 NEWSLETTER
NEWSLETTER
Scaling machine learning (ML) workflows from early prototypes to a full-scale production deployment can be a daunting task, but the integration of amazon SageMaker Studio and amazon SageMaker HyperPod offers a streamlined solution to this challenge. As teams progress from proof of concept to production-ready models, they often struggle to efficiently manage growing infrastructure and storage needs. This integration addresses these obstacles by providing data scientists and ML engineers with a comprehensive environment that supports the entire ML lifecycle, from development to deployment at scale.
In this post, we walk you through the process of scaling your ML workloads using SageMaker Studio and SageMaker HyperPod.
Solution Overview
Implementing the solution consists of the following high-level steps:
- Configure your environment and permissions to access amazon HyperPod clusters in SageMaker Studio.
- Create a JupyterLab space and mount an amazon FSx for Luster file system on your space. This eliminates the need to migrate data or change code as you scale. This also mitigates potential reproducibility issues that often arise from data discrepancies at different stages of model development.
- You can now use SageMaker Studio to discover SageMaker HyperPod clusters and view cluster details and metrics. When you have access to multiple clusters, this information can help you compare each cluster's specifications, current utilization, and queue status of the clusters to identify which one meets the requirements of your specific machine learning task.
- We use a sample notebook to show how to connect to the cluster and run a Meta Llama 2 training job with PyTorch FSDP on your Slurm cluster.
- After you submit the long-running job to the cluster, you can monitor the tasks directly through the SageMaker Studio user interface. This can help you gain real-time insights into your distributed workflows and allow you to quickly identify bottlenecks, optimize resource utilization, and improve overall workflow efficiency.
This integrated approach not only streamlines the transition from prototype to full-scale training, but also improves overall productivity by maintaining a familiar development experience even when scaling to production-grade workloads.
Prerequisites
Complete the following preliminary steps:
- Create a SageMaker HyperPod Slurm cluster. For instructions, see the amazon SageMaker HyperPod Workshop o Tutorial to get started with SageMaker HyperPod.
- Make sure you have the latest version of the AWS Command Line Interface (AWS CLI).
- Create a user on the Slurm master node or login node with a UID greater than 10000. See Multi-user for instructions on creating a user.
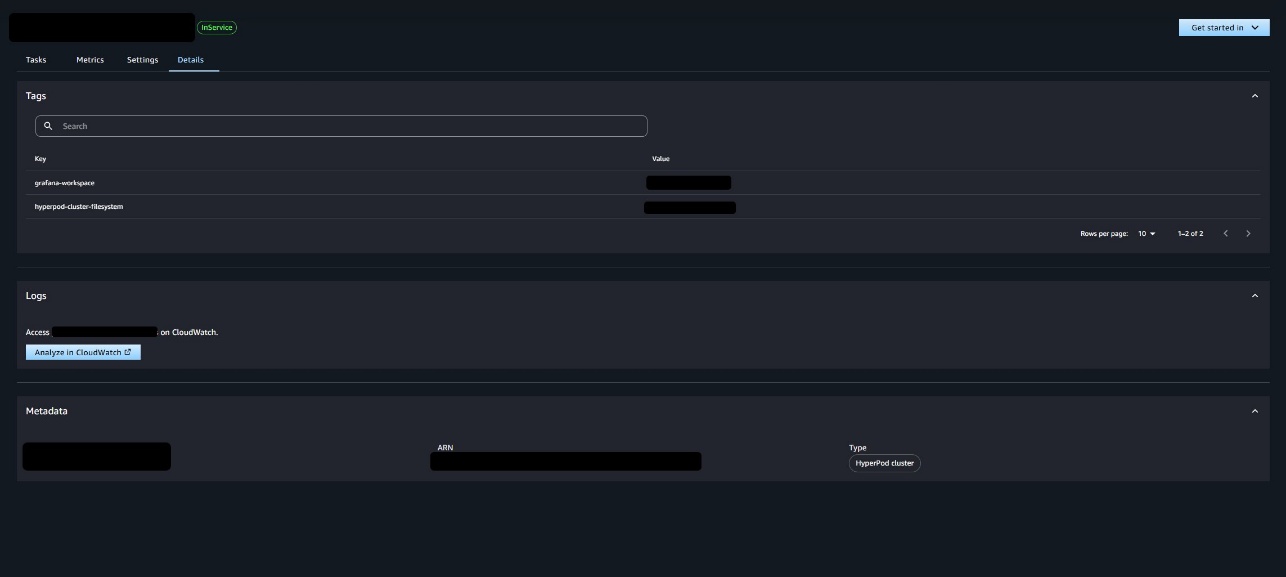
- Tag the SageMaker HyperPod cluster with the key
hyperpod-cluster-filesystem. This is the ID of the FSx for Luster file system associated with the SageMaker HyperPod cluster. This is required for amazon SageMaker Studio to mount FSx for Luster in the Jupyter Lab and Code Editor spaces. Use the following code snippet to add a tag to an existing SageMaker HyperPod cluster:
Set your permissions
In the following sections, we describe the steps to create an amazon SageMaker domain, create a user, configure a SageMaker Studio space, and connect to the SageMaker HyperPod cluster. At the end of these steps, you should be able to connect to a SageMaker HyperPod Slurm cluster and run a sample training workload. To follow the setup instructions, you must have administrator privileges. Complete the following steps:
- Create a new AWS Identity and Access Management (IAM) execution role with AmazonSageMakerFullAccess attached to the role. Also attach the following JSON policy to the function, which allows SageMaker Studio to access the SageMaker HyperPod cluster. Ensure that the trust relationship in the role allows the
sagemaker.amazonaws.comservice to assume this role.
- To use the role that you created to access the SageMaker HyperPod cluster head or login node using AWS Systems Manager, you must add a tag to this IAM role, where
Tag Key = “SSMSessionRunAs”andTag Value = “”. The POSIX user is the user that is configured on the Slurm master node. Systems Manager uses this user to run on the primary node. - When you enable Run As support, you prevent Session Manager from starting sessions using the
ssm-useraccount on a managed node. To enable Run As in Session Manager, complete the following steps:- In the Session Manager console, choose Preferencesthen choose Edit.
- Do not specify any username. The username will be selected from the role tag.
SSMSessionRunAsthat you created previously. - In it Linux shell profile section, enter /bin/bash.
- Choose Save.
- Create a new SageMaker Studio domain with the launch role created above along with other parameters required to access the SageMaker HyperPod cluster. Use the following script to create the domain and replace the export variables accordingly. Here,
VPC_IDandSubnet_IDThey are the same as the VPC and subnet of the SageMaker HyperPod cluster. HeEXECUTION_ROLE_ARNis the role you created previously.
The UID and GID in the above configuration are set to 10000 and 1001 default; this can be overridden based on the user created in Slurm, and this UID/GID is used to grant permissions to the FSx file system for Luster. Additionally, setting this at the domain level gives each user the same UID. To have a separate UID for each user, consider setting CustomPosixUserConfig when creating the user profile.
- After creating the domain, you must attach
SecurityGroupIdForInboundNfscreated as part of domain creation for all ENIs on the FSx Luster volume:- Locate the amazon Elastic File System (amazon EFS) file system associated with the domain and the corresponding security group attached. You can find the EFS file system in the amazon EFS console; is labeled with the domain ID, as shown in the following screenshot.
- Pick up the corresponding security group, which will be called
inbound-nfs-and can be found in the Grid eyelash.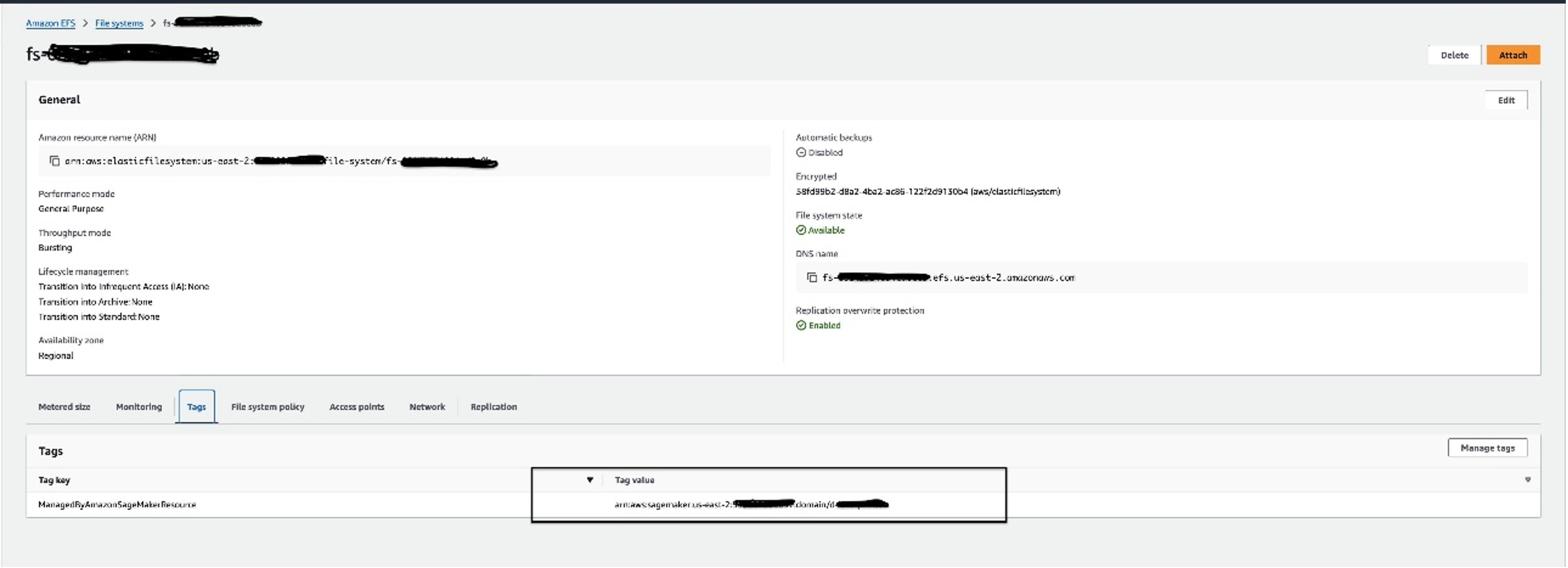
- In the FSx for Luster console, choose To view all ENIs, see the amazon EC2 console. This will show all ENIs attached to FSx for Luster. Alternatively, you can find ENI using the AWS CLI or by calling
fsx:describeFileSystems - For each ENI, attach the
SecurityGroupIdForInboundNfsfrom the domain to this one.
Alternatively, you can use the following script to automatically find and attach security groups to the ENIs associated with the FSx for Luster volume. Replace the REGION, DOMAIN_IDand FSX_ID attributes accordingly.
Without this step, the application creation will fail and generate an error.
- After creating the domain, you can use it to create a user profile. Replace the DOMAIN_ID value with the one created in the previous step.
Create a JupyterLab space and mount the FSx filesystem for Luster
Create a space using the FSx file system for Luster with the following code:
Create an app using space with the following code:
Discover clusters in SageMaker Studio
You should now be ready to access the SageMaker HyperPod cluster using SageMaker Studio. Complete the following steps:
- In the SageMaker console, choose Administrator settings, Domains.
- Locate the user profile you created and start SageMaker Studio.
- Low Calculate In the navigation pane, choose HyperPod Clusters.
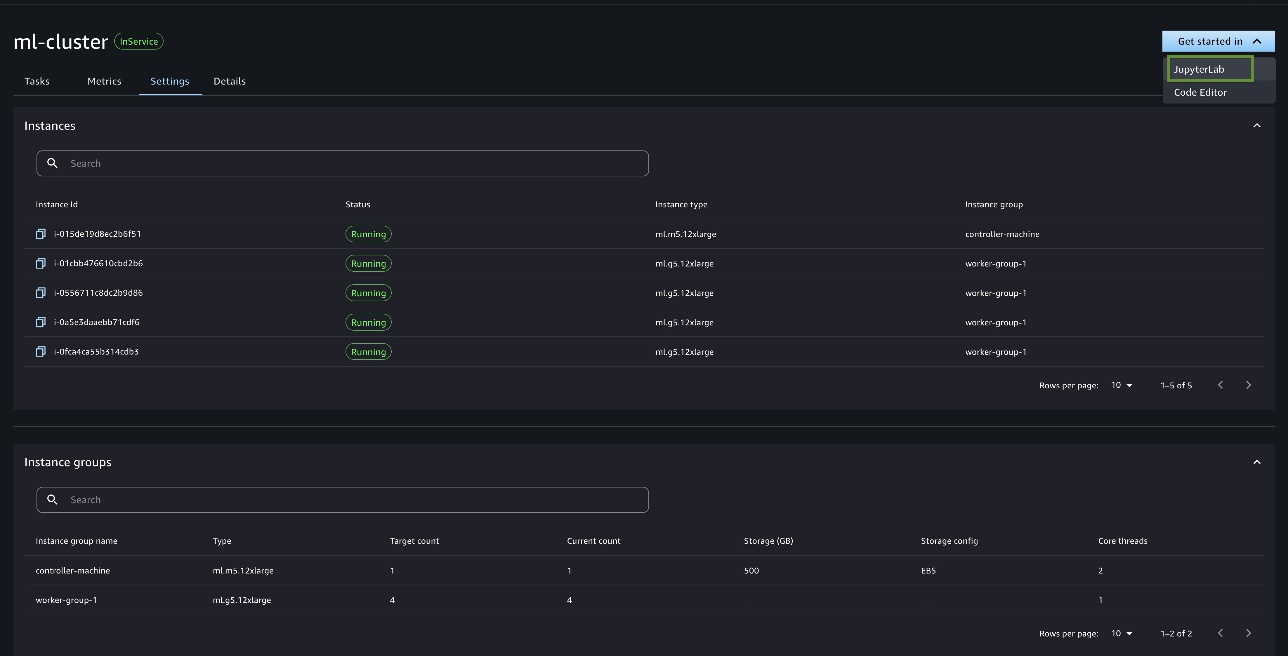
Here you can see the SageMaker HyperPod clusters available in the account.
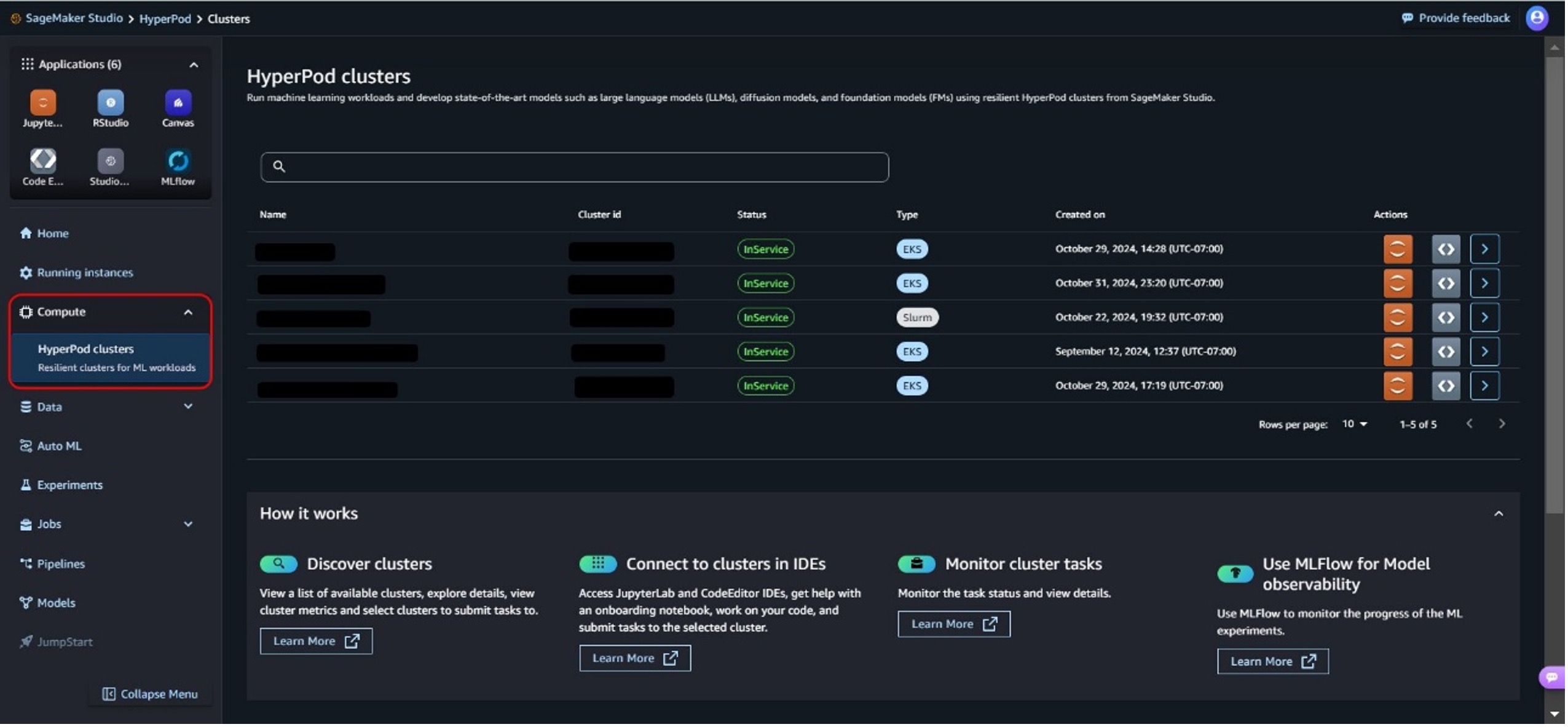
- Identify the right cluster for your training workload by looking at the cluster details and cluster hardware metrics.
You can also preview the cluster by choosing the arrow icon.
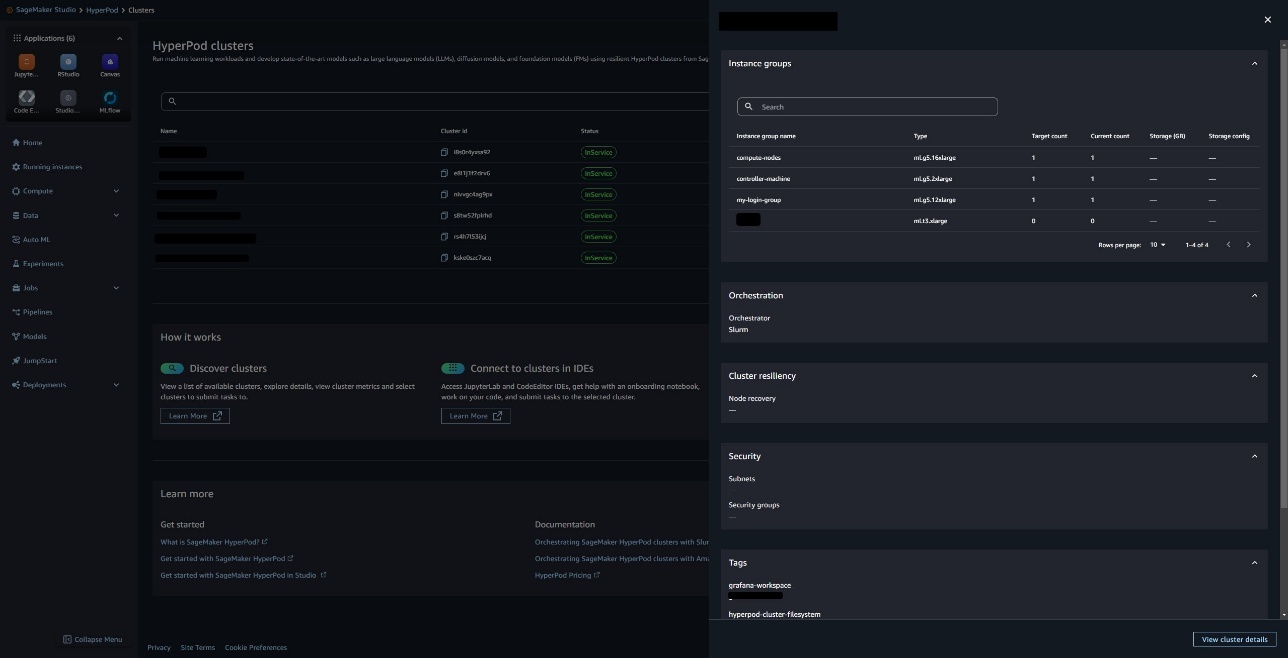
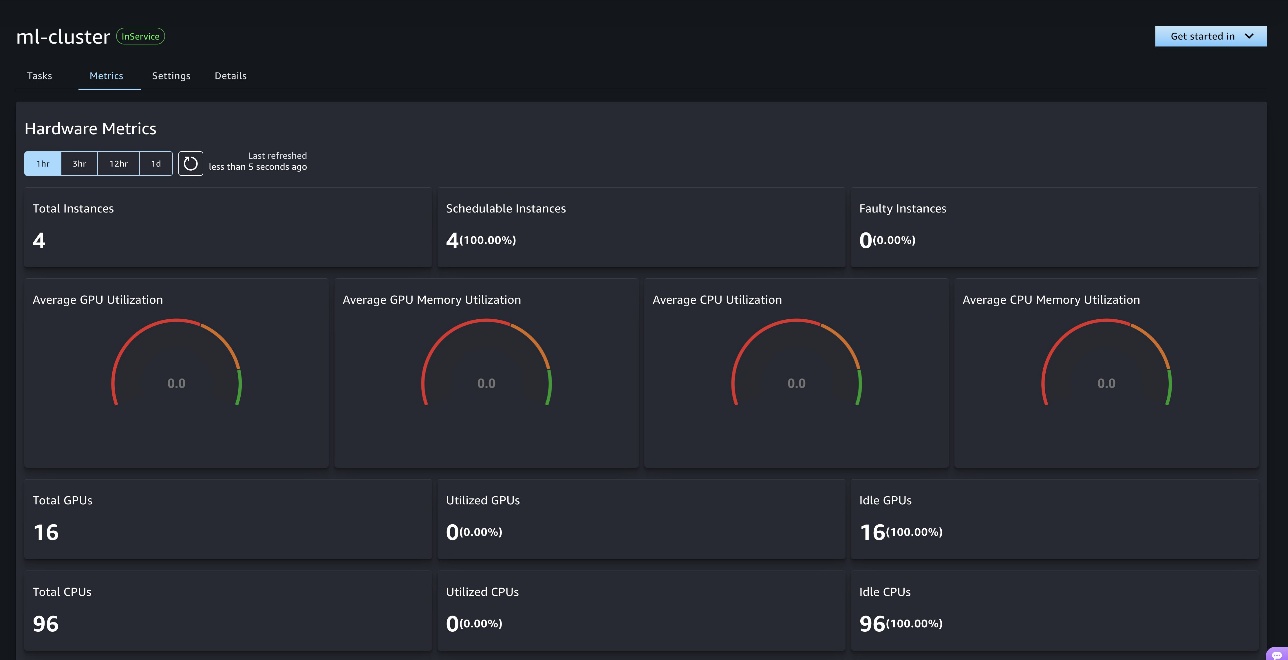
You can also go to Settings and Details tabs to find more information about the cluster.
Work in SageMaker Studio and connect to the cluster
You can also start JupyterLab or Code Editor, which mounts the FSx cluster volume for Luster for development and debugging.
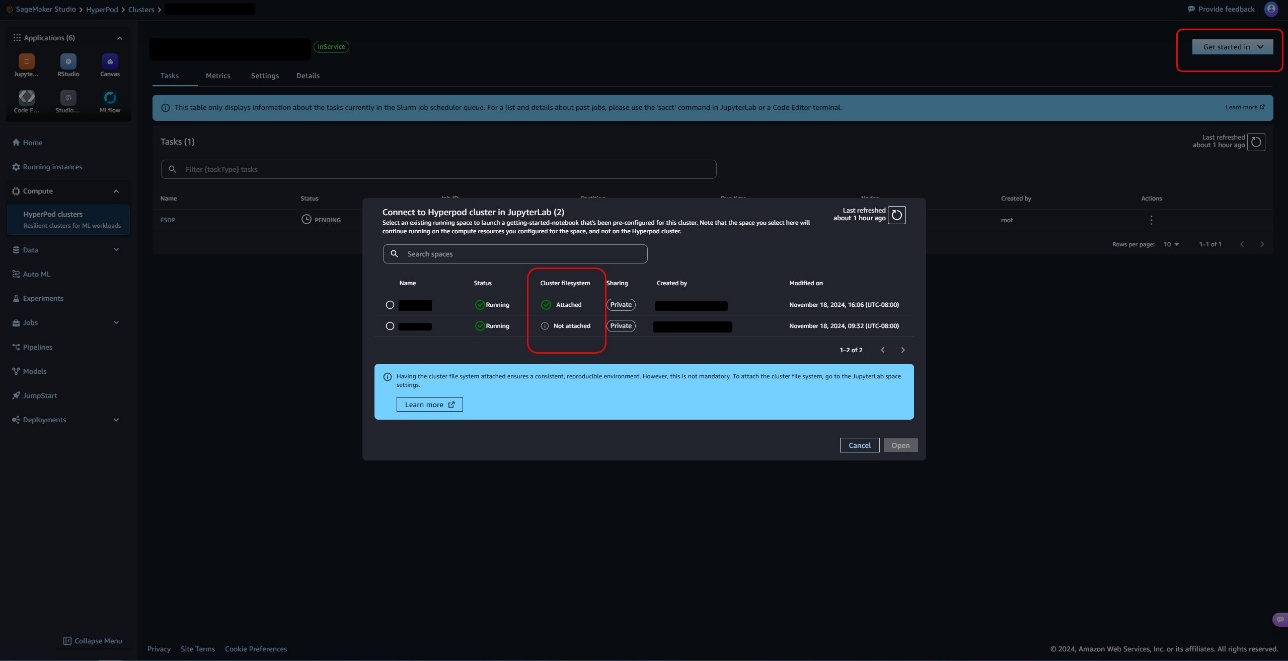
- In SageMaker Studio, choose Start in and choose JupyterLab.
- Choose a space that has the FSx for Luster file system mounted for a consistent and reproducible environment.
He Cluster file system The column identifies which space the cluster file system has mounted.
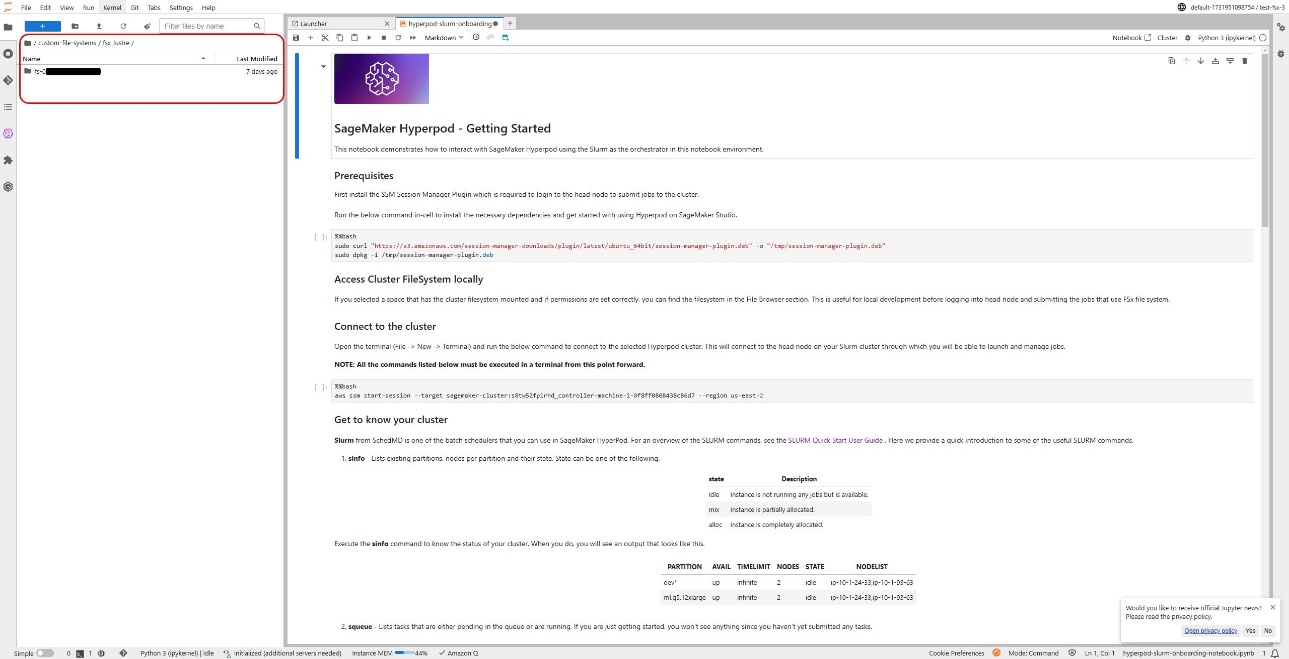
This should start JupyterLab with the FSx for Luster volume mounted. By default, you should see the Getting Started notebook in your home folder, which has step-by-step instructions for running a Meta Llama 2 training job with PyTorch FSDP on the Slurm cluster. This example notebook demonstrates how you can use SageMaker Studio notebooks to transition from prototyping your training script to scaling your workloads across multiple instances in your cluster environment. Additionally, you should see the FSx filesystem for Luster that you mounted in your JupyterLab space in /home/sagemaker-user/custom-file-systems/fsx_lustre.
Monitor tasks in SageMaker Studio
You can go to SageMaker Studio and choose the cluster to see a list of tasks currently in the Slurm queue.
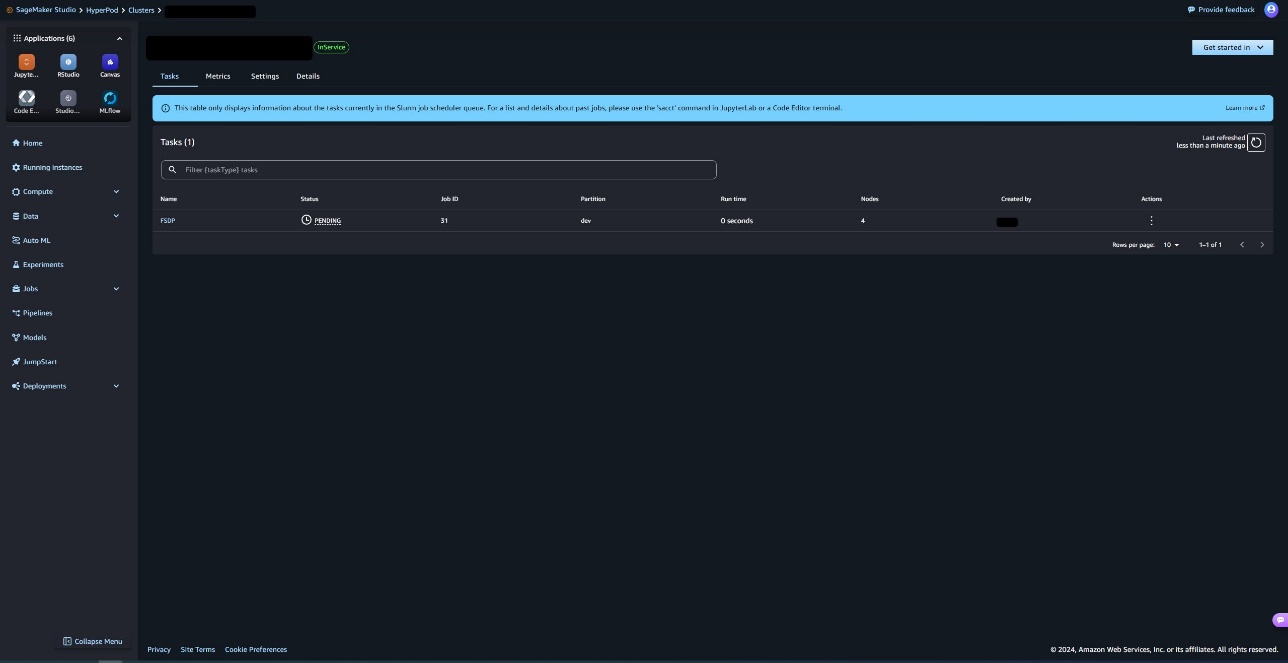
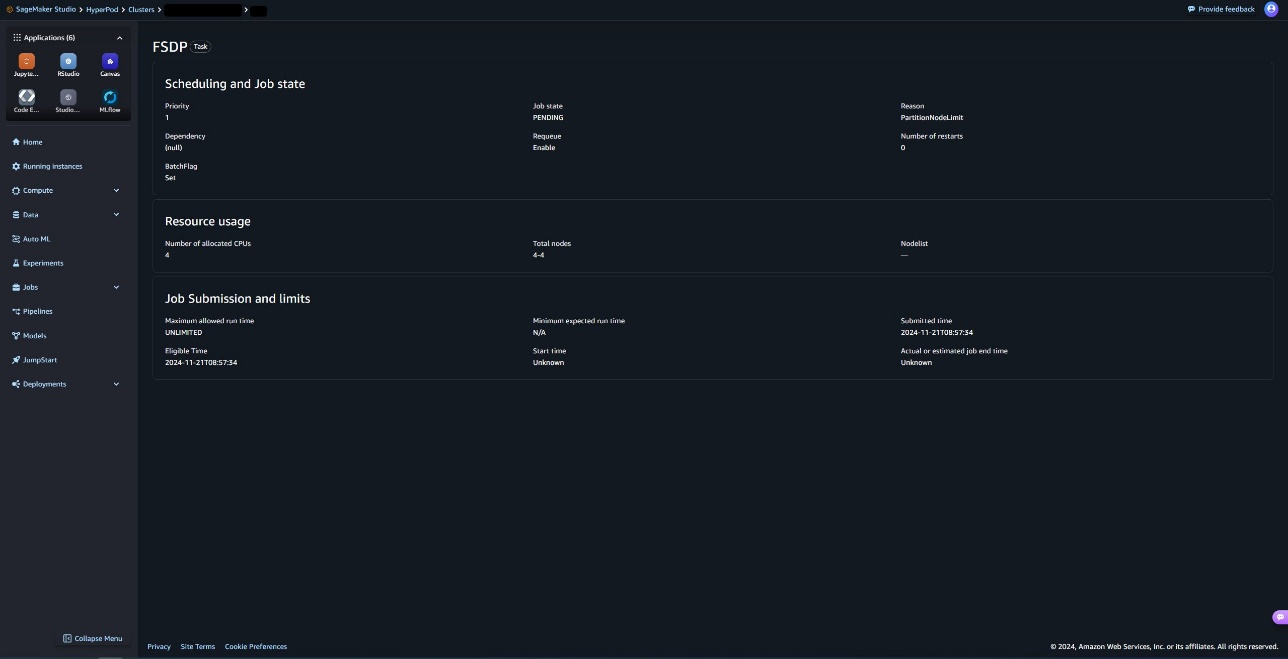
You can choose a task to get additional task details, such as job schedule and status, resource usage and submission details, and job limits.
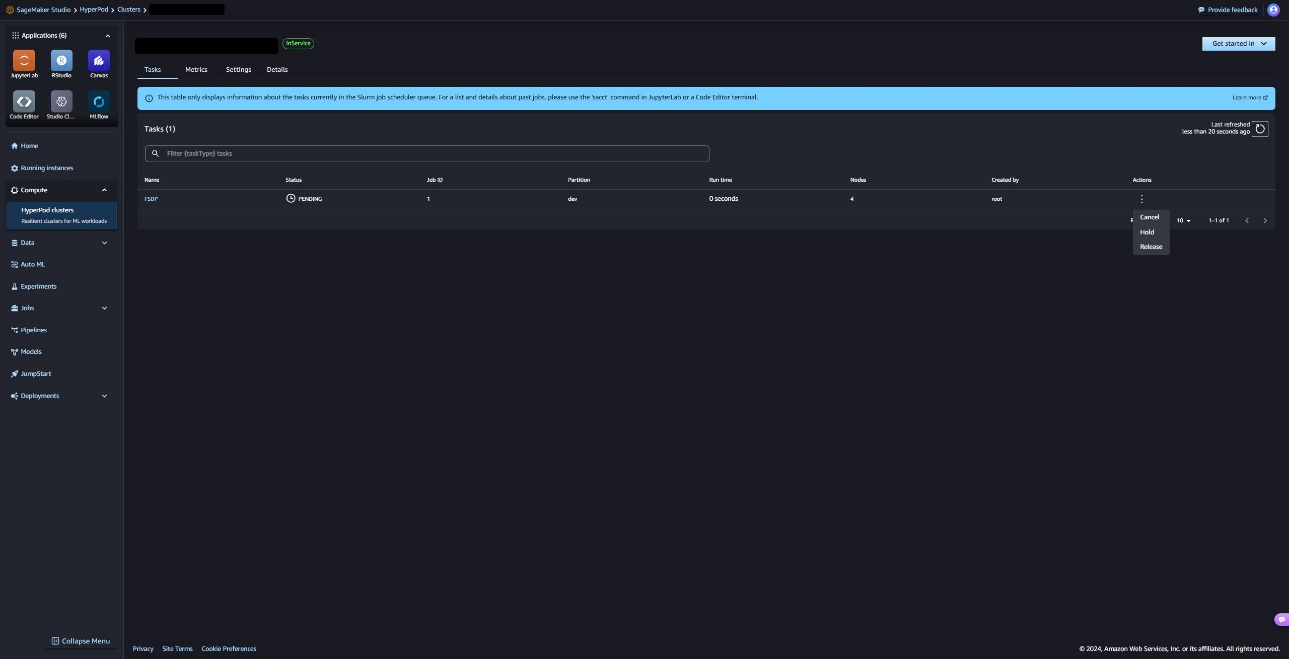
You can also perform actions like release, requeue, suspend, and maintain these Slurm tasks using the user interface.
Clean
Complete the following steps to clean up your resources:
- Delete space:
- Delete user profile:
- Delete the domain. To preserve the EFS volume, specify
HomeEfsFileSystem=Retain.
- Delete the SageMaker HyperPod cluster.
- Delete the IAM role you created.
Conclusion
In this post, we explore one approach to optimizing your ML workflows using SageMaker Studio. We demonstrate how you can seamlessly go from prototyping your training script within SageMaker Studio to scaling your workload across multiple instances in a cluster environment. We also explain how to mount the FSx cluster volume for Luster to your SageMaker Studio spaces for a consistent reproducible environment.
This approach not only streamlines your development process but also allows you to launch long-running jobs on clusters and conveniently monitor their progress directly from SageMaker Studio.
We recommend you try this and share your feedback in the comments section.
Special thanks to Durga Sury (Mr. ML SA), Monidipa Chakraborty (Mr. SDE) and Sumedha Swamy (Mr. Manager PMT) for their support in launching this publication.
About the authors
 Arun Kumar Lokanatha is a Senior Machine Learning Solutions Architect on the amazon SageMaker team. He specializes in large language model training workloads, helping clients build LLM workloads using SageMaker HyperPod, SageMaker training jobs, and SageMaker distributed training. Outside of work, she enjoys running, hiking, and cooking.
Arun Kumar Lokanatha is a Senior Machine Learning Solutions Architect on the amazon SageMaker team. He specializes in large language model training workloads, helping clients build LLM workloads using SageMaker HyperPod, SageMaker training jobs, and SageMaker distributed training. Outside of work, she enjoys running, hiking, and cooking.
 Pooja Karadgi is a senior technical product manager at amazon Web Services. At AWS, he is part of the amazon SageMaker Studio team, helping build products that meet the needs of data managers and data scientists. She began her career as a software engineer before transitioning to product management. Outside of work, he likes to create travel planners in spreadsheets, MBA style. Given the time he puts into creating these planners, it's clear that he has a deep love for travel, as well as a great passion for hiking.
Pooja Karadgi is a senior technical product manager at amazon Web Services. At AWS, he is part of the amazon SageMaker Studio team, helping build products that meet the needs of data managers and data scientists. She began her career as a software engineer before transitioning to product management. Outside of work, he likes to create travel planners in spreadsheets, MBA style. Given the time he puts into creating these planners, it's clear that he has a deep love for travel, as well as a great passion for hiking.





{kind=link}