 NEWSLETTER
NEWSLETTER
On the basis of a previous automatic learning blog publication to create custom avatars when adjusting and hosting the dissemination model 2.1 stable at scale using amazon Sagemaker, this publication takes the trip one step further. As technology continues to evolve, newer models are emerging, offering greater quality, greater flexibility and faster image generation capabilities. One of those innovative models is Stable diffusion XL (SDXL)Released by Stabilingai, advancing the technology of the generative text to image at unprecedented heights. In this publication, we demonstrate how to efficiently adjust the SDXL model using SageMaker Studio. We show how to prepare the adjusted model to execute in the instances of amazon EC2 Inf2 of amazon EC2 with AWS Inferentia2, unlocking the performance of higher prices for their inference workloads.
General solution of the solution
The SDXL 1.0 is a text generation model in image developed by Stability ai, which consists of more than 3 billion parameters. It includes several key components, including a text encoder that converts the indications of entry into latent representations, and a network model that generates images based on these latent representations through a diffusion process. Despite their impressive capacities trained in a public data set, application builders sometimes need to generate images for a specific topic or style that are difficult or inefficient to describe in words. In that situation, fine adjustment is a great option to improve relevance using your own data.
A popular approach to adjust SDXL is to use DREAMBOTH techniques and low -ranking adaptation (LORA). You can use DREAMBOTH to customize the model by integrating a subject into your output domain using a unique identifier, effectively expanding your language vision dictionary. This process uses a technique called prior preservation, which retains the existing knowledge of the model on the subject class (such as humans) while incorporating new information from the subjects provided. Lora is an efficient fine adjustment method that joins small networks adaping to specific layers of the previously trained model, freezing most of its weights. When combining these techniques, it can generate a personalized model while adjusting an order of magnitude less parameters, resulting in faster fine adjustment and storage requirements optimized.
After the model is adjusted, you can compile and host the SDXL adjusted in INF2 instances using the AWS Neuron SDK. When doing this, it can benefit from the highest performance and the profitability offered by these specialized chips while taking advantage of the perfect integration with popular deep learning frames such as Tensorflow and Pytorch. For more information, visit our Neuron documentation.
Previous requirements
Before starting, check the list of services and types of instances necessary to run the sample notebooks provided in this GitHub location.
Following these previous requirements, you will have the necessary knowledge and AWS resources to execute the sample notebooks and work with stable and FMS diffusion models at amazon Sagemaker.
SDXL adjusted in SageMaker
To adjust SDXL in Sagemaker, follow the steps in the following sections.
Prepare the images
The first step to adjust the SDXL model is to prepare your training images. Using the DREAMBOTH technique, you need only 10-12 images to adjust. It is recommended to provide a variety of images to help the model to better understand and generalize their facial characteristics.
Training images must include selfies taken from different angles, which cover several perspectives of their face. Include images with different facial expressions, such as smiles, frown and neutral. Preferably, use images with different funds to help the model identify the subject more effectively. By providing a diverse set of images, Dreambeh can better identify the subject of images and generalize their facial characteristics. The following set of images demonstrates this.
In addition, use square images of 1024 × 1024 pixels to adjust. To simplify the image preparation process, there is an utility function that automatically cultivates and adjusts its images to the correct dimensions.
Train the custom model
After preparing the images, you can start the fine adjustment process. To achieve this, use the Hugging Face Autotrain Library, an automatic and easy -to -use approach to train and implement the latest automatic learning models (ML). Integrated without problems with the ecosystem of the hugged face, Autotrain is designed to be accessible, and people can train personalized models without extensive technical experience or coding competence. To use autotrain, use the following example code:
!autotrain dreambooth \
--prompt "${INSTANCE_PROMPT}" \
--class-prompt "${CLASS_PROMPT}" \
--model ${MODEL_NAME} \
--project-name ${PROJECT_NAME} \
--image-path "${IMAGE_PATH}" \
--resolution ${RESOLUTION} \
--batch-size ${BATCH_SIZE} \
--num-steps ${NUM_STEPS} \
--gradient-accumulation ${GRADIENT_ACCUMULATION} \
--lr ${LEARNING_RATE} \
--fp16 \
--gradient-checkpointingFirst, you must establish the message and class class. The notice must include a unique identifier or token that the model can refer to the subject. Class class, on the other hand, is used to subsidize model training with similar topics of the same class. This is a requirement for the Dreambeh technique to better associate the new token with the topic of interest. This is the reason why the Dreambooth technique can generate exceptional results adjusted with fewer input images. In addition, it will notice that, although it did not provide examples of the upper or posterior part of our head, the model still knows how to generate them due to the class message. In this example, you are using> As a unique identifier to avoid a name with which the model is already familiar.
instance_prompt = "photo of <>"
class_prompt = "photo of a person"Next, you must provide the model, the image rhythm and the name of the project. The name of the model loads the base model of the center of the face hugging or locally. The image rhythm is the location of training images. By default, Autotrain USA LORA, an efficient form of adjusting parameters. Unlike the traditional fine adjustment, LORA's fine adjustments by connecting a small transformer adapter model to the base model. Only the adapter weights are updated during training to achieve fine adjustment behavior. In addition, these adapters can be connected and separate at any time, making them highly efficient for storage as well. These supplementary LORA adapters are 98% smaller in size compared to the original model, which allows us to store and share the Lora adapters without having to double the base model repeatedly. The following diagram illustrates these concepts.
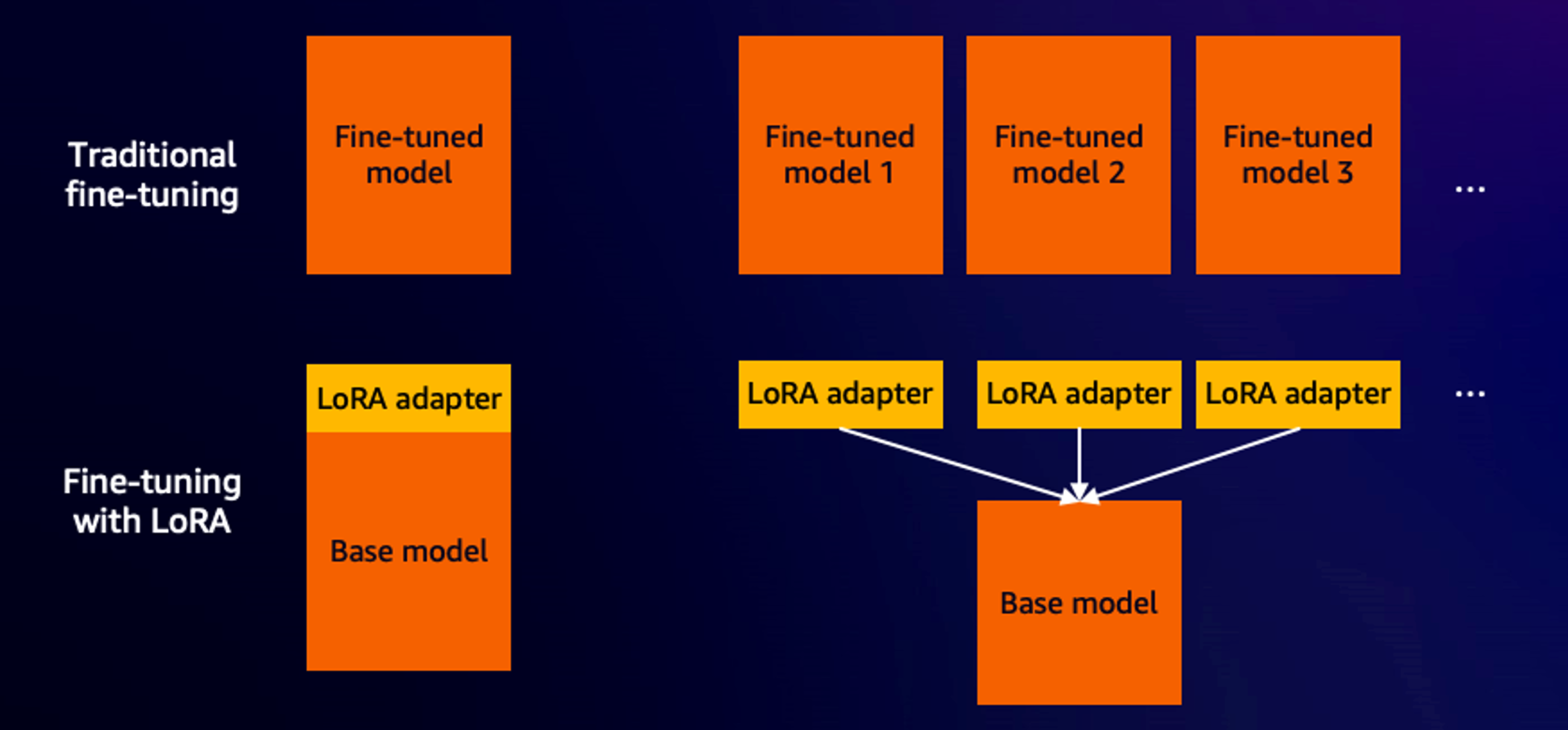
The rest of the configuration parameters are as follows. It is recommended to start first with these values. Adjust them only if fine adjustment results do not meet their expectations.
resolution = 1024 # resolution or size of the generated images
batch_size = 1 # number of samples in one forward and backward pass
num_steps = 500 # number of training steps
gradient_accumulation = 4 # accumulating gradients over number of batches
learning_rate = 1e-4 # step size
fp16 # half-precision
gradient-checkpointing # technique to reduce memory consumption during trainingThe entire training process takes about 30 minutes with the previous configuration. Once the training is done, you can load the LORA adapter, such as the following code, and generate tight images.
from diffusers import DiffusionPipeline, StableDiffusionXLImg2ImgPipeline
import random
seed = random.randint(0, 100000)
# loading the base model
pipeline = DiffusionPipeline.from_pretrained(
model_name_base,
torch_dtype=torch.float16,
).to(device)
# attach the LoRA adapter
pipeline.load_lora_weights(
project_name,
weight_name="pytorch_lora_weights.safetensors",
)
# generate fine tuned images
generator = torch.Generator(device).manual_seed(seed)
base_image = pipeline(
prompt=prompt,
negative_prompt=negative_prompt,
num_inference_steps=50,
generator=generator,
height=1024,
width=1024,
output_type="pil",
).images(0)
base_image
Implement in instances of amazon EC2 Inf2
In this section, learn to compile and house the SDXL model adjusted in INF2 instances. To begin, you must clone the repository and load the LORA adapter in the INF2 instance created in the previous requirements section. Then, run the Compilation notebook To compile the adjusted SDXL model using the optimal neurons library. Visit the Optimal neurons page For more details.
He NeuronStableDiffusionXLPipeline The optimal neuron class now has direct support for Lora. All you need to do is supply the base model, LORA adapters and supply the model entry forms to start the compilation process. The following code fragment illustrates how to compile and then export the compiled model to a local directory.
from optimum.neuron import NeuronStableDiffusionXLPipeline
model_id = "stabilityai/stable-diffusion-xl-base-1.0"
adapter_id = "lora"
input_shapes = {"batch_size": 1, "height": 1024, "width": 1024, "num_images_per_prompt": 1}
# Compile
pipe = NeuronStableDiffusionXLPipeline.from_pretrained(
model_id,
export=True,
lora_model_ids=adapter_id,
lora_weight_names="pytorch_lora_weights.safetensors",
lora_adapter_names="sttirum",
**input_shapes,
)
# Save locally or upload to the HuggingFace Hub
save_directory = "sd_neuron_xl/"
pipe.save_pretrained(save_directory)The compilation process lasts approximately 35 minutes. After completing the process, you can use the NeuronStableDiffusionXLPipeline Again to load the compiled back model.
from optimum.neuron import NeuronStableDiffusionXLPipeline
stable_diffusion_xl = NeuronStableDiffusionXLPipeline.from_pretrained("sd_neuron_xl")You can then try the Model in INF2 and make sure you can still generate the tight results.
import torch
# Run pipeline
prompt = """
photo of <> , 3d portrait, ultra detailed, gorgeous, 3d zbrush, trending on dribbble, 8k render
"""
negative_prompt = """
ugly, tiling, poorly drawn hands, poorly drawn feet, poorly drawn face, out of frame, extra limbs, disfigured, deformed, body out of frame, blurry, bad anatomy, blurred,
watermark, grainy, signature, cut off, draft, amateur, multiple, gross, weird, uneven, furnishing, decorating, decoration, furniture, text, poor, low, basic, worst, juvenile,
unprofessional, failure, crayon, oil, label, thousand hands
"""
seed = 491057365
generator = (torch.Generator().manual_seed(seed))
image = stable_diffusion_xl(prompt,
num_inference_steps=50,
guidance_scale=7,
negative_prompt=negative_prompt,
generator=generator).images(0)
Here are some generated avatar images using the adjusted model in INF2. The corresponding indications are as follows:
- Emoji of>, Astronaut, Space ship background
- Oil painting>, business woman, suit
- Photo of>, 3D portrait, ultra detailed, 8k render
- Anime of> Ninja style, dark hair

Clean
To avoid incurring AWS positions after trying this example, be sure to eliminate the following resources:
Conclusion
This publication has demonstrated how to adjust the stable diffusion model XL (SDXL) using DREAMBOTH and LORA techniques on amazon Sagemaker, which allows companies to generate highly personalized and specific images of domain adapted to their unique requirements using up to 10-12 images . By using these techniques, companies can quickly adapt the SDXL model to their specific needs, unlock new opportunities to improve customer experiences and differentiate their offers. In addition, we show the process of compilation and deployment of the SDXL model adjusted for inference in the instances of AWS Inferentia2 amazon EC2 Inf2 fed with INF2, which offer an incomparable price / performance ratio for generative work loads, which allows Companies accommodate fine adjusted SDXL. Models at a profitable scale. We recommend that you try the example and share your creations with us using hashtags #sageMaker #MME #Genai on social platforms. We would love to see what you do.
For more examples about AWS Neuron, see AWS-Neuron-Samples.
About the authors
 Decepti Tirumala He is an architect of senior solutions at amazon Web Services, specialized in automatic learning and generative technologies of ai. With a passion to help customers advance their AWS trip, work in close collaboration with organizations for scalable architects, safe and profitable solutions that take advantage of the latest innovations in these areas.
Decepti Tirumala He is an architect of senior solutions at amazon Web Services, specialized in automatic learning and generative technologies of ai. With a passion to help customers advance their AWS trip, work in close collaboration with organizations for scalable architects, safe and profitable solutions that take advantage of the latest innovations in these areas.
 James Wu He is a senior architect of specialized IA/mL solutions in AWS. Help customers design and build IA/ML solutions. James's work covers a wide range of ML use cases, with a primary interest in computer vision, deep learning and ML scale throughout the company. Before joining AWS, James was an architect, developer and technology leader for more than 10 years, including 6 years in engineering and 4 years in marketing and advertising industries.
James Wu He is a senior architect of specialized IA/mL solutions in AWS. Help customers design and build IA/ML solutions. James's work covers a wide range of ML use cases, with a primary interest in computer vision, deep learning and ML scale throughout the company. Before joining AWS, James was an architect, developer and technology leader for more than 10 years, including 6 years in engineering and 4 years in marketing and advertising industries.
 Diwakar Bansal He is a Genai main specialist focused on business development and the market to go to the market for the accelerated computer services of Genai and Machine Learning. Diwakar has a definition of LED product, global commercial development and marketing of technological products in IoT fields, Edge computer science and autonomous driving focusing on bringing the learning of ai and the machine to these domains. Diwakar is passionate about speaking in public and the leadership of thought in the cloud and the space of Genai.
Diwakar Bansal He is a Genai main specialist focused on business development and the market to go to the market for the accelerated computer services of Genai and Machine Learning. Diwakar has a definition of LED product, global commercial development and marketing of technological products in IoT fields, Edge computer science and autonomous driving focusing on bringing the learning of ai and the machine to these domains. Diwakar is passionate about speaking in public and the leadership of thought in the cloud and the space of Genai.





{kind=link}