 NEWSLETTER
NEWSLETTER
By improving the quality of learning in the context of smaller, open source models, more researchers and organizations can study and apply the technology. An exciting set of applications is in personal-private machine learning.
In contrast to designing perfect prompts through brute force guesswork and verification, “Ask Me Anything” (AMA) provides principled approaches and insights into prompt design: work shows how to study the corpus Pertinent and LLM training procedure can provide effective signals on how to format ads, and work aggregates the predictions of multiple ads using weak monitoring tools. Methods like AMA can help provide a starting point for LLM users dealing with the massive search space for natural language prompts.
Rapidly designing toward a “perfect indicator” for a task involves significant effort and is a difficult process…and often just plain frustrating.
This document describes a new AMA approach to application that leads to significantly higher performance for LLMs: This strategy allows the open source GPT-J-6B model to match and exceed the performance of the few-shot GPT3-175B in 15 of 20 popular landmarks. .
The AMA strategy message combines multiple imperfect messages with weak supervision to create predictions for the best entries, as described below.
The researcher really innovated and followed this 3-step process to come up with this approach:
- Identify the properties of indications that lead to the greatest effectiveness.
The research found that question-and-answer (QA) prompts that typically result in an open generation (“Who went to the park?”) had the highest performance.
They then created a two-step feedback pipeline: (1) generate questions based on the input, and (2) ask the LLM to answer the generated questions.
Finally, they generated and added multiple request outputs for each input.
- Develop a strategy to scalably format task inputs according to the most efficient request property.
Scaling step 1 above is not trivial. To do so, the researcher applied fast chaining. Specifically, the researcher recursively applied the LLM itself using a string of functional flags, called flagstrings(). These notices apply a task-independent operation to all inputs in the tasks, without any instance-level customization.
AMA builds different request() chains where each unique request() chain is a different view of the task and can emphasize different aspects. Chains also diversify through two key levers: in-context demos and the quick question style. See below for an example:

- Immediate aggregation.
For the first time, yes! For the first time, weak supervision was used to add prompts. Fast aggregation isn’t new, but weak monitoring applied to it is.
Weak monitoring…quick reminder: learn high-quality models from weaker signal sources without labeled data.
This was particularly powerful given the various precisions and dependencies between the request() strings and the fact that no tag data was required.
Results!
Impressive results according to the following table. These benchmark results compare the low-shot, open-source GPT-J-6B (k ∈ [32..70]) GPT3175B.
The number of in-context examples is in parentheses in the following table.
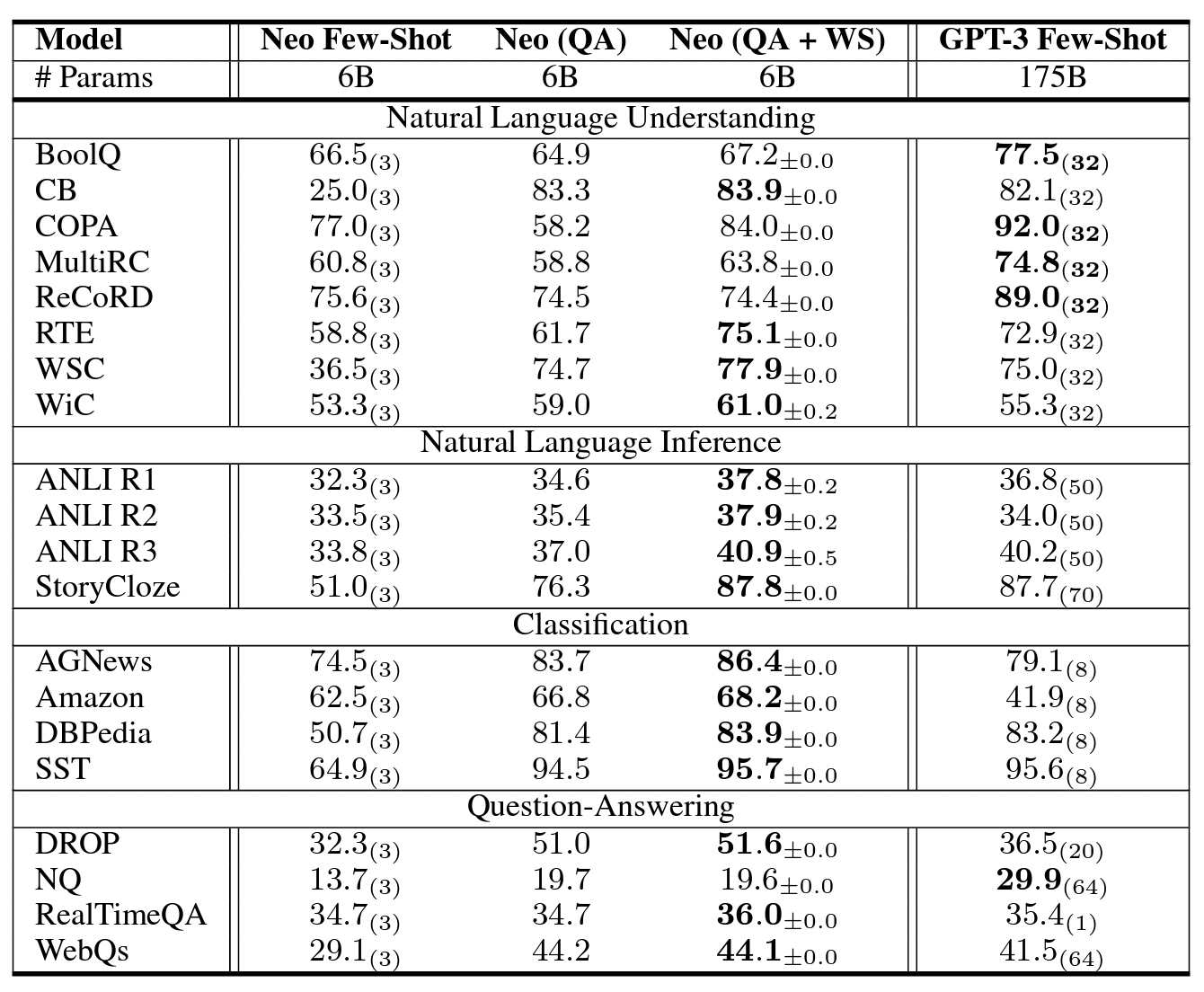
Open source 6B parameter model outperforms average low-shot performance of GPT3-175B model in 15 out of 20 benchmarks.
AMA Benefits:
- Using imperfect notices and enabling the use of small open source LLMs.
- Improve prompt performance of out-of-the-box language models without fine-tuning.
review the Paper and Github. All credit for this research goes to Simran AroraStanford researcher, and her collaborators Avanika, Mayee, and Laurel in nebulous research.

Jean-marc is a successful AI business executive. He leads and accelerates the growth of AI-powered solutions and started a computer vision company in 2006. He is a recognized speaker at AI conferences and has an MBA from Stanford.





{kind=link}