 NEWSLETTER
NEWSLETTER
Jackie Rocca, vice president of product and artificial intelligence at Slack, is a co-author of this post.
Slack is where the work happens. It is the ai-powered work platform that connects people, conversations, applications and systems in one place. With the newly released ai” target=”_blank” rel=”noopener”>weak ai—a generative, native, and trusted artificial intelligence (ai) experience available directly in Slack—users can discover and prioritize information so they can find their focus and do their most productive work.
We're excited to announce that Slack, a Salesforce company, has collaborated with amazon SageMaker JumpStart to power Slack ai's initial search and summary capabilities and provide protection for Slack to more securely use large language models (LLMs). Slack worked with SageMaker JumpStart to host LLM from industry-leading third parties so that data is not shared with infrastructure owned by third-party model providers.
This keeps customer data in Slack at all times and maintains the same security practices and compliance standards that customers expect from Slack itself. Slack also uses amazon SageMaker inference capabilities for advanced routing strategies to scale the solution to customers with optimal throughput, latency, and throughput.
“With amazon SageMaker JumpStart, Slack can access next-generation foundation models to power Slack ai, while prioritizing security and privacy. “Slack customers can now search smarter, instantly summarize conversations, and be more productive.”
– Jackie Rocca, VP of Product, ai at Slack
Foundation Models in SageMaker JumpStart
SageMaker JumpStart is a machine learning (ML) hub that can help you accelerate your ML journey. With SageMaker JumpStart, you can quickly evaluate, compare, and select base models (FMs) based on predefined quality and accountability metrics to perform tasks such as article summarization and image generation. Pre-trained models are fully customizable for your use case with your data and you can effortlessly deploy them to production with the UI or SDK. Additionally, you can access pre-built solutions to solve common use cases and share ML artifacts, including ML models and notebooks, within your organization to accelerate the creation and deployment of ML models. None of your data is used to train the underlying models. All data is encrypted and never shared with third-party providers, so you can trust that your data will remain private and confidential.
See the SageMaker JumpStart models page for available models.
weak ai
Slack launched Slack ai to provide native generative ai capabilities so customers can easily find and consume large volumes of information quickly, allowing them to get even more value from their shared knowledge in Slack. For example, users can ask a question in plain language and instantly get clear, concise answers with improved search. They can catch up on channels and threads with a single click with conversation summaries. And they can access personalized daily summaries of what's happening on select channels with the newly launched summaries.
Because trust is Slack's most important value, Slack ai runs on enterprise-grade infrastructure they built on AWS, maintaining the same security practices and compliance standards that customers expect. Slack ai is designed for security-conscious customers and is designed to be secure by design: customer data remains internal, data is not used for LLM training purposes, and data remains isolated.
Solution Overview
SageMaker JumpStart provides access to many LLMs and Slack selects the appropriate FMs that fit your use cases. Because these models are hosted on Slack's proprietary AWS infrastructure, data sent to the models during the invocation does not leave Slack's AWS infrastructure. Additionally, to provide a secure solution, data sent to invoke SageMaker models is encrypted in transit. Data sent to SageMaker JumpStart endpoints to invoke models is not used to train base models. SageMaker JumpStart enables Slack to support high standards of security and data privacy, while using next-generation models that help Slack ai perform optimally for Slack customers.
SageMaker JumpStart endpoints serving Slack business applications are powered by AWS instances. SageMaker supports a wide range of instance types for model deployment, allowing Slack to choose the instance that best meets the latency and scalability requirements of Slack's ai use cases. Slack ai has access to multi-GPU based instances to host your SageMaker JumpStart models. Multiple GPU instances allow each instance supporting the Slack ai endpoint to host multiple copies of a model. This helps improve resource utilization and reduce the cost of model implementation. For more information, see amazon SageMaker adds new inference capabilities to help reduce latency and deployment costs of the base model.
The following diagram illustrates the architecture of the solution.
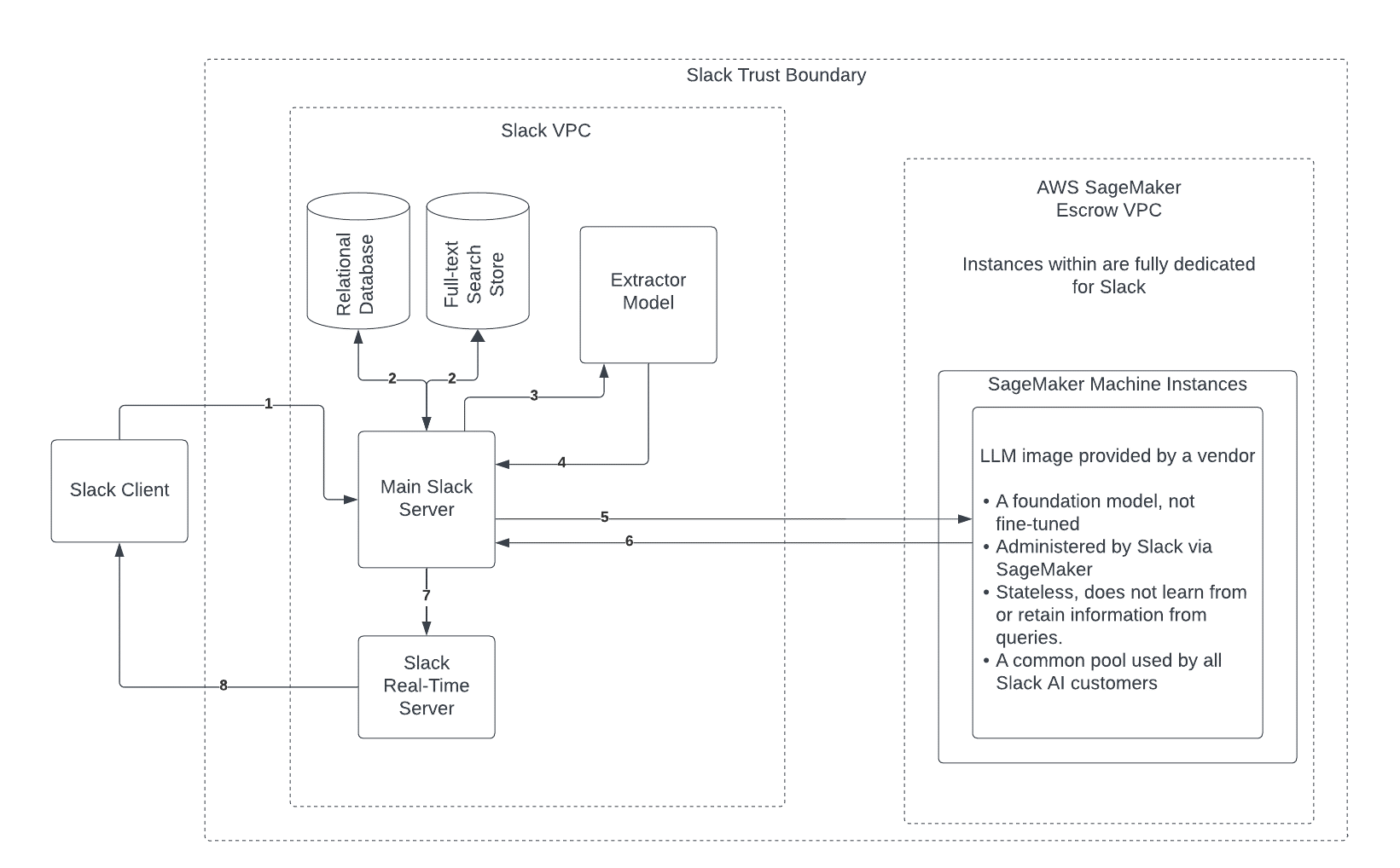
To use instances more effectively and support concurrency and latency requirements, Slack used routing strategies offered by SageMaker with its SageMaker endpoints. By default, a SageMaker endpoint evenly distributes incoming requests to ML instances using a round-robin algorithm routing strategy called RANDOM. However, with generative ai workloads, requests and responses can be extremely variable, and it is desirable to balance the load considering instance capacity and utilization rather than random load balancing. To efficiently distribute requests between instances supporting endpoints, Slack uses the LEAST_OUTSTANDING_REQUESTS (LAR) routing strategy. This strategy routes requests to specific instances that have more capacity to process requests rather than randomly selecting any available instance. The LAR strategy provides more consistent load balancing and resource utilization. As a result, Slack ai saw a latency drop of over 39% in its p95 latency numbers when enabling LEAST_OUTSTANDING_REQUESTS compared to RANDOM.
For more details about SageMaker routing strategies, see Minimize real-time inference latency using amazon SageMaker routing strategies.
Conclusion
Slack offers native generative ai capabilities that will help your customers be more productive and easily leverage the collective knowledge embedded in their Slack conversations. With quick access to a large selection of FMs and advanced load balancing capabilities hosted on dedicated instances via SageMaker JumpStart, Slack ai can deliver rich generative ai capabilities in a more robust and faster way, while maintaining industry standards. Slack trust and security.
Learn more about SageMaker JumpStart, ai“>weak ai and ai-to-be-secure-and-private/”>how the Slack team built Slack ai to be secure and private. Leave your thoughts and questions in the comments section.
About the authors
 Jackie Rocca She is Vice President of Product at Slack, where she oversees the vision and execution of Slack ai, which natively and securely brings generative ai to the Slack user experience. She is now on a mission to help customers accelerate their productivity and get even more value from their conversations, data, and collective knowledge with generative ai. Prior to working at Slack, Jackie was a product manager at Google for over six years, where she helped launch and grow YouTube TV. Jackie is based in the San Francisco Bay area.
Jackie Rocca She is Vice President of Product at Slack, where she oversees the vision and execution of Slack ai, which natively and securely brings generative ai to the Slack user experience. She is now on a mission to help customers accelerate their productivity and get even more value from their conversations, data, and collective knowledge with generative ai. Prior to working at Slack, Jackie was a product manager at Google for over six years, where she helped launch and grow YouTube TV. Jackie is based in the San Francisco Bay area.
 Rachna Chadha is a Principal ai/ML Solutions Architect in Strategic Accounts at AWS. Rachna is an optimist who believes that the ethical and responsible use of ai can improve society in the future and generate economic and social prosperity. In her free time, Rachna enjoys spending time with her family, hiking, and listening to music.
Rachna Chadha is a Principal ai/ML Solutions Architect in Strategic Accounts at AWS. Rachna is an optimist who believes that the ethical and responsible use of ai can improve society in the future and generate economic and social prosperity. In her free time, Rachna enjoys spending time with her family, hiking, and listening to music.
 marc karp is a machine learning architect on the amazon SageMaker service team. He focuses on helping customers design, deploy, and manage machine learning workloads at scale. In his free time he likes to travel and explore new places.
marc karp is a machine learning architect on the amazon SageMaker service team. He focuses on helping customers design, deploy, and manage machine learning workloads at scale. In his free time he likes to travel and explore new places.
 Maninder (Mani) Kaur is the leading ai/ML specialist for strategic ISVs on AWS. With his customer-first approach, Mani helps strategic clients shape their ai/ML strategy, drive innovation, and accelerate their ai/ML journey. Mani strongly believes in ethical and responsible ai, and strives to ensure that his clients' ai solutions align with these principles.
Maninder (Mani) Kaur is the leading ai/ML specialist for strategic ISVs on AWS. With his customer-first approach, Mani helps strategic clients shape their ai/ML strategy, drive innovation, and accelerate their ai/ML journey. Mani strongly believes in ethical and responsible ai, and strives to ensure that his clients' ai solutions align with these principles.
 gene ting He is a Principal Solutions Architect at AWS. His goal is to help enterprise customers securely build and operate workloads on AWS. In his spare time, Gene enjoys teaching kids technology and sports, as well as following the latest news in cybersecurity.
gene ting He is a Principal Solutions Architect at AWS. His goal is to help enterprise customers securely build and operate workloads on AWS. In his spare time, Gene enjoys teaching kids technology and sports, as well as following the latest news in cybersecurity.
 Alan Tan is a Senior Product Manager at SageMaker and leads efforts in large model inference. She is passionate about applying machine learning to the area of analytics. Outside of work, she enjoys the outdoors.
Alan Tan is a Senior Product Manager at SageMaker and leads efforts in large model inference. She is passionate about applying machine learning to the area of analytics. Outside of work, she enjoys the outdoors.






{kind=link}