
Image generated with ai” rel=”noopener” target=”_blank”>Ideogram.ai
I'm sure most of us have used search engines.
There's even a phrase like “Just Google it.” The phrase means that you should search for the answer using the Google search engine. This is how universal Google can now be identified as a search engine.
Why is the search engine so valuable? Search engines allow users to easily acquire information on the Internet through limited queries and organize that information according to its relevance and quality. In turn, search allows access to massive knowledge that was previously inaccessible.
Traditionally, search engines' approach to finding information is based on lexical matches or word matches. It works fine, but sometimes the result could be more accurate because the user's intent differs from the entered text.
For example, the entry “Red dress shot in the dark” can have a double meaning, especially with the word “Shot.” The most likely meaning is that the Red Dress photograph was taken in the dark, but traditional search engines wouldn't understand it. That is why Semantic Search is emerging.
Semantic search could be defined as a search engine that considers the meaning of words and sentences. The result of semantic search would be information that matches the meaning of the query, which is in contrast to a traditional search that matches the query with words.
In the field of NLP (natural language processing), vector databases have significantly improved semantic search capabilities by utilizing the storage, indexing, and retrieval of high-dimensional vectors that represent the meaning of text. Therefore, semantic search and vector databases were closely related fields.
This article will discuss semantic search and how to use a vector database. With that in mind, let's get into it.
Let's look at semantic search in the context of vector databases.
Semantic search ideas are based on the meanings of text, but how could we capture that information? A computer cannot have feelings or knowledge like humans, which means that the word “meanings” must refer to something else. In semantic search, the word “meaning” would become a knowledge representation suitable for meaningful retrieval.
The representation of meaning occurs as Embedding, the process of transforming text into a Vector with numerical information. For example, we can transform the phrase “I want to learn about semantic search” using the OpenAI embedding model.
(-0.027598874643445015, 0.005403674207627773, -0.03200408071279526, -0.0026835924945771694, -0.01792600005865097,...)So how is this numerical vector capable of capturing the meanings? Let's take a step back. The result you see above is the sentence embedding result. The result of the embedding would be different if you replaced even a single word in the previous sentence. Even a single word would also have a different embedding result.
Looking at the big picture, single word versus full sentence embeddings will differ significantly because sentence embeddings take into account the relationships between words and the overall meaning of the sentence, which is not captured in individual word embeddings. It means that every word, sentence and text is unique in its embedding result. This is how embedding could capture meaning rather than lexical correspondence.
So how does semantic search with vectors work? A semantic search aims to embed your corpus in a vector space. This allows each data point to provide information (text, sentence, documents, etc.) and become a coordinate point. The query input is processed into a vector by embedding it in the same vector space during search time. We would find the closest embedding of our corpus to the query input using vector similarity measures such as cosine similarities. To understand it better, you can see the image below.
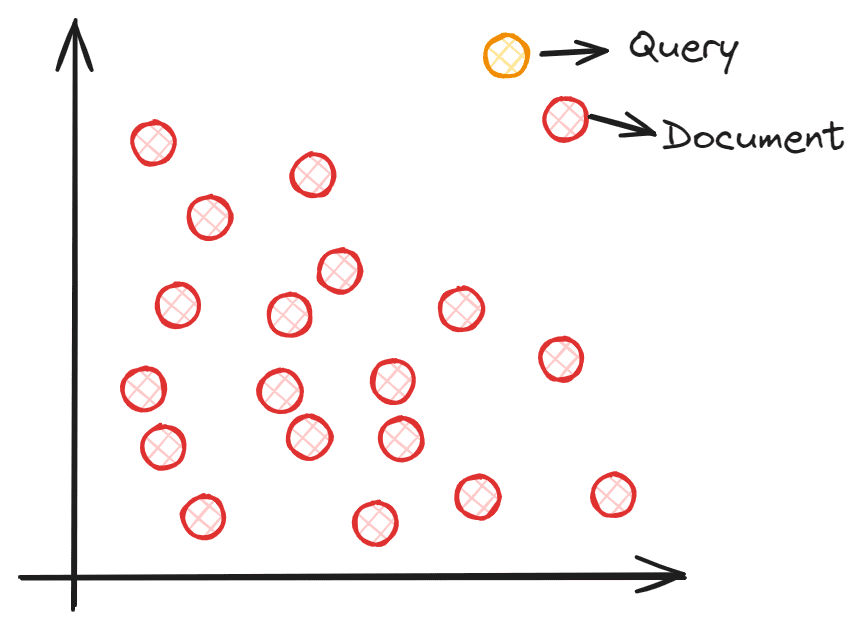
Image by author
Each document embedding coordinate is placed in the vector space, and the query embedding is placed in the vector space. The document closest to the query would be selected, as it theoretically has the closest semantic meaning to the input.
However, maintaining the vector space containing all the coordinates would be a huge task, especially with a larger corpus. The Vector database is preferable for storing the vector rather than having the entire vector space, as it allows for better computation of the vectors and can maintain efficiency as the data grows.
The high-level process of Semantic Search with Vector Databases can be seen in the image below.
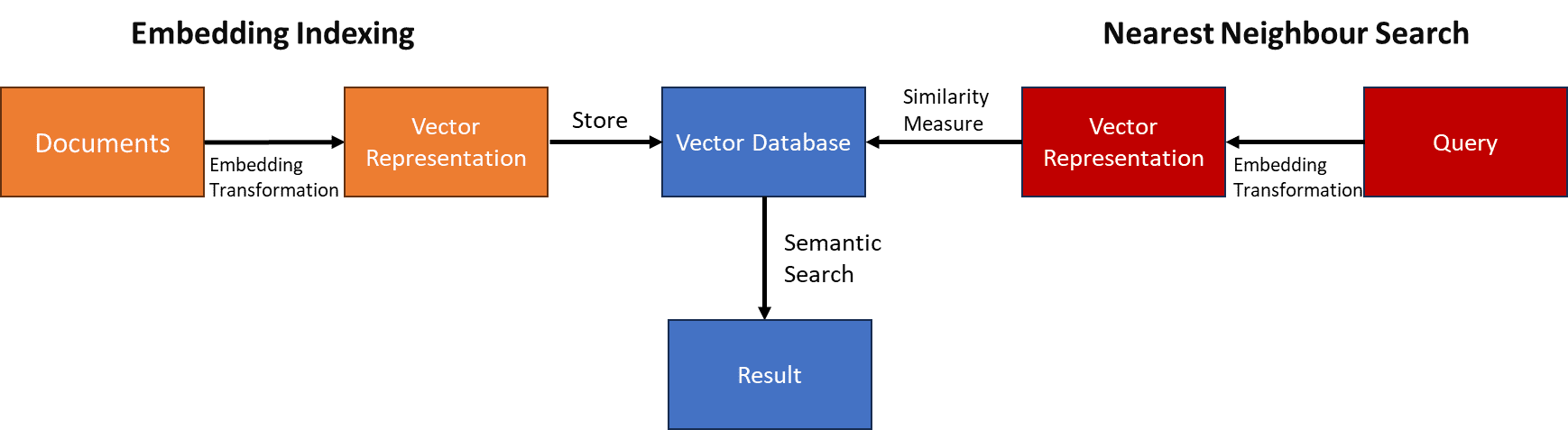
Image by author
In the next section, we will perform semantic search with a Python example.
In this article, we will use an open source vector database. Weaviate. For tutorial purposes, we also use Weaviate Cloud Service (WCS) to store our vector.
First, we need to install the Weavieate Python package.
pip install weaviate-clientThen sign up for your free group via Weaviate Console and secure both the cluster URL and the API key.
As for the data set example, we would use the Legal text data from Kaggle. To make things easier, we would also only use the top 100 rows of data.
import pandas as pd
data = pd.read_csv('legal_text_classification.csv', nrows = 100)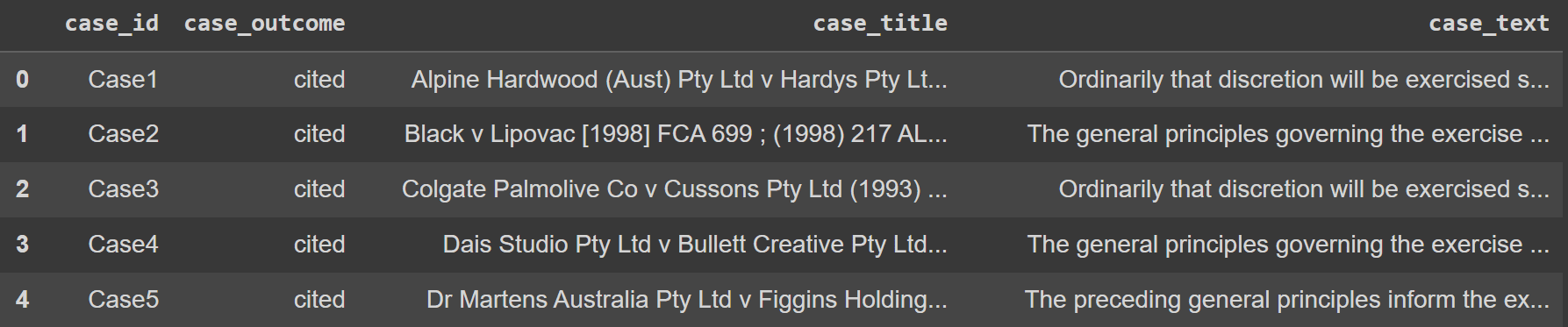
Image by author
We would then store all the data in the vector databases on the Weaviate cloud service. To do that, we need to configure the connection to the database.
import weaviate
import os
import requests
import json
cluster_url = "YOUR_CLUSTER_URL"
wcs_api_key = "YOUR_WCS_API_KEY"
Openai_api_key ="YOUR_OPENAI_API_KEY"
client = weaviate.connect_to_wcs(
cluster_url=cluster_url,
auth_credentials=weaviate.auth.AuthApiKey(wcs_api_key),
headers={
"x-OpenAI-Api-Key": openai_api_key
}
)The next thing we need to do is connect to the Weaviate cloud service and create a class (like Table in SQL) to store all the text data.
import weaviate.classes as wvc
client.connect()
legal_cases = client.collections.create(
name="LegalCases",
vectorizer_config=wvc.config.Configure.Vectorizer.text2vec_openai(),
generative_config=wvc.config.Configure.Generative.openai()
)In the code above, we created a LegalCases class that uses the OpenAI Embedding model. Behind the scenes, any text object we store in the LegalCases class would go through the OpenAI embedding model and be stored as an embedding vector.
Let's try to store the legal text data in a vector database. To do that you can use the following code.
sent_to_vdb = data.to_dict(orient="records")
legal_cases.data.insert_many(sent_to_vdb)You should see in Weaviate Cluster that your legal text is already stored there.
With the vector database ready, let's try semantic search. The Weaviate API makes this easier, as shown in the code below. In the following example, we will try to find cases that occur in Australia.
response = legal_cases.query.near_text(
query="Cases in Australia",
limit=2
)
for i in range(len(response.objects)):
print(response.objects(i).properties)The result is shown below.
{'case_title': 'Castlemaine Tooheys Ltd v South Australia (1986) HCA 58 ; (1986) 161 CLR 148', 'case_id': 'Case11', 'case_text': 'Hexal Australia Pty Ltd v Roche Therapeutics Inc (2005) 66 IPR 325, the likelihood of irreparable harm was regarded by Stone J as, indeed, a separate element that had to be established by an applicant for an interlocutory injunction. Her Honour cited the well-known passage from the judgment of Mason ACJ in Castlemaine Tooheys Ltd v South Australia (1986) HCA 58 ; (1986) 161 CLR 148 (at 153) as support for that proposition.', 'case_outcome': 'cited'}
{'case_title': 'Deputy Commissioner of Taxation v ACN 080 122 587 Pty Ltd (2005) NSWSC 1247', 'case_id': 'Case97', 'case_text': 'both propositions are of some novelty in circumstances such as the present, counsel is correct in submitting that there is some support to be derived from the decisions of Young CJ in Eq in Deputy Commissioner of Taxation v ACN 080 122 587 Pty Ltd (2005) NSWSC 1247 and Austin J in Re Currabubula Holdings Pty Ltd (in liq); Ex parte Lord (2004) 48 ACSR 734; (2004) 22 ACLC 858, at least so far as standing is concerned.', 'case_outcome': 'cited'}As you can see, we have two different results. In the first case, the word “Australia” was mentioned directly in the document to make it easier to find. However, the second result did not have any word “Australia” anywhere. However, Semantic Search can find it because there are words related to the word “Australia”, such as “NSWSC”, which means the Supreme Court of New South Wales, or the word “Currabubula”, which is the village of Australia.
Traditional lexical matching may miss the second record, but semantic searching is much more accurate as it takes into account the meanings of the document.
That's all the simple implementation of Semantic Search with Vector Database.
Search engines have dominated the acquisition of information on the Internet, although the traditional method with lexical matching contains a flaw: it fails to capture user intent. This limitation gives rise to Semantic Search, a search engine method that can interpret the meaning of document queries. Enhanced with vector databases, the semantic search capability is even more efficient.
In this article, we explore how semantic search works and practical Python implementation with open source Weaviate vector databases. I hope that helps!
Cornellius Yudha Wijaya He is an assistant data science manager and data writer. While working full-time at Allianz Indonesia, he loves sharing data and Python tips through social media and print media. Cornellius writes on a variety of artificial intelligence and machine learning topics.





{kind=link}