
Large language models (LLMs), useful for answering questions and generating content, are now being trained to handle tasks that require advanced reasoning, such as solving complex problems in mathematics, science, and logical deduction. Improving reasoning capabilities within LLMs is a central focus of ai research, which aims to empower models to carry out sequential thinking processes. Improving this area could enable more robust applications in various fields by allowing models to navigate through complex reasoning tasks independently.
A persistent challenge in developing LLMs is optimizing their reasoning abilities without external feedback. Current LLMs perform well on relatively simple tasks, but need help with sequential or multi-step reasoning, where an answer is derived through a series of connected logical steps. This limitation restricts the usefulness of LLMs in tasks that require a logical progression of ideas, such as solving complex mathematical problems or analyzing data in a structured way. Consequently, developing self-sufficient reasoning capabilities in LLMs has become essential to expand their functionality and effectiveness in tasks where reasoning is key.
Researchers have experimented with various inference timing methods to address these challenges and improve reasoning. A prominent approach is the Chain of Thought (CoT) stimulus, which encourages the model to break down a complex problem into manageable parts, taking each decision step by step. This method allows models to follow a structured approach to problem solving, making them better suited for tasks that require logic and precision. Other approaches, such as the thinking tree and the thinking program, allow LLMs to explore multiple paths of reasoning, providing diverse approaches to problem solving. While effective, these methods primarily focus on runtime improvements and do not fundamentally improve reasoning ability during the model training phase.
Researchers at Salesforce ai Research have introduced a new framework called LaTent Reasoning Optimization (LaTRO). LaTRO is an innovative approach that transforms the reasoning process into a latent sampling problem, offering an intrinsic improvement to the model's reasoning capabilities. This framework allows LLMs to hone their reasoning pathways through a self-reward mechanism, allowing them to evaluate and improve their responses without relying on external rewards or supervised feedback. By focusing on a self-improvement strategy, LaTRO improves training-level reasoning performance, creating a fundamental shift in the way models understand and approach complex tasks.
The LaTRO methodology is based on sampling reasoning paths from a latent distribution and optimizing these paths using variational techniques. LaTRO uses a unique self-reward mechanism at its core by sampling multiple reasoning paths for a given question. Each path is evaluated based on its probability of producing a correct response, and then the model adjusts its parameters to prioritize paths with higher success rates. This iterative process allows the model to simultaneously improve its ability to generate quality reasoning paths and evaluate the effectiveness of these paths, thus fostering a continuous cycle of self-improvement. Unlike conventional approaches, LaTRO does not rely on external reward models, making it a more autonomous and adaptable framework for improving reasoning in LLMs. Furthermore, by moving reasoning optimization to the training phase, LaTRO effectively reduces computational demands during inference, making it a resource-saving solution.

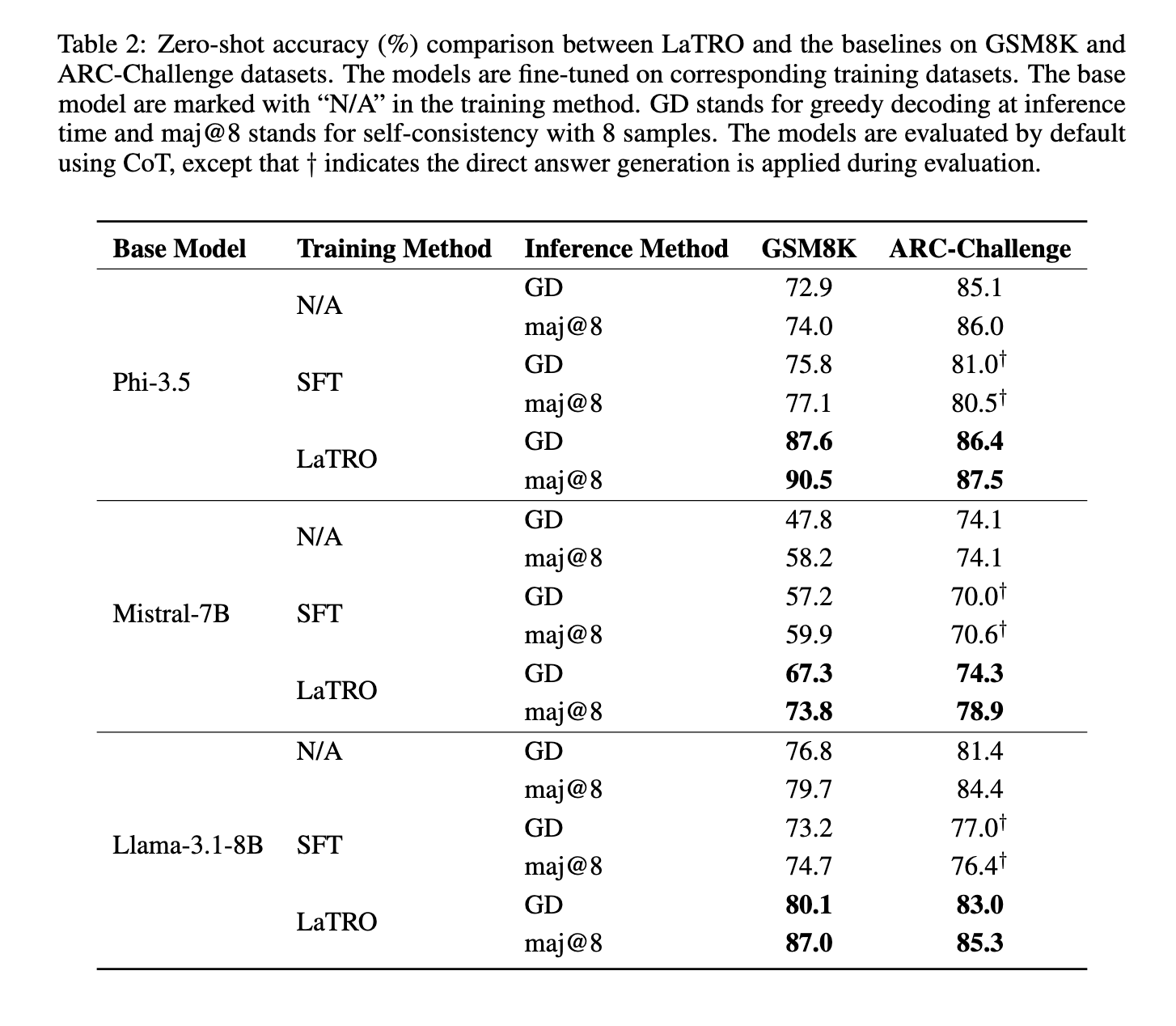
The performance of LaTRO has been rigorously tested on multiple data sets, and the results underline its effectiveness. For example, in tests on the GSM8K dataset, which includes math-based reasoning challenges, LaTRO demonstrated a substantial 12.5% improvement over the base models in zero-shot accuracy. This gain indicates a marked improvement in the model's reasoning ability without requiring task-specific training. Furthermore, LaTRO outperformed supervised fine-tuning models by 9.6%, demonstrating its ability to deliver more accurate results while maintaining efficiency. On the ARC-Challenge dataset, which focuses on logical reasoning, LaTRO again outperformed both the basic and enhanced models, significantly increasing performance. For Mistral-7B, one of the LLM architectures used, the zero-shot accuracy on GSM8K improved from 47.8% on the base models to 67.3% on LaTRO with greedy decoding. In self-consistency tests, where multiple reasoning paths are considered, LaTRO achieved a further performance boost, with a remarkable 90.5% accuracy for Phi-3.5 models on GSM8K.
In addition to the quantitative results, LaTRO's self-rewarding mechanism is evident in its qualitative improvements. The method effectively teaches LLMs to evaluate reasoning paths internally, producing concise and logically coherent responses. Experimental analysis reveals that LaTRO enables LLMs to better utilize their latent reasoning potential, even in complex scenarios, thereby reducing dependence on external assessment frameworks. This advance has implications for many applications, especially in fields where logical coherence and structured reasoning are essential.
In conclusion, LaTRO offers an innovative and effective solution to improve LLM reasoning through self-rewarding optimization, setting a new standard for self-improvement models. This framework allows pre-trained LLMs to unlock their latent potential in reasoning tasks by focusing on reasoning improvement during training time. This advancement from Salesforce ai Research highlights the potential for autonomous reasoning in ai models and demonstrates that LLMs can evolve on their own to become more effective problem solvers. LaTRO represents an important leap forward, bringing ai closer to achieving autonomous reasoning capabilities across multiple domains.
look at the Paper and GitHub page. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on <a target="_blank" href="https://twitter.com/Marktechpost”>twitter and join our Telegram channel and LinkedIn Grabove. If you like our work, you will love our information sheet.. Don't forget to join our SubReddit over 55,000ml.
(<a target="_blank" href="https://landing.deepset.ai/webinar-implementing-idp-with-genai-in-financial-services?utm_campaign=2411%20-%20webinar%20-%20credX%20-%20IDP%20with%20GenAI%20in%20Financial%20Services&utm_source=marktechpost&utm_medium=newsletter” target=”_blank” rel=”noreferrer noopener”>FREE WEBINAR on ai) <a target="_blank" href="https://landing.deepset.ai/webinar-implementing-idp-with-genai-in-financial-services?utm_campaign=2411%20-%20webinar%20-%20credX%20-%20IDP%20with%20GenAI%20in%20Financial%20Services&utm_source=marktechpost&utm_medium=newsletter” target=”_blank” rel=”noreferrer noopener”>Implementation of intelligent document processing with GenAI in financial services and real estate transactions
Nikhil is an internal consultant at Marktechpost. He is pursuing an integrated double degree in Materials at the Indian Institute of technology Kharagpur. Nikhil is an ai/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in materials science, he is exploring new advances and creating opportunities to contribute.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}