 NEWSLETTER
NEWSLETTER
Augmented retrieval language models often retrieve only short fragments of a corpus, limiting the overall context of the document. This diminishes their ability to adapt to changes in the world state and incorporate long-tail knowledge. Existing augmented recovery approaches also need to be corrected. The problem we address is that most existing methods recover only a few short, contiguous text fragments, which limits their ability to represent and exploit large-scale discourse structure. This is particularly relevant for topical questions that require integrating knowledge from multiple parts of the text, such as understanding an entire book.
Recent developments in large language models (LLMs) demonstrate their effectiveness as independent knowledge stores, encoding facts within their parameters. Adjusting subsequent tasks further improves your performance. However, challenges arise in updating LLMs with evolving global knowledge. An alternative approach involves indexing text in an information retrieval system and presenting the retrieved information to LLMs to obtain current domain-specific knowledge. Existing augmented retrieval methods are limited to retrieving only short, contiguous text fragments, making it difficult to represent large-scale discourse structure, which is crucial for thematic questions and a comprehensive understanding of texts such as in the set of NarrativeQA data.
Stanford University researchers propose ABDUCTORan innovative indexing and retrieval system designed to address the limitations of existing methods. ABDUCTOR It uses a tree structure to capture high- and low-level details of a text. Group text fragments, generate group summaries, and build a tree from the bottom up. This structure allows different levels of text fragments to be loaded in the LLM context, facilitating efficient and effective answering of questions at various levels. The key contribution is the use of text summaries to increase recall, improving the representation of context at different scales, as demonstrated in experiments with large document collections.
ABDUCTOR addresses reading semantic depth and connection issues by constructing a recursive tree structure that captures both broad thematic understanding and granular details. The process involves segmenting the retrieval corpus into chunks, embedding them using SBERT, and clustering them with a soft clustering algorithm based on Gaussian Mixture Models (GMM) and Uniform Manifold Approximation and Projection (UMAP). The resulting tree structure allows efficient querying using a tree traversal or a collapsed tree approach, allowing the retrieval of relevant information at different levels of specificity.

ABDUCTOR Outperforms baseline methods on three question answering datasets: NarrativeQA, QASPER, and QuALITY. Control comparisons using UnifiedQA 3B as a reader show consistent superiority of ABDUCTOR about BM25 and DPR. Paired with GPT-4, RAPTOR achieves state-of-the-art results on QASPER and QuALITY datasets, demonstrating its effectiveness in handling multi-hop and topic queries. The contribution of the tree structure is validated, demonstrating the importance of higher-level nodes in capturing broader understanding and improving retrieval capabilities.

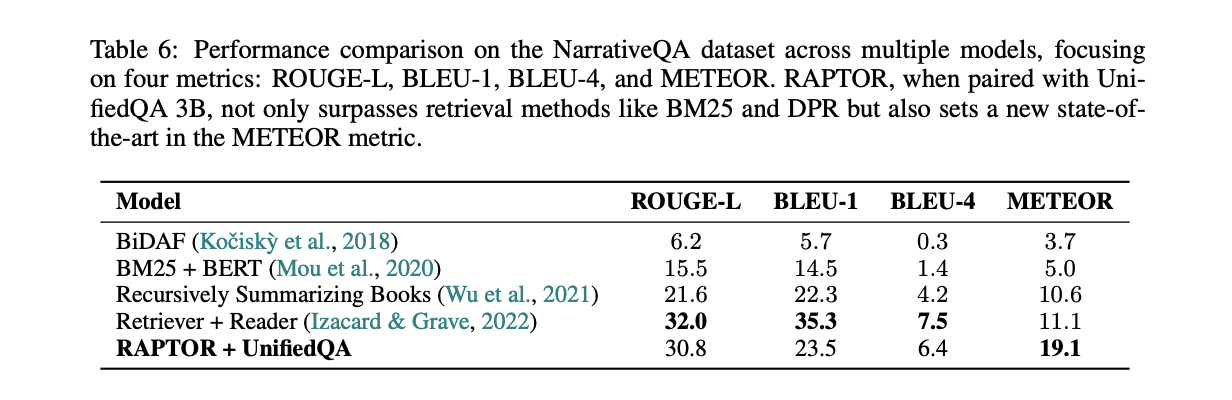
In conclusion, researchers at Stanford University present ABDUCTORan innovative tree-based retrieval system that improves the understanding of large language models with contextual information at different levels of abstraction. ABDUCTOR builds a hierarchical tree structure through recursive clustering and summarization, facilitating effective synthesis of information from various sections of retrieval corpus. Sample of controlled experiments ABDUCTOR superiority over traditional methods, establishing new benchmarks in various question answering tasks. In general, ABDUCTOR proves to be a promising approach to improve the capabilities of language models through improved contextual retrieval.
Review the Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on Twitter and Google news. Join our 36k+ ML SubReddit, 41k+ Facebook community, Discord Channeland LinkedIn Grabove.
If you like our work, you will love our Newsletter..
Don't forget to join our Telegram channel
![]()
Asjad is an internal consultant at Marktechpost. He is pursuing B.tech in Mechanical Engineering at Indian Institute of technology, Kharagpur. Asjad is a machine learning and deep learning enthusiast who is always researching applications of machine learning in healthcare.
<!– ai CONTENT END 2 –>






{kind=link}