
The ability to automate and assist in coding has the potential to transform software development, making it faster and more efficient. However, the challenge is to ensure that these models produce useful and secure code. The intricate balance between functionality and security is critical, especially when the generated code could be exploited maliciously.
In practical applications, LLMs often struggle when dealing with ambiguous or malicious instructions. These models can generate code that inadvertently includes security vulnerabilities or facilitates harmful attacks. This problem is not just theoretical; real-world studies have demonstrated significant risks. For example, research on GitHub Copilot revealed that approximately 40% of generated programs contained vulnerabilities. Mitigating these risks is essential to realizing the full potential of LLMs in coding while maintaining security.
Current methods to mitigate these risks include fine-tuning LLMs with security-focused datasets and deploying rule-based detectors to identify patterns of insecure code. While fine-tuning is beneficial, it often proves insufficient against highly sophisticated attack indications. Creating quality security-related data for fine-tuning can be costly and resource-intensive, and involves experts with deep programming and cybersecurity knowledge. While effective, rule-based systems may not cover all potential vulnerabilities, leaving gaps that can be exploited.
Researchers at Salesforce Research introduced a new framework called PROCESSThis framework is designed to improve the safety and utility of code generated by LLMs. INDICT employs a unique mechanism involving internal critique dialogues between two critics: one focused on safety and the other on utility. This dual-critic system allows the model to receive comprehensive feedback, allowing it to refine its output iteratively. Critics are equipped with external knowledge sources, such as relevant code snippets, and tools such as web searches and code interpreters, to provide more informed and effective critiques.
The INDICT framework operates through two main stages: preemptive and post hoc feedback. During the preemptive stage, the safety-oriented critic assesses the potential risks of generating the code. In contrast, the utility-oriented critic ensures that the code aligns with the requirements of the intended task. This stage involves consulting external knowledge sources to supplement the critics' assessments. The post hoc stage reviews the generated code after its execution, allowing the critics to provide additional feedback based on the observed results. This two-stage approach ensures that the model anticipates potential problems and learns from the execution results to improve future results.
The evaluation of INDICT involved testing on eight different tasks in eight programming languages using LLMs ranging from 7 billion to 70 billion parameters. The results demonstrated significant improvements in both security and utility metrics. Specifically, the framework achieved a 10% absolute improvement in code quality across all tested models. For example, in the CyberSecEval-1 benchmark, INDICT improved the security of the generated code by up to 30%, and security measures indicated that over 90% of the results were secure. The utility metric also showed substantial improvements, with INDICT-enhanced models outperforming state-of-the-art baselines by up to 70%.
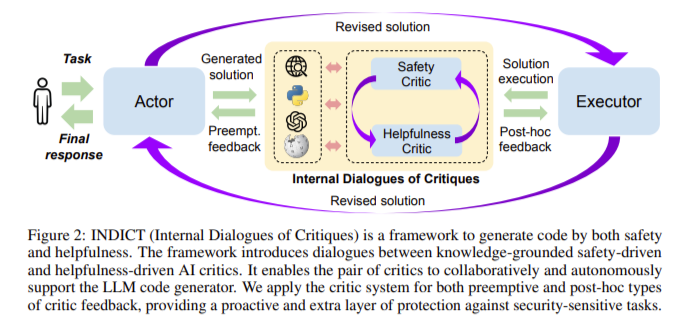
The success of INDICT lies in its ability to provide detailed and contextual feedback that guides LLMs to produce better code. The framework ensures that generated code is safe and functional by integrating security and useful feedback. This approach offers a more robust solution to the challenges of code generation by LLMs.
In conclusion, INDICT presents an innovative framework for improving the safety and utility of LLM-generated code. INDICT addresses the critical trade-off between functionality and safety in code generation by employing a dual-criterion system and leveraging external knowledge sources. The framework’s impressive performance across multiple benchmarks and programming languages highlights its potential to set new standards for responsible ai in coding.
Review the Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter.
Join our Telegram Channel and LinkedIn GrAbove!.
If you like our work, you will love our Newsletter..
Don't forget to join our Subreddit with over 46 billion users
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary engineer and entrepreneur, Asif is committed to harnessing the potential of ai for social good. His most recent initiative is the launch of an ai media platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is technically sound and easily understandable to a wide audience. The platform has over 2 million monthly views, illustrating its popularity among the public.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}