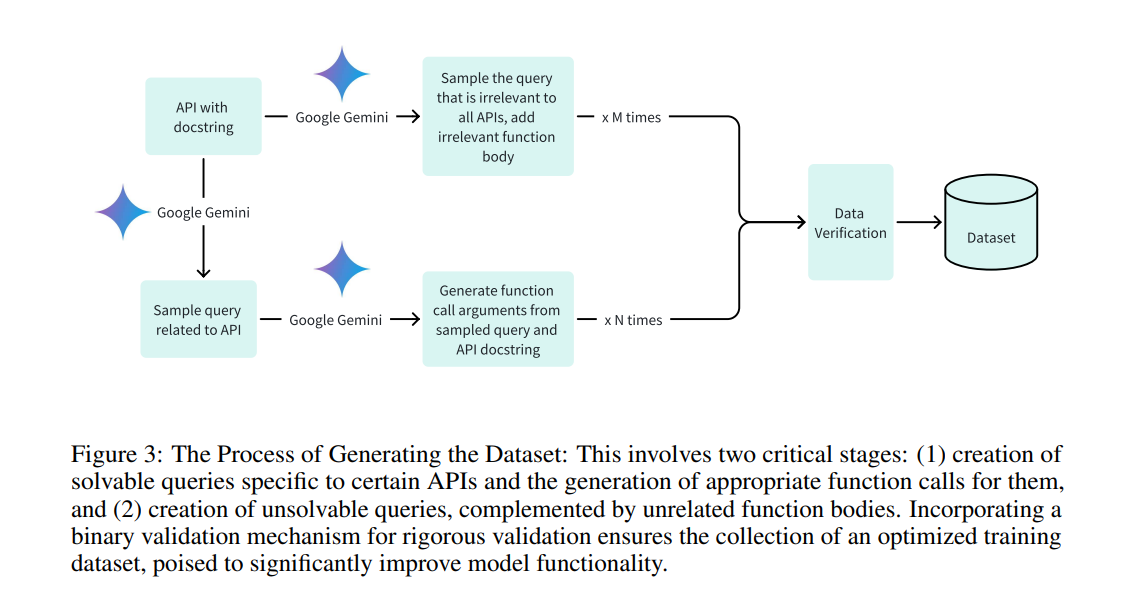
The methodology for Octopus v2 involved fitting a 2 billion parameter model derived from Google DeepMind's Gemma 2B on a custom dataset focused on Android API calls. This dataset was built with positive and negative examples to improve the accuracy of function calls. The training incorporated full model and low-rank adaptation (LoRA) techniques to optimize performance for execution on the device. The key innovation was the introduction of functional tokens during wrapping, which significantly reduced latency and context length requirements. This process allowed Octopus v2 to achieve high precision and efficiency in calling functions on edge devices without large computational resources.
In benchmark tests, Octopus v2 achieved an accuracy rate of 99.524% on function calling tasks, significantly outperforming GPT-4. The model also showed a dramatic reduction in response time, with latency minimized to 0.38 seconds per call, representing a 35x improvement compared to previous models. Additionally, it required 95% less context length for processing, demonstrating its efficiency in handling on-device operations. These metrics underscore Octopus v2's advancements in reducing operational demands while maintaining high performance levels, positioning it as a significant advancement in on-device language modeling technology.
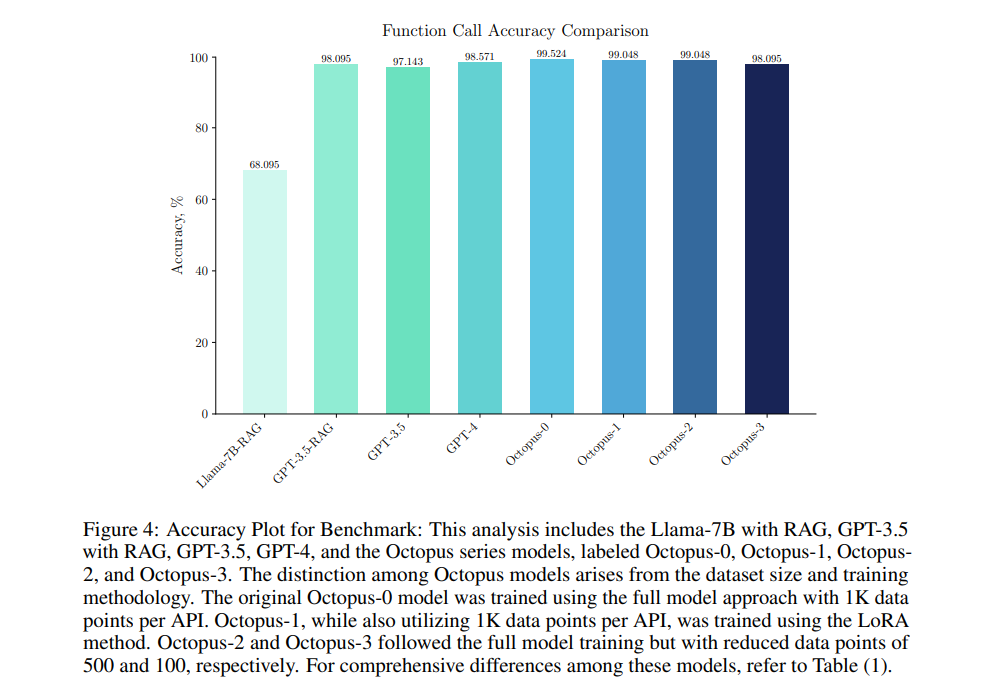
To conclude, researchers at Stanford University have shown that the development of Octopus v2 marks an important advance in language modeling on devices. By achieving high function call accuracy of 99.524% and reducing latency to just 0.38 seconds, Octopus v2 addresses key challenges in on-device ai performance. Its innovative wrapping approach with functional tokens dramatically reduces context length, improving operational efficiency. This research shows the technical merits of the model and its potential for broad real-world applications.
Review the Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter. Join our Telegram channel, Discord channeland LinkedIn Grabove.
If you like our work, you will love our Newsletter..
Don't forget to join our 39k+ ML SubReddit
![]()
Nikhil is an internal consultant at Marktechpost. He is pursuing an integrated double degree in Materials at the Indian Institute of technology Kharagpur. Nikhil is an ai/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in materials science, he is exploring new advances and creating opportunities to contribute.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}