 NEWSLETTER
NEWSLETTER
Retrieval-augmented generation (RAG) systems combine retrieval and generation processes to address the complexities of answering open-ended, multidimensional questions. By accessing relevant documents and knowledge, RAG-based models generate responses with additional context, offering richer insights than generative-only models. This approach is useful in fields where answers must reflect a broad base of knowledge, such as legal research and academic analysis. RAG systems retrieve specific data and assemble it into comprehensive responses, which is particularly advantageous in situations that require diverse perspectives or deep context.
Evaluating the effectiveness of RAG systems presents unique challenges, as they often need to answer non-factual questions that require more than one definitive answer. Traditional evaluation metrics, such as relevance and fidelity, must fully capture how well these systems cover the complex, multi-layered subtopics of these questions. In real-world applications, questions often comprise basic queries supported by additional contextual or exploratory elements, forming a more holistic answer. Existing tools and models focus primarily on surface-level measures, leaving a gap in understanding the integrity of RAG responses.
Most current RAG systems operate with general quality indicators that only partially address users' needs for comprehensive coverage. Tools and frameworks often incorporate sub-question hints, but need help to fully decompose a question into detailed sub-topics, which impacts user satisfaction. Complex queries may require responses that encompass not only direct answers but also background and follow-up details for clarity. Requiring detailed coverage assessment, these systems often overlook or inadequately integrate essential information into their generated responses.
Researchers at the Georgia Institute of technology and Salesforce ai Research present a new framework for evaluating RAG systems based on a metric called “sub-question coverage.” Instead of general relevance scores, the researchers propose decomposing a question into specific subquestions, categorized as core, background, or follow-up. This approach allows for a nuanced assessment of response quality by examining how well each subquestion is addressed. The team applied their framework to three widely used RAG systems, You.com, Perplexity ai, and Bing Chat, revealing distinct patterns in the handling of various types of subquestions. Researchers were able to identify gaps where each system failed to provide comprehensive responses by measuring coverage in these categories.
In developing the framework, the researchers employed a two-step approach as follows:
- First, they divided the complex questions into subquestions with roles categorized as core (essential to the main question), background (providing necessary context), or follow-up (non-essential but valuable for more information).
- Next, they tested how well the RAG systems retrieved relevant content for each category and how effectively it was incorporated into the final responses. For example, the recovery capabilities of each system were examined in terms of core subquestions, where adequate coverage often predicts the overall success of the response.
The metrics developed through this process provide accurate information about the strengths and limitations of RAG systems, allowing for targeted improvements.
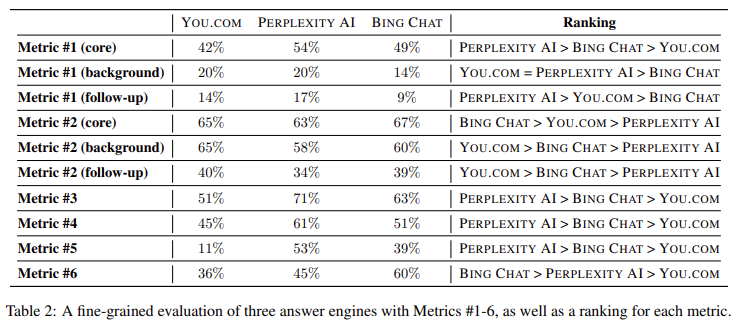
The results revealed significant trends between the systems, highlighting both the strengths and limitations of their capabilities. Although each GAR system prioritized core subquestions, none achieved complete coverage and gaps persisted even in critical areas. On You.com, coverage of top sub-questions was 42%, while Perplexity ai performed better, reaching 54% coverage. Bing Chat showed a slightly lower rate of 49%, although it excelled in organizing information in a coherent way. However, coverage of background subquestions was notably low across all systems, at 20% for You.com and Perplexity ai and just 14% for Bing Chat. This disparity reveals that, while the main content is prioritized, systems often need to pay more attention to supplementary information, which affects the quality of the response perceived by users. Additionally, the researchers noted that Perplexity ai excelled at connecting the retrieval and generation stages, achieving 71% accuracy in aligning the main sub-questions, while You.com lagged behind at 51%.
This study highlights that the evaluation of RAG systems requires a shift from conventional methods to sub-question-oriented metrics that evaluate retrieval accuracy and response quality. By integrating subquestion classification into RAG processes, the framework helps close gaps in existing systems, improving their ability to produce comprehensive responses. The results show that leveraging the main subquestions in retrieval can substantially raise the quality of the response; Perplexity ai demonstrates a 74% success rate on a baseline that excluded sub-questions. Importantly, the study identified areas for improvement, such as Bing Chat's need to increase the consistency of aligning core and background information.
Key findings from this research underscore the importance of subquestion classification to improve RAG performance:
- Coverage of main sub-questions: On average, RAG systems missed about 50% of the main sub-questions, indicating a clear area for improvement.
- System Accuracy: Perplexity ai led with 71% accuracy in connecting retrieved content to responses, compared to 51% for You.com and 63% for Bing Chat.
- Importance of prior information: Coverage of background subquestions was lower across systems, ranging from 14% to 20%, suggesting a gap in contextual support for responses.
- Performance Ratings: Perplexity ai ranked highest overall, with Bing Chat excelling at structuring responses and You.com showing notable limitations.
- Improvement potential: All RAG systems showed substantial room to improve recall of major subquestions, with projected gains in response quality of up to 45%.
In conclusion, this research redefines how RAG systems are evaluated, emphasizing subquestion coverage as a primary success metric. By analyzing specific types of subquestions within responses, the study sheds light on the limitations of current RAG frameworks and offers a path to improving response quality. The findings highlight the need for focused retrieval augmentation and point to practical steps that could make RAG systems more robust for complex, knowledge-intensive tasks. The research lays the foundation for future improvements in response generation technology through this nuanced assessment approach.
look at the Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter and join our Telegram channel and LinkedIn Grabove. If you like our work, you will love our information sheet.. Don't forget to join our SubReddit over 55,000ml.
(Next live webinar: October 29, 2024) Best platform to deliver optimized models: Predibase inference engine (promoted)
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of artificial intelligence for social good. Their most recent endeavor is the launch of an ai media platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is technically sound and easily understandable to a wide audience. The platform has more than 2 million monthly visits, which illustrates its popularity among the public.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}