 NEWSLETTER
NEWSLETTER
The development of large language models (LLM) has been a focal point in advancing NLP capabilities. However, training these models poses substantial challenges due to the immense computational resources and costs involved. Researchers continually explore more efficient methods to manage these demands while maintaining high performance.
A critical issue in LLM development is the extensive resources required to train dense models. Dense models turn on all parameters for each input token, resulting in significant inefficiencies. This approach makes it difficult to scale up without incurring prohibitive costs. Consequently, there is a pressing need for more resource-efficient training methods that can still deliver competitive performance. The main goal is to balance computational feasibility and the ability to handle complex NLP tasks effectively.
Traditionally, LLM training has been based on dense and resource-intensive models despite their high performance. These models require the activation of all parameters for each token, which generates a substantial computational load. Sparse models, such as Mixture of Experts (MoE), have emerged as a promising alternative. MoE models distribute computational tasks among several specialized submodels or “experts.” This approach can match or exceed the performance of dense models using a fraction of the resources. The efficiency of MoE models lies in their ability to selectively activate only a subset of experts for each token, thus optimizing resource usage.
The research team Skywork Team, Kunlun Inc. is introduced. Skywork-MoE, a high-performance MoE large language model with 146 billion parameters and 16 experts. This model is based on the fundamental architecture of its previously developed Skywork-13B model, using its dense control points as the initial configuration. He Skywork-MoE It incorporates two novel training techniques: activation logit normalization and adaptive auxiliary loss coefficients. These innovations are designed to improve model efficiency and performance. By leveraging dense checkpoints, the model benefits from pre-existing data, which helps in the initial setup and subsequent training phases.
Skywork-MoE was trained using dense checkpoints from the Skywork-13B model, initialized from pre-trained dense models for 3.2 billion tokens, and further trained with an additional 2 billion tokens. The input logit normalization technique ensures a distinct distribution of output at the gate, which improves export diversification. This method involves normalizing the outputs of the activation layer before applying the softmax function, which helps achieve a sharper and more focused distribution. Adaptive auxiliary loss coefficients allow for specific tuning of each layer, maintaining a balanced load between experts and preventing a single expert from being overloaded. These adjustments are based on monitoring the token drop rate and adapting the coefficients accordingly.
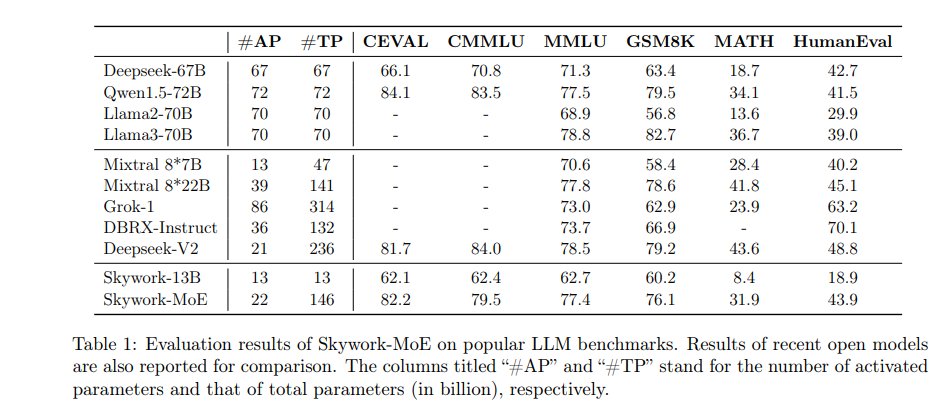
The performance of Skywork-MoE was evaluated across a variety of benchmarks. The model scored 82.2 on the CEVAL benchmark and 79.5 on the CMMLU benchmark, outperforming the Deepseek-67B model. The MMLU benchmark scored 77.4, which is competitive compared to higher capacity models like the Qwen1.5-72B. For mathematical reasoning tasks, Skywork-MoE scored 76.1 on GSM8K and 31.9 on MATH, comfortably outperforming models like Llama2-70B and Mixtral 8*7B. Skywork-MoE demonstrated strong performance on code synthesis tasks with a score of 43.9 on the HumanEval benchmark, outperforming all dense models in the comparison and slightly lagging behind the Deepseek-V2 model. These results highlight the model's ability to effectively handle complex logical and quantitative reasoning tasks.
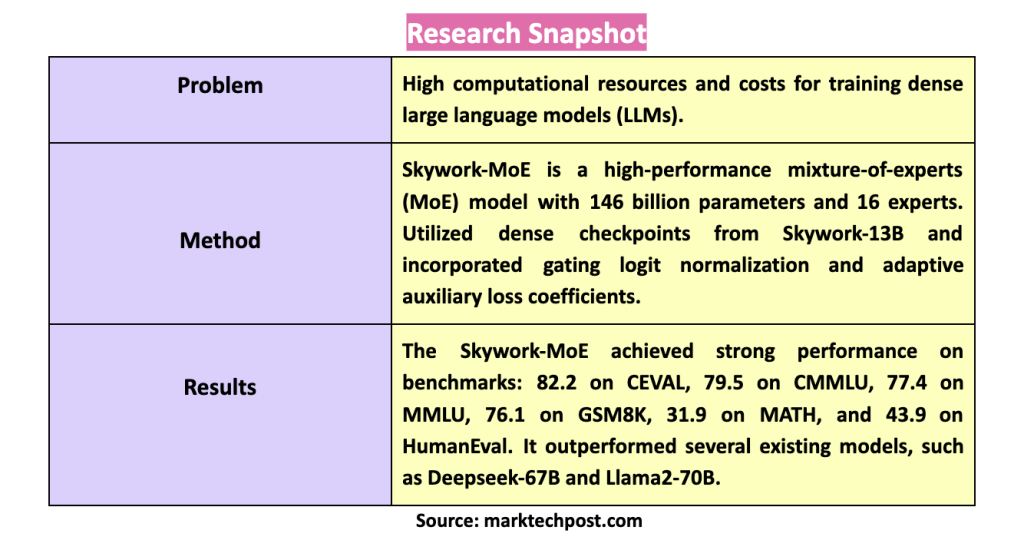
In conclusion, the Skywork team research team successfully addressed the resource-intensive issue of LLM training by developing tech-report.pdf”>Skywork-MoE, which leverages innovative techniques to improve performance while reducing computational demands. Skywork-MoE, with its 146 billion parameters and advanced training methodologies, represents a significant advancement in the field of NLP. The strong performance of the model on several benchmarks underlines the effectiveness of activation logit normalization techniques and adaptive auxiliary loss coefficients. This research competes well with existing models and sets a new benchmark for the efficiency and effectiveness of MoE models in large-scale language processing tasks.
![]()
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of artificial intelligence for social good. His most recent endeavor is the launch of an ai media platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is technically sound and easily understandable to a wide audience. The platform has more than 2 million monthly visits, which illustrates its popularity among the public.






{kind=link}