 NEWSLETTER
NEWSLETTER
Large models of vision and language have emerged as powerful tools for multimodal understanding, demonstrating impressive capabilities for interpreting and generating content that combines visual and textual information. These models, such as LLaVA and its variants, fit large language models (LLMs) on visual instruction data to perform complex vision tasks. However, developing high-quality visual instruction datasets presents significant challenges. These data sets require various images and texts from various tasks to generate various questions, covering areas such as object detection, visual reasoning, and image captioning. The quality and diversity of these data sets directly impacts model performance, as demonstrated by LLaVA's substantial improvements over previous state-of-the-art methods on tasks such as GQA and VizWiz. Despite these advances, current models face limitations due to the modality gap between pretrained vision encoders and language models, which restricts their ability to generalize and feature representation.
Researchers have made significant progress in addressing the challenges of vision and language models through various approaches. Instruction tuning has become a key methodology that allows LLMs to interpret and execute human language instructions in various tasks. This approach has evolved from closed-domain instruction tuning, which uses publicly available data sets, to open-domain instruction tuning, which uses real-world question-and-answer data sets to improve model performance in scenarios. of authentic users.
In vision-language integration, methods such as LLaVA have been pioneers in combining LLM with CLIP vision encoders, demonstrating notable capabilities in image-text dialogue tasks. Subsequent research has focused on refining the tuning of visual instruction by improving the quality and variety of the data set during the pretraining and tuning phases. Models such as LLaVA-v1.5 and ShareGPT4V have achieved notable success in general vision and language understanding, demonstrating their ability to handle complex question answering tasks.
These advances highlight the importance of sophisticated data management and model tuning strategies in developing effective vision and language models. However, challenges remain in bridging the modality gap between the vision and language domains, requiring continued innovation in model architecture and training methodologies.
Researchers from Rochester Institute of technology and Salesforce ai Research propose a unique framework, SQ-LLAVA based on a visual self-questioning approachimplemented in a model called SQ-LLaVA (Self-Questioning LLaVA). This method aims to improve visual language understanding by training the LLM to ask questions and discover visual clues without requiring additional external data. Unlike existing visual instruction fitting methods that mainly focus on response prediction, SQ-LLaVA extracts the context of relevant questions from images.
The approach is based on the observation that questions often contain more image-related information than answers, as demonstrated by the higher CLIPS scores for image-question pairs compared to image-answer pairs in existing data sets. . Using this information, SQ-LLaVA uses questions within the instructional data as an additional learning resource, effectively enhancing the curiosity and questioning ability of the model.
To efficiently align the vision and language domains, SQ-LLaVA employs low-range adaptations (LoRA) to optimize both the vision encoder and the instructional LLM. Furthermore, a prototype extractor is developed to improve visual representation by utilizing learned clusters with meaningful semantic information. This comprehensive approach aims to improve vision-language alignment and overall performance on various visual understanding tasks without the need to collect new data or extensive computational resources.
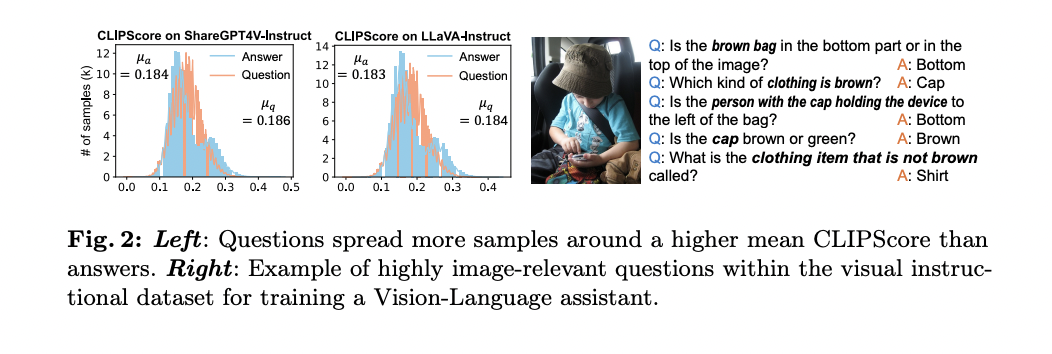
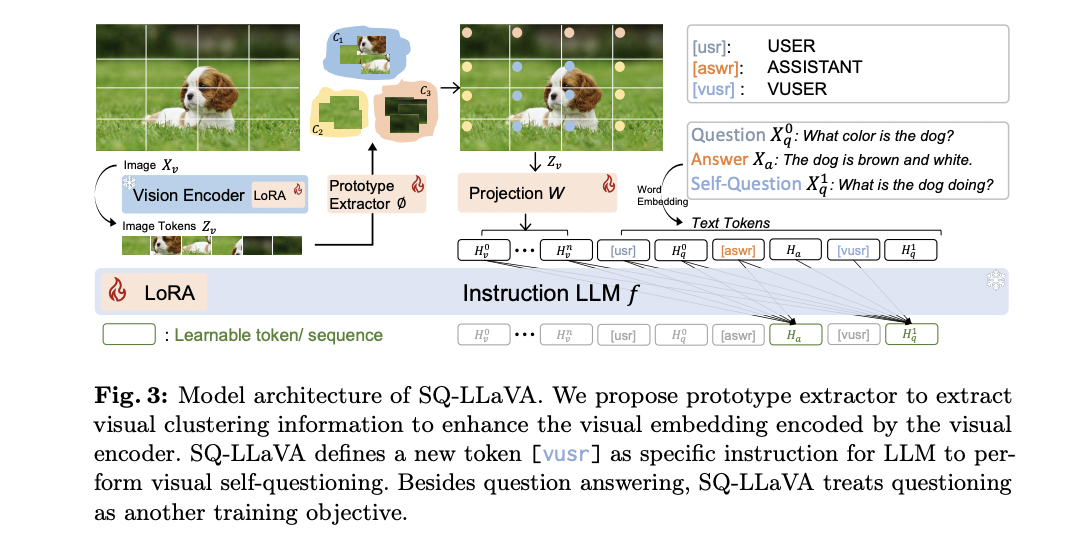
The architecture of the SQ-LLaVA model consists of four main components designed to improve visual language understanding. In essence, there is a pre-trained CLIP-ViT vision encoder that extracts embeddings from input image sequences. This is complemented by a robust prototype extractor that learns visual clusters to enrich the original image tokens, improving the model's ability to recognize and cluster similar visual patterns.
A trainable projection block, consisting of two linear layers, maps the enhanced image tokens to the language domain, addressing the dimension mismatch between visual and linguistic representations. The backbone of the model is a pre-trained Vicuña LLM, which predicts subsequent tokens based on the previous embedding sequence.
The model introduces a visual self-questioning approach, using a unique token (vusr) to instruct the LLM to generate questions about the image. This process is designed to utilize the rich semantic information that is often present in questions, potentially surpassing that of answers. The architecture also includes an enhanced visual representation component featuring a prototype extractor that uses clustering techniques to capture representational semantics in the latent space. This extractor iteratively updates cluster mappings and centers, adaptively mapping visual cluster information to raw image embeddings.
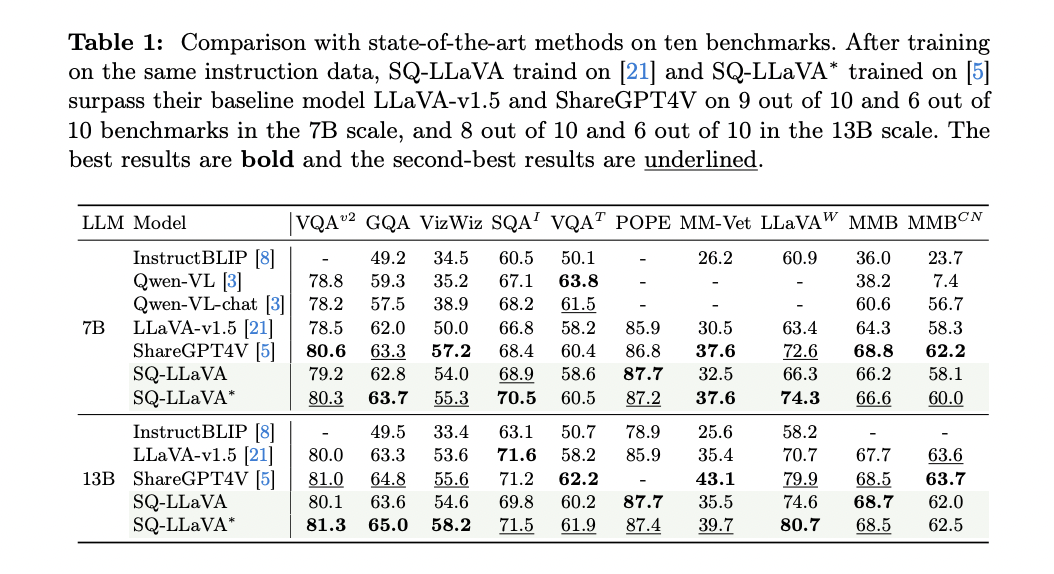
The researchers evaluated SQ-LLaVA on a comprehensive set of ten visual question-answering benchmarks, covering a wide range of tasks, from academic VQA to instruction-matching tasks designed for large models of vision and language. The model demonstrated significant improvements over existing methods in several key areas:
1. Performance: SQ-LLaVA-7B and SQ-LLaVA-13B outperformed the previous methods in six out of ten visual instruction adjustment tasks. In particular, SQ-LLaVA-7B achieved a 17.2% improvement over LLaVA-v1.5-7B on the LLaVA (in the wild) benchmark, indicating superior capabilities in detailed description and complex reasoning.
2. Scientific Reasoning: The model showed improved performance in ScienceQA, suggesting strong capabilities in multi-hop reasoning and understanding of complex scientific concepts.
3. Reliability: SQ-LLaVA-7B demonstrated a 2% and 1% improvement over LLaVA-v1.5-7B and ShareGPT4V-7B on the POPE benchmark, indicating better reliability and reduced hallucinations of objects.
4. Scalability: SQ-LLaVA-13B outperformed previous work on six out of ten benchmarks, demonstrating the effectiveness of the method with larger language models.
5. Visual information discovery: The model showed advanced capabilities in detailed image description, visual information summary, and visual self-questioning. It generated diverse and meaningful questions about given images without requiring human textual instructions.
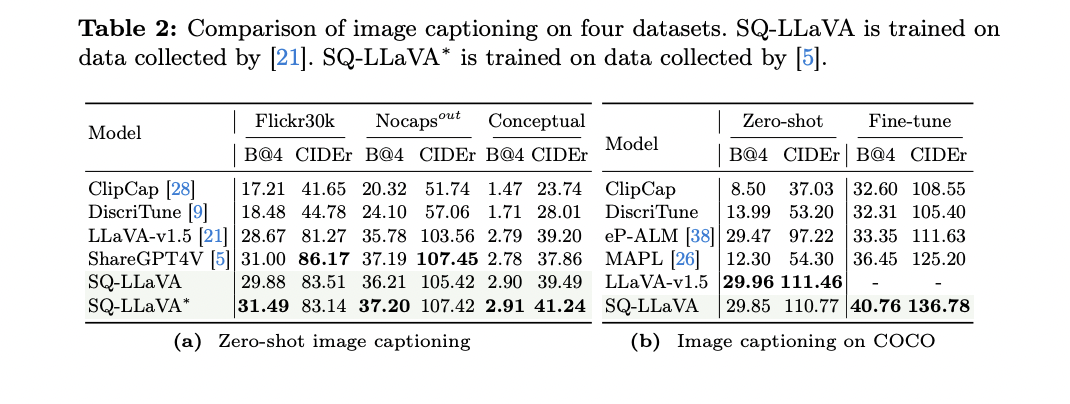
6. Non-shot image captioning: SQ-LLaVA achieved significant improvements over benchmark models such as ClipCap and DiscriTune, with an average improvement of 73% and 66% across all data sets.
These results were achieved with significantly fewer trainable parameters compared to other methods, highlighting the efficiency of the SQ-LLaVA approach. The model's ability to generate diverse questions and provide detailed descriptions of images demonstrates its potential as a powerful tool for the discovery and understanding of visual information.


SQ-LLAVA presents a unique method of visual instruction adjustment that improves vision and language understanding through self-questioning. The approach achieves superior performance with fewer parameters and less data on multiple benchmarks. It demonstrates improved generalization to unseen tasks, reduces object hallucination, and improves semantic image interpretation. By framing questioning as an intrinsic goal, SQ-LLaVA explores model curiosity and proactive question-asking skills. This research highlights the potential of visual self-questioning as a powerful training strategy, paving the way for more efficient and effective large vision and language models capable of tackling complex problems in diverse domains.
look at the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter and join our Telegram channel and LinkedIn Grabove. If you like our work, you will love our information sheet.. Don't forget to join our SubReddit over 50,000ml
(Next Event: Oct 17, 202) RetrieveX – The GenAI Data Recovery Conference (Promoted)
Asjad is an internal consultant at Marktechpost. He is pursuing B.tech in Mechanical Engineering from Indian Institute of technology, Kharagpur. Asjad is a machine learning and deep learning enthusiast who is always researching applications of machine learning in healthcare.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}