 NEWSLETTER
NEWSLETTER
The creation and formulation of a single, all-encompassing model capable of handling a variety of user-defined tasks has long been a field of interest in the field of artificial intelligence (AI) research. This has been particularly in Natural Language Processing (NLP) through “instruction tuning.” This method enables the model to competently carry out arbitrary instructions by improving a large language model (LLM) through exposure to a wide range of activities, and each articulated via natural language instructions.
One such example is the use of the Vision-Language Model. A “Vision-Language Model” (VLM) is a type of artificial intelligence that is proficient in understanding text and images as inputs. They can carry out various tasks involving visual and textual data interplay. They are used for image captioning, visual question answering, and creating textual descriptions of visual sceneries or translating between languages and visual representations.
Recently, the researchers of Stability AI announced the release of its first Japanese vision-language model, Japanese InstructBLIP Alpha. There have been many vision-language models, but this is the first to produce Japanese text descriptions. This new algorithm is intended to produce Japanese text descriptions for incoming photos and textual responses to image-related queries.
The researchers emphasized that the model can recognize specific Japanese landmarks. For uses ranging from robotics to tourism, this ability offers a layer of essential localized awareness. Additionally, the model can handle text and images, enabling more complicated queries based on visual inputs.
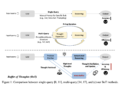
The researchers conducted thorough research to develop this model and used diverse instruction data to train this model. To connect the two, they trained the model with an image encoder, an LLM, and a Query Transformer (Q-Former). Additionally, they fine-tuned the Q-Former for instruction tuning while leaving the image encoder and LLM frozen.
Further, the researchers gathered 26 publicly available datasets, encompassing a broad range of functions and duties, and converted them into an instruction tuning format. The model was trained on 13 datasets and showed state-of-the-art zero-shot performance across all 13 held-out datasets. The researchers further emphasized that the model showed state-of-the-art performance when finetuned on individual downstream tasks. They also designed a Query Transformer that is instruction-aware and extracts informational elements specific to the particular instruction.
They put up the idea of “instruction-aware visual feature extraction,” which introduces a method that makes it possible to extract flexible and informative features in accordance with the given instructions. For the Q-Former to retrieve instruction-aware visual features from the frozen image encoder, the textual instruction is specifically sent to both the frozen LLM and the Q-Former. They also performed a balanced sampling technique to synchronize learning progress across datasets.
The researchers warn users to be aware of potential biases and limits at this point despite the utility and effectiveness of the model. They added a warning that, like any other AI system, responses must be judged for accuracy and appropriateness using human judgement. The model’s performance in Japanese vision-language tasks must be improved through continued research and development.
Check out the Project. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
Rachit Ranjan is a consulting intern at MarktechPost . He is currently pursuing his B.Tech from Indian Institute of Technology(IIT) Patna . He is actively shaping his career in the field of Artificial Intelligence and Data Science and is passionate and dedicated for exploring these fields.
 The end of project management by humans (Sponsored)
The end of project management by humans (Sponsored) 



{kind=link}