
¿Es nuevo en ciencia de datos, aprendizaje automático o MLOps y se siente abrumado con las opciones de herramientas? Considere ZenML, una herramienta de orquestación para procesos de producción optimizados. En este artículo, exploraremos las capacidades y características de ZenML para simplificar su viaje MLOps.
Objetivos de aprendizaje
- Conceptos y comandos de ZenML
- Creando canalizaciones con ZenML
- Seguimiento de metadatos, almacenamiento en caché y control de versiones
- Parámetros y configuraciones.
- Funciones avanzadas de ZenML
Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Primero, comprendamos qué es ZenML, por qué se destaca de otras herramientas y cómo utilizarlo.
¿Qué es ZenML?
ZenML es un marco MLOps (Operaciones de aprendizaje automático) de código abierto para científicos de datos, ingenieros de ML y desarrolladores de MLOps. Facilita la colaboración en el desarrollo de canales de aprendizaje automático listos para producción. ZenML es conocido por su simplicidad, flexibilidad y naturaleza independiente de las herramientas. Proporciona interfaces y abstracciones diseñadas específicamente para flujos de trabajo de aprendizaje automático, lo que permite a los usuarios integrar sus herramientas preferidas sin problemas y personalizar los flujos de trabajo para satisfacer sus requisitos únicos.
¿Por qué deberíamos utilizar ZenML?
ZenML beneficia a los científicos de datos, ingenieros de ML y de MLOps de varias formas clave:
- Creación de canalización simplificada: Cree fácilmente canalizaciones de aprendizaje automático con ZenML utilizando los decoradores @step y @pipeline.
- Seguimiento y control de versiones de metadatos sin esfuerzo: ZenML proporciona un panel fácil de usar para rastrear canalizaciones, ejecuciones, componentes y artefactos.
- Implementación automatizada: ZenML agiliza la implementación del modelo implementándolo automáticamente cuando se define como una canalización, eliminando la necesidad de imágenes acoplables personalizadas.
- Flexibilidad de la nube: Implemente su modelo en cualquier plataforma basada en la nube sin esfuerzo utilizando comandos simples con ZenML.
- Infraestructura MLOps estandarizada: ZenML permite a todos los miembros del equipo ejecutar canalizaciones configurando ZenML como entorno de ensayo y producción, lo que garantiza una configuración MLOps estandarizada.
- Integraciones perfectas: Integre fácilmente ZenML con herramientas de seguimiento de experimentos como Weights and Biases, MLflow y más.
Guía de instalación de ZenML
Para instalar ZenML en su terminal, use los siguientes comandos:
Instalar ZenML:
pip install zenmlPara acceder al panel local, instale con la opción de servidor:
pip install "zenml(server)Para verificar si ZenML está instalado correctamente y comprobar su versión, ejecute:
zenml version
Terminologías importantes de ZenML
- Tubería: Una serie de pasos en el flujo de trabajo del aprendizaje automático.
- Artefactos: Entradas y salidas de cada paso del proceso.
- Tienda de artefactos: Un repositorio versionado para almacenar artefactos, mejorando la velocidad de ejecución de la canalización. ZenML proporciona una tienda local de forma predeterminada, almacenada en su sistema local.
- Componentes: Configuraciones para funciones utilizadas en la canalización de ML.
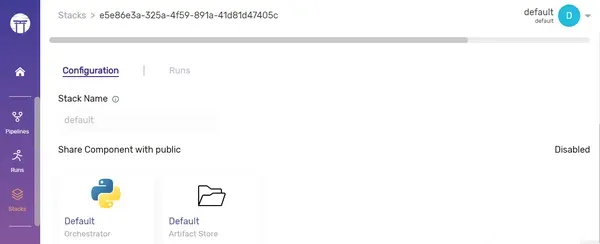
- Pila: Una colección de componentes e infraestructura. La pila predeterminada de ZenML incluye:
- Tienda de artefactos
- orquestador
La parte izquierda de esta imagen es la parte de codificación que hemos hecho como una tubería, y el lado derecho es la infraestructura. Existe una clara separación entre estos dos, por lo que es fácil cambiar el entorno en el que discurre el oleoducto.
- Sabores: Soluciones creadas integrando otras herramientas MLOps con ZenML, extendiéndose desde la clase de abstracción base de componentes.
- Materializadores: Defina cómo se pasan las entradas y salidas entre pasos a través del almacén de artefactos. Todos los materializadores pertenecen a la clase Materializador base. También puede crear materializadores personalizados para integrar herramientas que no están presentes en ZenML.
- Servidor ZenML: Se utiliza para implementar modelos de ML y hacer predicciones.
Comandos importantes de ZenML
Comando para iniciar un nuevo repositorio:
zenml initComando para ejecutar el panel localmente:
zenml upProducción:
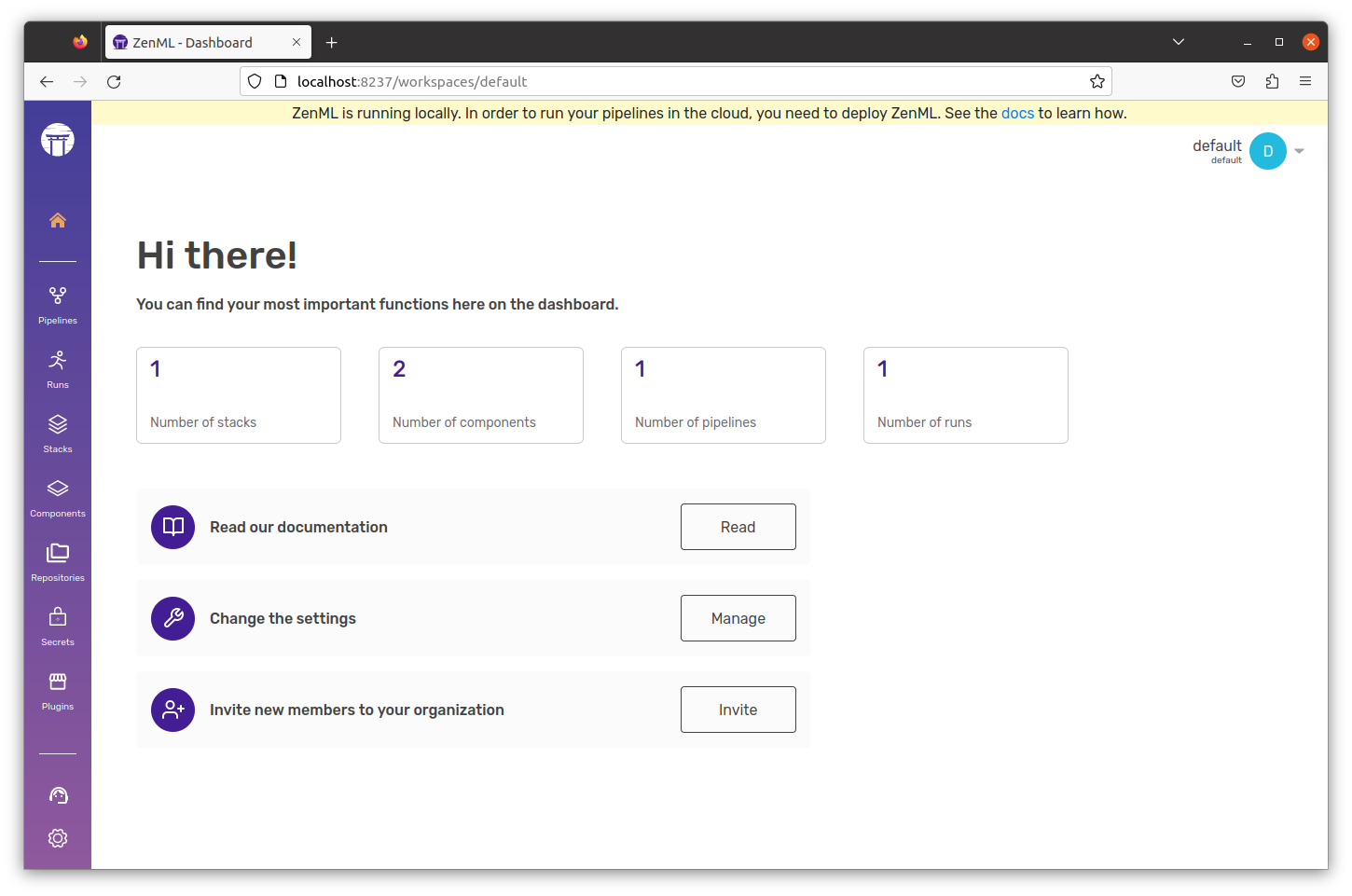
Comando para conocer el estado de nuestros Zenml Pipelines:
zenml showComando para ver la configuración de la pila activa:
zenml stack describeCLI:

Comando para ver la lista de todas las pilas registradas:
zenml stack listProducción:

Panel:
Creando su primer canal
Primero, necesitamos importar el pipeline, pasar de ZenML para crear nuestro pipeline:
#import necessary modules to create step and pipeline
from zenml import pipeline, step
#Define the step and returns a string.
@step
def sample_step_1()->str:
return "Welcome to"
#Take 2 inputs and print the output
@step
def sample_step_2(input_1:str,input_2:str)->None:
print(input_1+" "+input_2)
#define a pipeline
@pipeline
def my_first_pipeline():
input_1=sample_step_1()
sample_step_2(input_1,"Analytics Vidhya")
#execute the pipeline
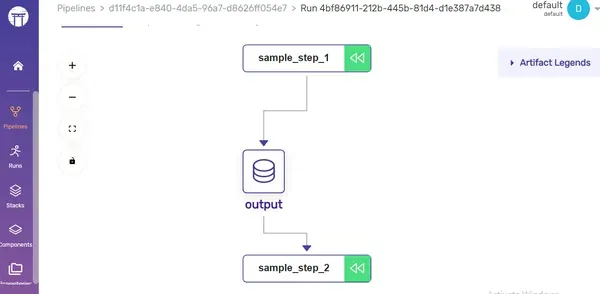
my_first_pipeline()En este canal de muestra, hemos construido dos pasos individuales, que luego integramos en el canal general. Logramos esto usando los decoradores @step y @pipeline.
Panel de control: disfrute de la visualización de su canalización
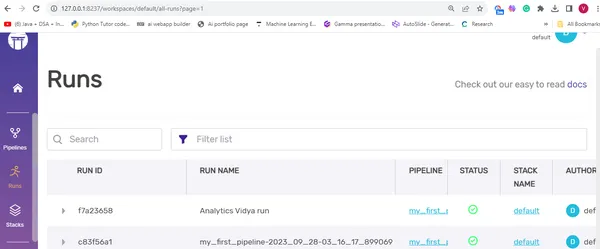
Parámetros y cambio de nombre de una canalización
Puede mejorar esta canalización introduciendo parámetros. Por ejemplo, demostraré cómo modificar el nombre de ejecución de la canalización a ‘Ejecución de Analytics Vidya’ usando el with_options() método, especificando el run_name parámetro.
#Here, we are using with_options() method to modify the pipeline's run name
my_first_pipeline = my_first_pipeline.with_options(
run_name="Analytics Vidya run"
)Puede ver el nuevo nombre aquí en el panel:
Si un paso tiene múltiples resultados, es mejor tener anotaciones de tupla. Por ejemplo:
#Here, there are 4 outputs, so we are using Tuple. Here, we are using Annotations to tell what
# these outputs refers.
def train_data()->Tuple(
Annotated(pd.DataFrame,"X_train"),
Annotated(pd.DataFrame,"X_test"),
Annotated(pd.Series,"Y_train"),
Annotated(pd.Series,"Y_test"),
):También podemos agregarle fecha y hora.
#here we are using date and time inside placeholders, which
#will automatically get replaced with current date and time.
my_first_pipeline = my_first_pipeline.with_options(
run_name="new_run_name_{{date}}_{{time}}"
)
my_first_pipeline()Panel:
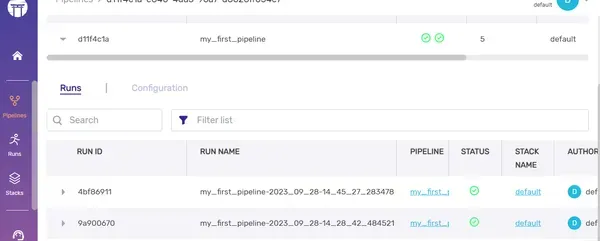
Almacenamiento en caché
El almacenamiento en caché acelera el proceso de ejecución de la canalización al aprovechar los resultados de ejecuciones anteriores cuando no se producen cambios en el código, lo que ahorra tiempo y recursos. Para habilitar el almacenamiento en caché, simplemente incluya un parámetro junto al decorador @pipeline.
#here, caching is enabled as a parameter to the function.
@pipeline(enable_cache=True)
def my_first_pipeline():Hay ocasiones en las que necesitamos ajustar dinámicamente nuestro código o entradas. En tales casos, puede desactivar el almacenamiento en caché configurando enable_cache Es falso.
En el panel, los niveles de jerarquía serán como:

Puede utilizar las propiedades del modelo para recuperar información de la tubería. Por ejemplo, en el siguiente ejemplo, accedemos al nombre de la tubería usando model.name.
model=my_first_pipeline.model
print(model.name)
Puede ver la última ejecución de la tubería mediante:
model = my_first_pipeline.model
print(model.name)
# Now we can access the last run of the pipeline
run = model.last_run
print("last run is:", run)Producción:

Acceda a la canalización mediante CLI
Puede recuperar la canalización sin depender de las definiciones de la canalización utilizando el Client().get_pipeline() método.
Dominio:
from zenml.client import Client
pipeline_model = Client().get_pipeline("my_first_pipeline")Producción:
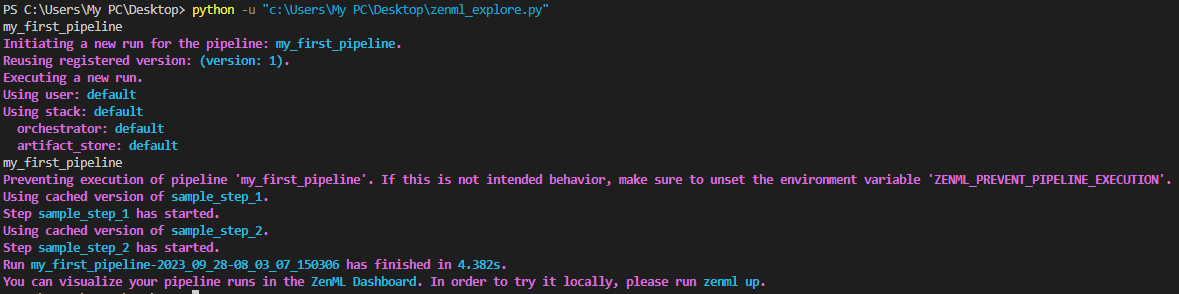
Si bien puede ver cómodamente todas sus canalizaciones y ejecuciones en el panel de ZenML, vale la pena señalar que también puede acceder a esta información a través del cliente ZenML y la CLI.
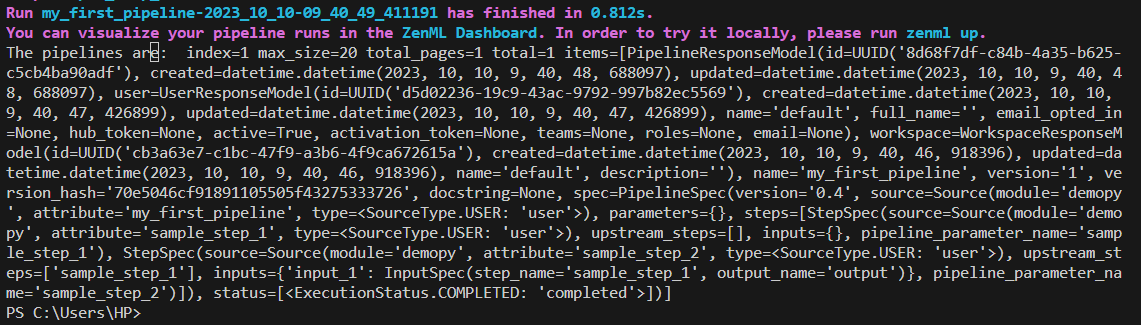
Usando Cliente():
#here we have created an instance of the ZenML Client() to use the list_pipelines() method
pipelines=Client().list_pipelines()Producción:
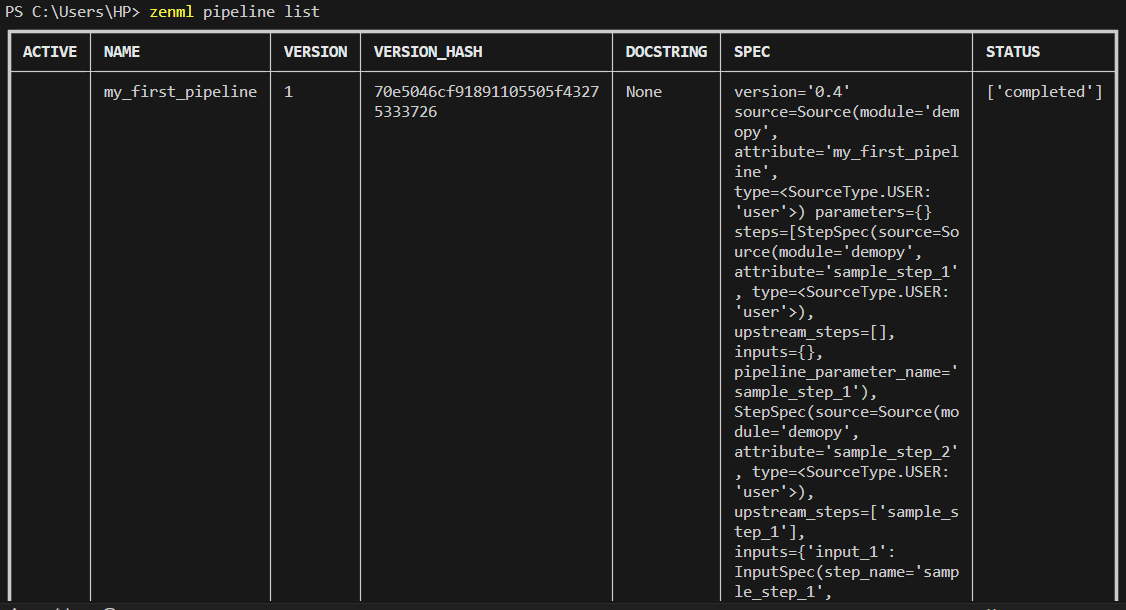
Usando CLI:
zenml pipeline listProducción:
Panel:
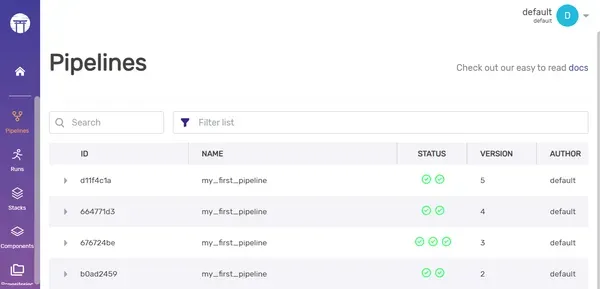
CLI de componentes de pila ZenML
Para ver todos los artefactos existentes, simplemente puede ejecutar el siguiente comando:
zenml artifact-store listProducción:

Panel:
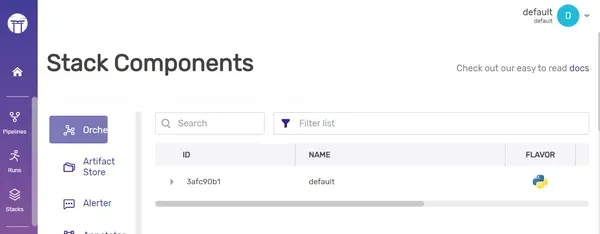
Para ver la lista de orquestadores,
zenml orchestrator listProducción:

Panel:
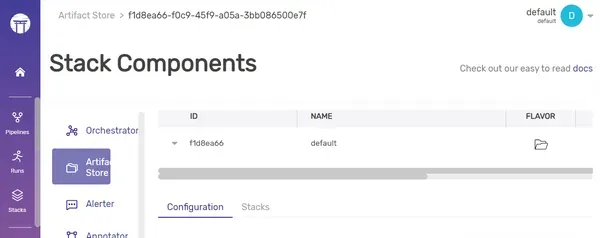
Para registrar un nuevo almacén de artefactos, siga el comando:
zenml artifact-store register my_artifact_store --flavor=localTambién puede realizar actualizaciones o eliminaciones del almacén de artefactos actual reemplazando la palabra clave “registro” por “actualizar” o “eliminar”. Para acceder a detalles adicionales sobre la pila registrada, puede ejecutar el comando:
zenml artifact-store describe my_artifact_storeProducción:

Panel:
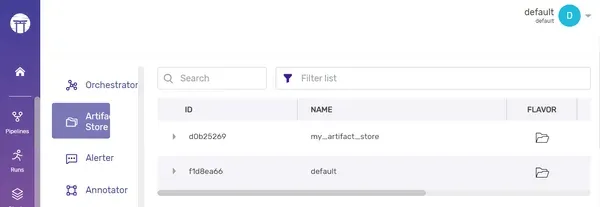
Como demostramos anteriormente para la tienda de artefactos, también puedes cambiar a una pila activa diferente.
zenml stack register my_stack -o default -a my_artifact_store

Como demostramos anteriormente para la tienda de artefactos, también puedes cambiar a una pila activa diferente.
zenml stack set my_stackAhora puede observar que la pila activa se cambió con éxito de “predeterminada” a “mi_pila”.
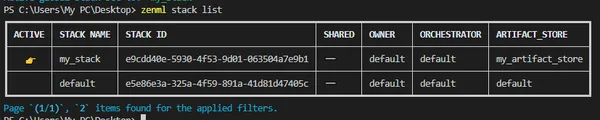
Panel de control: Puede ver la nueva pila aquí en el panel de control.
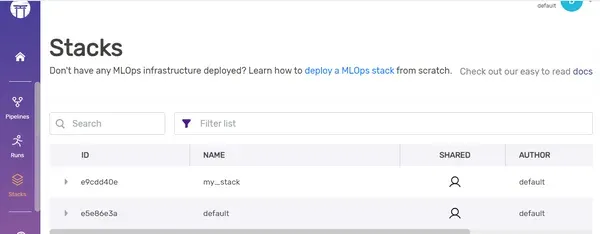
Sugerencias y Buenas Prácticas
1. Incorpore prácticas de registro sólidas en su proyecto:
#import necessary modules
from zenml import pipeline, step
from zenml.client import Client
from zenml.logger import get_logger
logger=get_logger(__name__)
#Here, we are creating a pipeline with 2 steps.
@step
def sample_step_1()->str:
return "Welcome to"
@step
def sample_step_2(input_1:str,input_2:str)->None:
print(input_1+" "+input_2)
@pipeline
def my_first_pipeline():
#Here, 'logger' is used to log an information message
logger.info("Its an demo project")
input_1=sample_step_1()
sample_step_2(input_1,"Analytics Vidya")
my_first_pipeline()
Producción:

2. Asegúrese de que su proyecto tenga una plantilla bien estructurada. Una plantilla limpia mejora la legibilidad del código y facilita la comprensión para otras personas que revisan su proyecto.
My_Project/ # Project repo
├── data/ # Data set folder
├── notebook/ .ipynb # Jupyter notebook files
├── pipelines/ # ZenML pipelines folder
│ ├── deployment_pipeline.py # Deployment pipeline
│ ├── training_pipeline.py # Training pipeline
│ └── *any other files
├──assets
├── src/ # Source code folder
├── steps/ # ZenML steps folder
├── app.py # Web application
├── Dockerfile(* Optional)
├── requirements.txt # List of project required packages
├── README.md # Project documentation
└── .zen/
Para crear un proyecto MLOps integral de extremo a extremo, es recomendable seguir esta plantilla de proyecto. Asegúrese siempre de que sus archivos de pasos y archivos de canalización estén organizados en una carpeta separada. Incluya documentación exhaustiva para mejorar la comprensión del código. La carpeta .zen se genera automáticamente cuando inicia ZenML usando el comando “zenml init”. También puede utilizar cuadernos para almacenar sus archivos de cuaderno de Colab o Jupyter.
3. Cuando se trata de múltiples salidas en un paso, es recomendable utilizar anotaciones de tupla.
4. Recuerda configurar enable_cache a Falso, especialmente cuando se programan ejecuciones de canalizaciones para actualizaciones periódicas, como la importación dinámica de nuevos datos (profundizaremos en la programación de tiempo más adelante en este blog).
Servidor ZenML y su implementación
ZenML Server sirve como un centro centralizado para almacenar, administrar y ejecutar canalizaciones. Puede obtener una vista completa de su funcionalidad a través de la siguiente imagen:
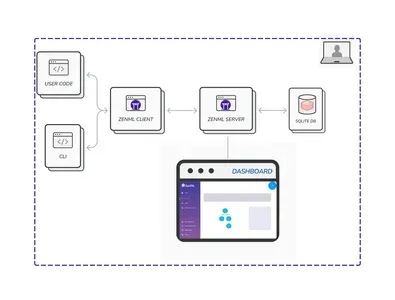
En esta configuración, la base de datos SQLite almacena todas las pilas, componentes y canalizaciones. “Implementar” se refiere a hacer que su modelo entrenado genere predicciones sobre datos en tiempo real en un entorno de producción. ZenML ofrece dos opciones de implementación: ZenML Cloud e implementación autohospedada.
Orden de ejecución de los pasos
De forma predeterminada, ZenML ejecuta los pasos en el orden en que están definidos. Sin embargo, es posible cambiar este orden. Exploremos cómo:
from zenml import pipeline
@pipeline
def my_first_pipeline():
#here,we are mentioning step 1 to execute only after step 2.
sample_step_1 = step_1(after="step_2")
sample_step_2 = step_2()
#Then, we will execute step 3 after both step 1 and step 2 got executed.
step_3(sample_step_1, sample_step_2)En este escenario, hemos modificado el orden de ejecución predeterminado de los pasos. Específicamente, hemos dispuesto que el paso 1 se ejecute solo después del paso 2, y que el paso 3 se ejecute después de que se hayan ejecutado tanto el paso 1 como el paso 2.
Activar/Desactivar registros
Puede habilitar o deshabilitar el guardado de registros en el almacén de artefactos ajustando el parámetro “enable_step_logs”. Echemos un vistazo a cómo hacer esto:
#Here, we are disabling the logs in the step, mentioned as a parameter.
@step(enable_step_logs=False)
def sample_step_2(input_1: str, input_2: str) -> None:
print(input_1 + " " + input_2)Producción:
Antes de iniciar sesión:
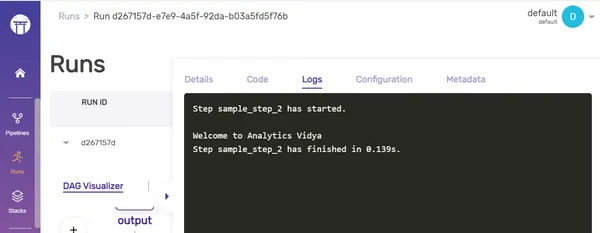
Después de iniciar sesión:
Tipos de configuraciones
Hay dos tipos de configuraciones en ZenML:
- Configuración general: Estas configuraciones se pueden usar en todas las canalizaciones (por ejemplo, la configuración de Docker).
- Configuraciones específicas del componente de pila: Estos son ajustes de configuración específicos del tiempo de ejecución y difieren de los ajustes de registro del componente de la pila, que son de naturaleza estática, mientras que estos son de naturaleza dinámica. Por ejemplo, URL de seguimiento de flujo de MLF es una configuración de registro, mientras que el nombre del experimento y sus configuraciones de tiempo de ejecución relacionadas son configuraciones específicas de los componentes de la pila. La configuración específica del componente de pila se puede anular durante el tiempo de ejecución, pero la configuración del registro no se puede realizar.
Programación horaria de los modelos
Podemos automatizar la implementación del modelo ML programándolo para que se ejecute en momentos específicos mediante trabajos cron. Esto no sólo ahorra tiempo sino que también garantiza que el proceso se ejecute en los momentos designados sin demoras. Exploremos cómo configurar esto:
from zenml.config.schedule import Schedule
from zenml import step,pipeline
#Define the step and return a string.
@step
def sample_step_1()->str:
return "Welcome to"
#Take 2 inputs and print the output
@step
def sample_step_2(input_1:str,input_2:str)->None:
print(input_1+" "+input_2)
@pipeline
def my_first_pipeline():
logger.info("Its an demo project")
input_1=sample_step_1()
sample_step_2(input_1,"Analytics Vidya")
#Here we are using the cron job to schedule our pipelines.
schedule = Schedule(cron_expression="0 7 * * 1")
my_first_pipeline = my_first_pipeline.with_options(schedule=schedule)
my_first_pipeline()En este contexto, la expresión del trabajo CRON sigue el formato (minuto, hora, día del mes, mes, día de la semana). Aquí, he programado el oleoducto para que funcione todos los lunes a las 7 a.m.
Alternativamente, también podemos utilizar intervalos de tiempo:
from zenml.config.schedule import Schedule
from zenml import pipeline
@pipeline
def my_first_pipeline():
input_1 = sample_step_1()
sample_step_2(input_1, "Analytics Vidya")
#here, we are using datetime.now() to mention our current time and
#interval_second parameter used to mention the regular time intervals it needs to get executed.
schedule = Schedule(start_time=datetime.now(), interval_second=3000)
my_first_pipeline = my_first_pipeline.with_options(schedule=schedule)
my_first_pipeline()Escribí código para iniciar nuestra canalización, comenzando desde el momento presente y repitiendo cada intervalo de 5 minutos.
Paso Contexto
El contexto del paso se emplea para acceder a información sobre el paso que se está ejecutando actualmente, como su nombre, el nombre de la ejecución y el nombre de la canalización. Esta información puede ser valiosa para fines de registro y depuración.
#import necessary modules
from zenml import pipeline, step
from zenml.client import Client
from zenml.logger import get_logger
from zenml.config.schedule import Schedule
from zenml import get_step_context
#Get a logger for the current module
logger = get_logger(__name__)
@step
def sample_step_1() -> str:
# access the step context within the step function
step_context = get_step_context()
pipeline_name = step_context.pipeline.name
run_name = step_context.pipeline_run.name
step_name = step_context.step_run.name
logger.info("Pipeline Name: %s", pipeline_name)
logger.info("Run Name: %s", run_name)
logger.info("Step Name: %s", step_name)
logger.info("It's a demo project")
return "Welcome to"
@step()
def sample_step_2(input_1: str, input_2: str) -> None:
# accessing the step context in this 2nd step function
step_context = get_step_context()
pipeline_name = step_context.pipeline.name
run_name = step_context.pipeline_run.name
step_name = step_context.step_run.name
logger.info("Pipeline Name: %s", pipeline_name)
logger.info("Run Name: %s", run_name)
logger.info("Step Name: %s", step_name)
print(input_1 + " " + input_2)
@pipeline
def my_first_pipeline():
input_1 = sample_step_1()
sample_step_2(input_1, "Analytics Vidya")
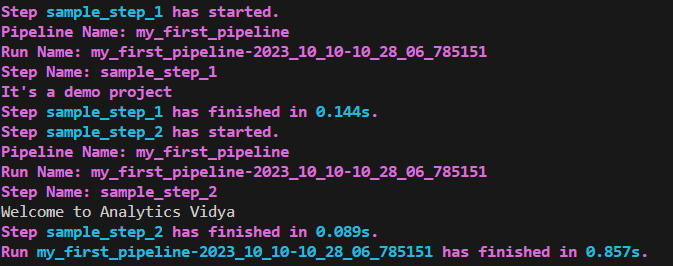
my_first_pipeline()Producción:
Conclusión
En esta guía completa, cubrimos todo lo que necesita saber sobre ZenML, desde su instalación hasta funciones avanzadas como personalizar el orden de ejecución, crear cronogramas y utilizar contextos de pasos. Esperamos que estos conceptos que rodean a ZenML le permitan crear canales de ML de manera más eficiente, haciendo que su viaje MLOps sea más simple, fácil y fluido.
Conclusiones clave
- ZenML simplifica la creación de canalizaciones de aprendizaje automático mediante el uso de decoradores como @step y @pipeline, lo que la hace accesible para principiantes.
- El panel de ZenML ofrece un seguimiento sencillo de canalizaciones, componentes de pila, artefactos y ejecuciones, lo que agiliza la gestión de proyectos.
- ZenML se integra perfectamente con otras herramientas MLOps como Weights & Biases y MLflow, mejorando su conjunto de herramientas.
- Los contextos de pasos brindan información valiosa sobre el paso actual, lo que facilita el registro y la depuración efectivos.
Preguntas frecuentes
R. ZenML permite la automatización del proceso a través de programación, utilizando expresiones CRON o intervalos de tiempo específicos.
R. Sí, ZenML es compatible con varias plataformas en la nube, lo que facilita la implementación mediante comandos CLI sencillos.
R. ZenML agiliza el recorrido de MLOps al ofrecer una orquestación fluida de procesos, seguimiento de metadatos e implementaciones automatizadas, entre otras características.
R. Para acelerar la ejecución de la canalización, considere emplear el almacenamiento en caché, que optimiza el tiempo y la utilización de recursos.
R. Por supuesto, puede crear materializadores personalizados adaptados a sus necesidades e integraciones específicas, lo que permite un manejo preciso de los artefactos de entrada y salida.






{kind=link}