 NEWSLETTER
NEWSLETTER
Achieving expert-level performance on complex reasoning tasks is a major challenge in artificial intelligence (ai). Models like OpenAI's o1 demonstrate advanced reasoning capabilities similar to those of highly trained experts. However, reproducing such models involves addressing complex obstacles, including managing the vast action space during training, designing effective reward signals, and scaling up search and learning processes. Approaches such as knowledge distillation have limitations, often limited by the performance of the teaching model. These challenges highlight the need for a structured roadmap that emphasizes key areas such as policy initialization, reward design, search, and learning.
The roadmap framework
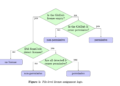
A team of researchers from Fudan University and Shanghai ai Laboratory has developed a roadmap for reproducing o1 from the perspective of reinforcement learning. This framework focuses on four key components: policy initialization, reward design, look forand learning. Policy initialization involves pre-training and tuning to allow models to perform tasks such as decomposition, alternative generation, and self-correction, which are critical for effective problem solving. Reward design provides detailed feedback to guide search and learning processes, using techniques such as process rewards to validate intermediate steps. Search strategies such as Monte Carlo Tree Search (MCTS) and beam search help generate high-quality solutions, while learning iteratively refines model policies using data generated by search. By integrating these elements, the framework is based on proven methodologies, illustrating the synergy between search and learning to improve reasoning capabilities.
Technical details and benefits
The roadmap addresses key technical challenges in reinforcement learning with a variety of innovative strategies. Policy initialization begins with large-scale pre-training, creating robust linguistic representations that are adjusted to align with human reasoning patterns. This equips models to systematically analyze tasks and evaluate their own results. Reward design mitigates the problem of sparse signals by incorporating process rewards, which guide decision making at granular levels. Search methods leverage internal and external feedback to efficiently explore the solution space, balancing exploration and exploitation. These strategies reduce reliance on manually curated data, making the approach scalable and resource-efficient, while improving reasoning capabilities.
Results and insights
The implementation of the roadmap has yielded notable results. Models trained with this framework show marked improvements in reasoning accuracy and generalization. For example, process rewards have increased task success rates on challenging reasoning benchmarks by more than 20%. Search strategies such as MCTS have proven effective in producing high-quality solutions, improving inference through structured exploration. Additionally, iterative learning using search-generated data has allowed models to achieve advanced reasoning capabilities with fewer parameters than traditional methods. These findings underscore the potential of reinforcement learning to replicate the performance of models like o1, offering insights that could be extended to more generalized reasoning tasks.
Conclusion
The roadmap developed by researchers at Fudan University and the Shanghai ai Laboratory offers a thoughtful approach to improving ai reasoning capabilities. By integrating policy initialization, reward design, search, and learning, it provides a coherent strategy to replicate o1's capabilities. This framework not only addresses existing limitations but also lays the foundation for scalable and efficient ai systems capable of handling complex reasoning tasks. As research progresses, this roadmap serves as a guide to building more robust and generalizable models, contributing to the broader goal of advancing artificial intelligence.
Verify he Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on <a target="_blank" href="https://twitter.com/Marktechpost”>twitter and join our Telegram channel and LinkedIn Grabove. Don't forget to join our SubReddit over 60,000 ml.
UPCOMING FREE ai WEBINAR (JANUARY 15, 2025): <a target="_blank" href="https://info.gretel.ai/boost-llm-accuracy-with-sd-and-evaluation-intelligence?utm_source=marktechpost&utm_medium=newsletter&utm_campaign=202501_gretel_galileo_webinar”>Increase LLM Accuracy with Synthetic Data and Assessment Intelligence–<a target="_blank" href="https://info.gretel.ai/boost-llm-accuracy-with-sd-and-evaluation-intelligence?utm_source=marktechpost&utm_medium=newsletter&utm_campaign=202501_gretel_galileo_webinar”>Join this webinar to learn practical information to improve LLM model performance and accuracy while protecting data privacy..
Aswin AK is a consulting intern at MarkTechPost. He is pursuing his dual degree from the Indian Institute of technology Kharagpur. He is passionate about data science and machine learning, and brings a strong academic background and practical experience solving real-life interdisciplinary challenges.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>





{kind=link}