 NEWSLETTER
NEWSLETTER
Stable diffusion 1.5/2.0/2.1/XL 1.0, Dall-e, image … In recent years, diffusion models have shown impressive quality in the generation of images. However, although they produce great quality in generic concepts, they struggle to generate high quality for more specialized consultations, for example, generate images in a specific style, which was not frequently seen in the training data set.
We could return to train the entire model in a large number of images, explaining the necessary concepts to address the problem from scratch. However, this does not sound practical. First, we need a large set of images for the idea, and second, it is simply too expensive and slow.
However, there are solutions that, given a handful of images and an hour of adjustment in the worst case, would allow diffusion models to produce reasonable quality in the new concepts.
Then, I cover approaches such as Dreambeh, Lora, Hyper-Networks, textual investment, IP adapters and controls widely used to customize and condition diffusion models. The idea behind all these methods is to memorize a new concept that we are trying to learn, however, each technique addresses it differently.
Diffusion architecture
Before immersing yourself in several methods that help condition dissemination models, let's first recapitulate what the diffusion models are.
The original idea of diffusion models is to train a model to rebuild a coherent image of noise. In the training stage, we gradually add small amounts of Gaussian noise (forward process) and then rebuild the image iteratively optimizing the model to predict the noise, subtracting that we would approach the destination image (reverse process).
The original idea of image corruption has evolved in a more practical and light architecture in which the images are first compressed to a latent space, and all additional noise manipulation is performed in a low dimension space.
To add textual information to the diffusion model, we first pass it through a text encoder (usually SHORTEN) to produce a latent embeddation, which is then injected into the model with cross attention layers.
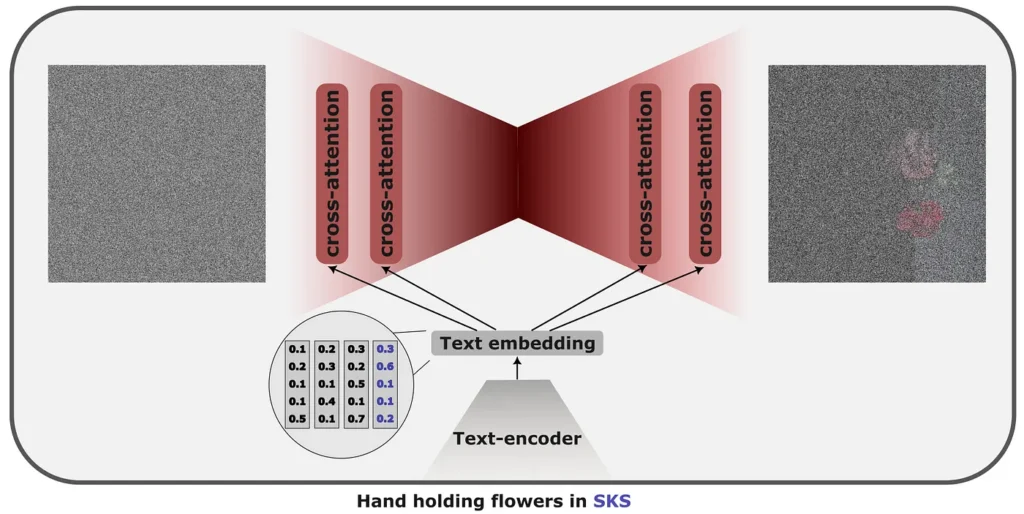
The idea is to take a rare word; In general, a word {SKS} is used and then teach the model to assign the word {SKS} to a characteristic that we would like to learn. That could, for example, be a style that the model has never seen, as Gogh. We would show a dozen of her paintings and dye to the phrase “A paint of boots in the {SKS}” style. Similarly, we could customize the generation, for example, learn to generate images of a particular person, for example, “{SKS} in the mountains” in a set of selfies of one.
To maintain the information learned in the stage prior to the training, Dreambeh encourages the model not to deviate too much from the original previously trained version by adding text image pairs generated by the original model to the fine adjustment set.
When to use and when not
Dreambooth produces the best quality in all methods; However, the technique could affect the concepts already learned since the entire model is updated. The training program also limits the amount of concepts that the model can understand. The training takes a long time, taking 1 to 2 hours. If we decide to introduce several new concepts at the same time, we would need to store two model control points, which wasted a lot of space.
Textual investment, paper, code
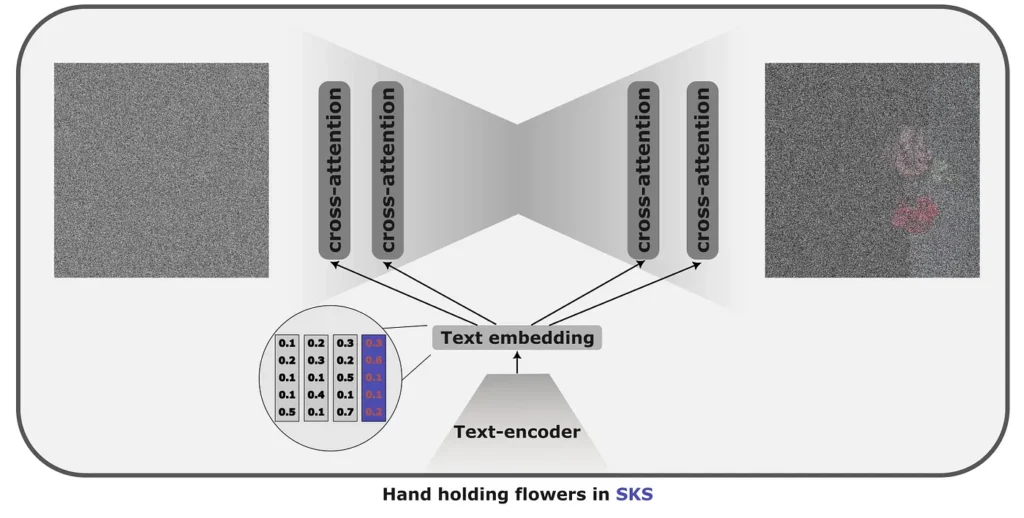
The assumption behind textual investment is that the knowledge stored in the latent space of the diffusion models is vast. Therefore, the style or condition that we want to reproduce with the diffusion model is already known by him, but we simply do not have the token to access it. Therefore, instead of adjusting the model to reproduce the desired output when it is fed with rare words “in the {SKS}” style, we are optimizing for a textual inlays that would result in the desired output.
When to use and when not
Very little space is needed, since only the token will be stored. It is also relatively fast to train, with an average training time of 20-30 minutes. However, it comes with its deficiencies, since we are adjusting a specific vector that guides the model to produce a particular style, it will not become beyond this style.
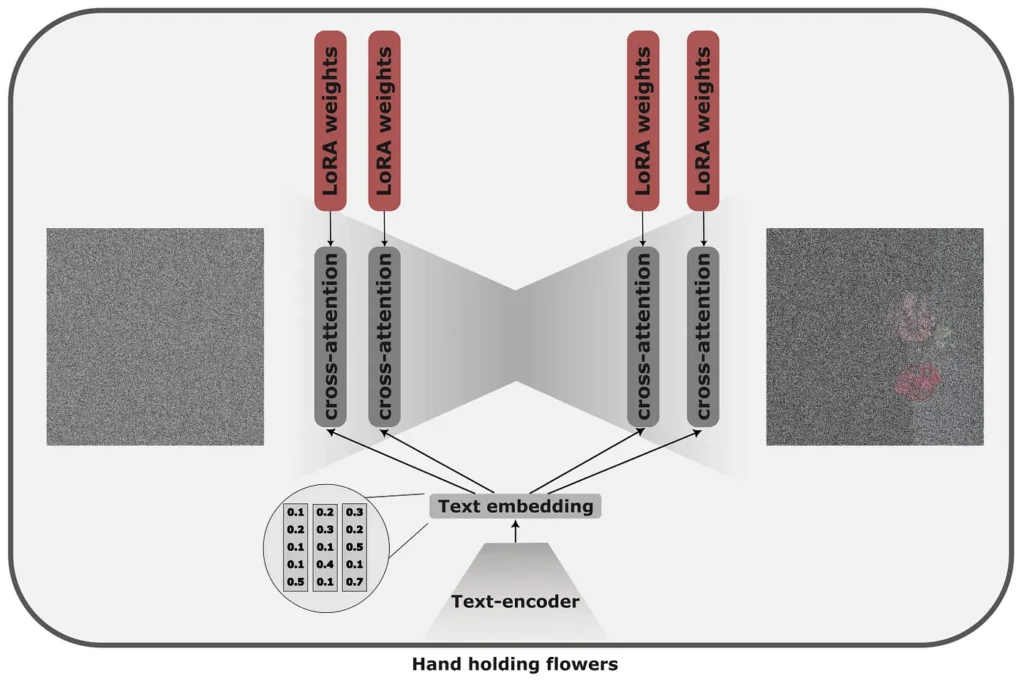
Low rank (LORA) adaptations were proposed for large language models and were First adapted to the dissemination model by Simo Ryu. The original idea of Loras is that instead of adjusting the entire model, which can be quite expensive, we can combine a fraction of new weights that would adjust for the task with a similar token approach in the original model.
In diffusion models, rank decomposition applies to cross -care layers and is responsible for fusing fast information and image. The weight matrices WO, WQ, WK and WV in these layers have applied Lora.
When to use and when not
Loras takes very little time to train (5–15 minutes): We are updating a handful of parameters compared to the entire model, already a difference from Dreambeh, they take much less space. However, small models in fine size with Loras are worse of quality compared to Dreambooth.
Hyper -networks, paper, code
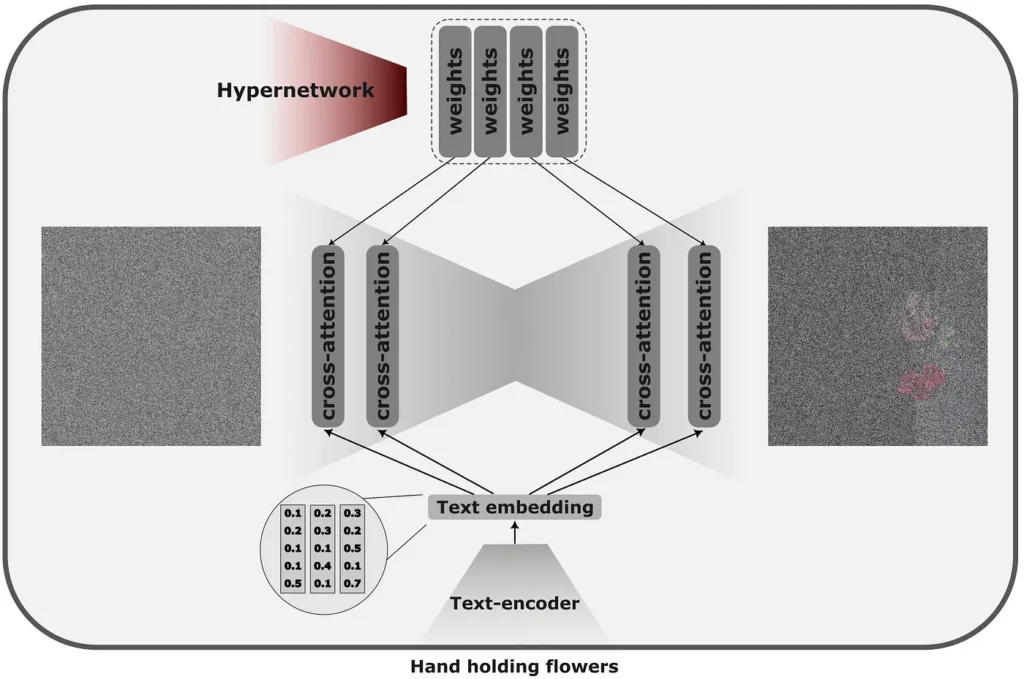
Hyper-Networks are, in a sense, extensions to Loras. Instead of learning the relatively small inlays that would directly alter the exit of the model, we train a separate network capable of predicting the weights for these recently injected incrustations.
Make the model predict the inlays for a specific concept, we can teach hypernetwork several concepts, reusing the same model for multiple tasks.
When to use and not
Hypernworks, who does not specialize in a single style, but capable of producing plethora generally do not result in such good quality as the other methods and can take significant time to train. On the side of the pros, they can store many more concepts than other unique concept adjustment methods.
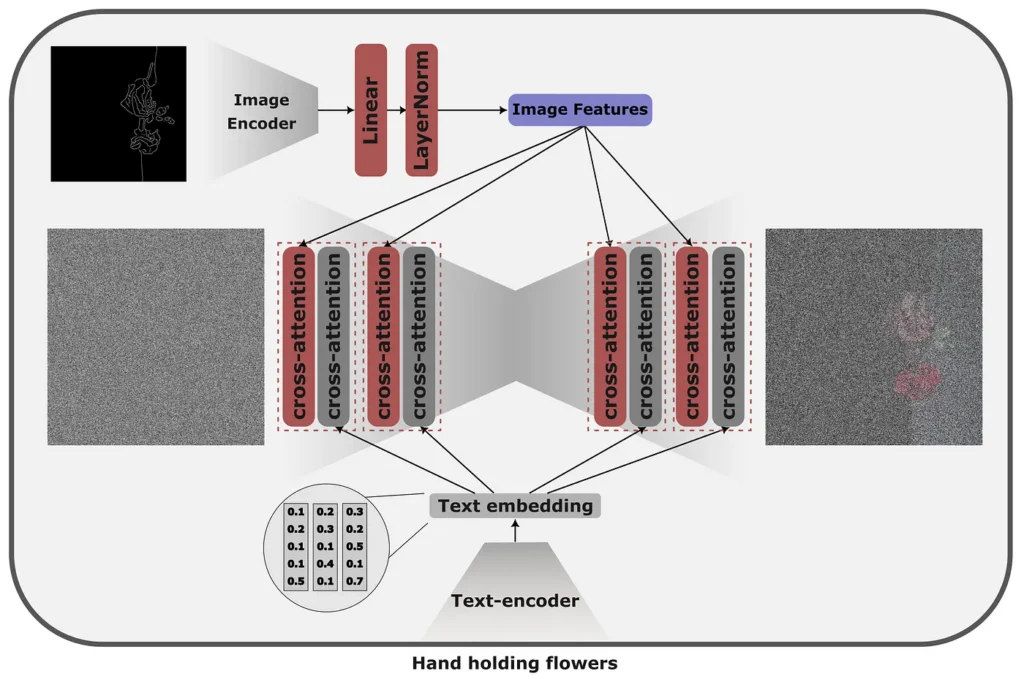
Instead of controlling the generation of images with text indications, IP adapters propose a method to control the generation with an image without any change in the underlying model.
The central idea behind the IP adapter is a decoupled cross attention mechanism that allows the combination of images of origin with text and image characteristics generated. This is achieved by adding a separate cross attention layer, allowing the model to learn specific characteristics of the image.
When to use and not
IP adapters are light, adaptable and fast. However, its performance depends largely on the quality and diversity of training data. IP adapters generally tend to work better with the supply of stylistic attributes (for example, with an image of Mark Chagall's paintings) that we would like to see in the image generated and we could have difficulty providing control for exact details, as pose.
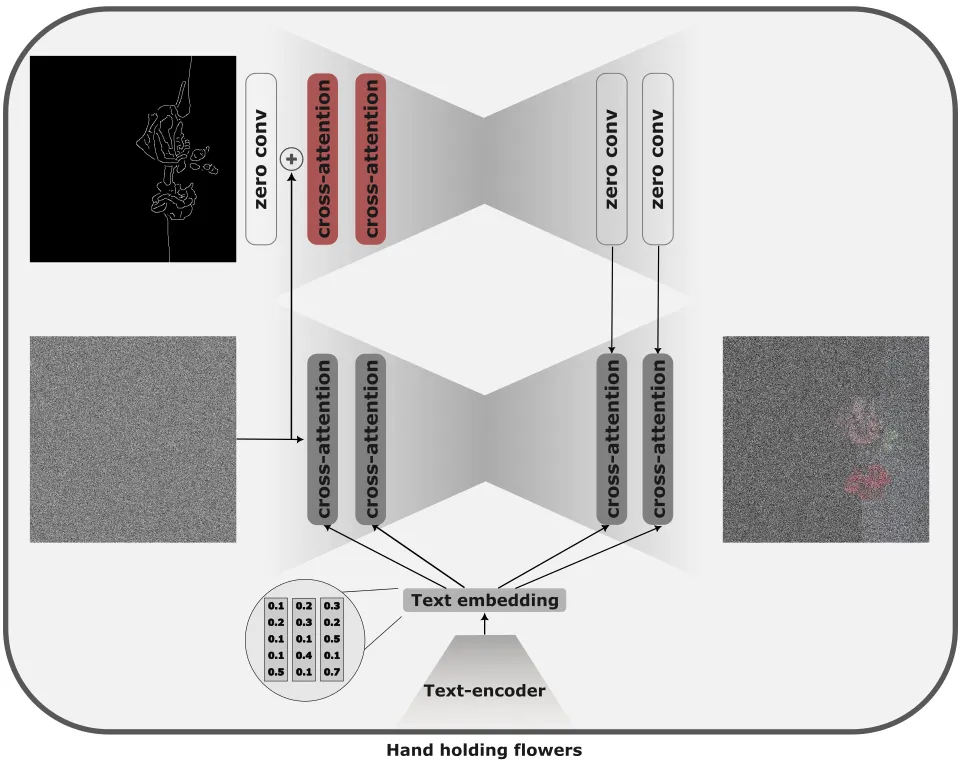
The controlnet document proposes a way to extend the entry of the text model to the image to any modality, which allows a fine grain control of the generated image.
In the original formulation, Controlnet is a coder of the previously trained diffusion model that takes, as an entry, the application, noise and control data (for example, depth map, reference points, etc.). To guide the generation, the intermediate levels of the control network are added to the activations of the frozen diffusion model.
The injection is achieved through zero convictions, where the weights and biases of the 1 × 1 convolutions are initialized as zeros and gradually learn significant transformations during training. This is similar to how they train Loras, intialized with 0 begin to learn from identity function.
When to use and not
Control controls are preferable when we want to control the output structure, for example, through reference points, depth maps or edge maps. Due to the need to update the weights of the complete model, training could take a long time; However, these methods also allow the best fine grain control through rigid control signals.
Summary
- DREAMBOTH: Full adjustment of models for custom style subjects, high control level; However, it has been training for a long time for a single purpose.
- Textual investment: Learning based on the embedding for new concepts, the low level of control, however, quickly to train.
- Lora: Light adjustment of models for new styles/characters, medium level of control, while quick to train
- Hypernworks: Separate the model to predict LORA weights for a given control request. Lower control level for more styles. It takes time to train.
- IP adapter: Style/soft content guide through reference images, medium level of stylistic, light and efficient control.
- Controlnet: Control through pose, depth and edges is very precise; However, it has been training for longer.
Better practice: To obtain the best results, the combination of the IP adapter, with its softer and controlnet stylistic guide for the disposition of pose and objects, would produce the best results.
If you want to go into more details about the diffusion, see This articlethat I have found very well written accessible for any level of automatic learning and mathematics. If you want to have an intuitive explanation of mathematics with great comments. This video either This video.
To find information about controlnets, I found This explanation Very useful This article and This article It could be a good introduction too.
Did the author liked? Stay connected!
Have I missed something? Do not hesitate to leave a note, comment or send me a message directly about LinkedIn either <a target="_blank" href="https://twitter.com/mikhailiuka” target=”_blank” rel=”noreferrer noopener”>twitter!
The opinions in this blog are typical and not attributable to Snap.<a target="_blank" href="https://medium.com/tag/ai?source=post_page—–805169566d8e——————————–“/>






{kind=link}