 NEWSLETTER
NEWSLETTER
Developing effective multimodal ai systems for real-world applications requires handling various tasks, such as fine-grained recognition, visual basis, reasoning, and multi-step problem solving. Existing open source multimodal language models are poor in these areas, especially for tasks that involve external tools such as OCR or mathematical calculations. The aforementioned limitations can largely be attributed to single-step oriented data sets that cannot provide a coherent framework for multiple steps of reasoning and logical chains of actions. Overcoming them will be essential to unlock the true potential of using multimodal ai at complex levels.
Current multimodal models often rely on instruction matching with direct response data sets or few-trial prompting approaches. Proprietary systems, such as GPT-4, have demonstrated the ability to reason effectively across CoTA chains. At the same time, open source models face challenges due to a lack of data sets and integration with tools. Previous efforts, such as LLaVa-Plus and Visual Program Distillation, were also limited by small data sets, poor quality training data, and a focus on simple question-answering tasks, limiting them to more complex multimodal problems that require more sophisticated reasoning and application of tools.
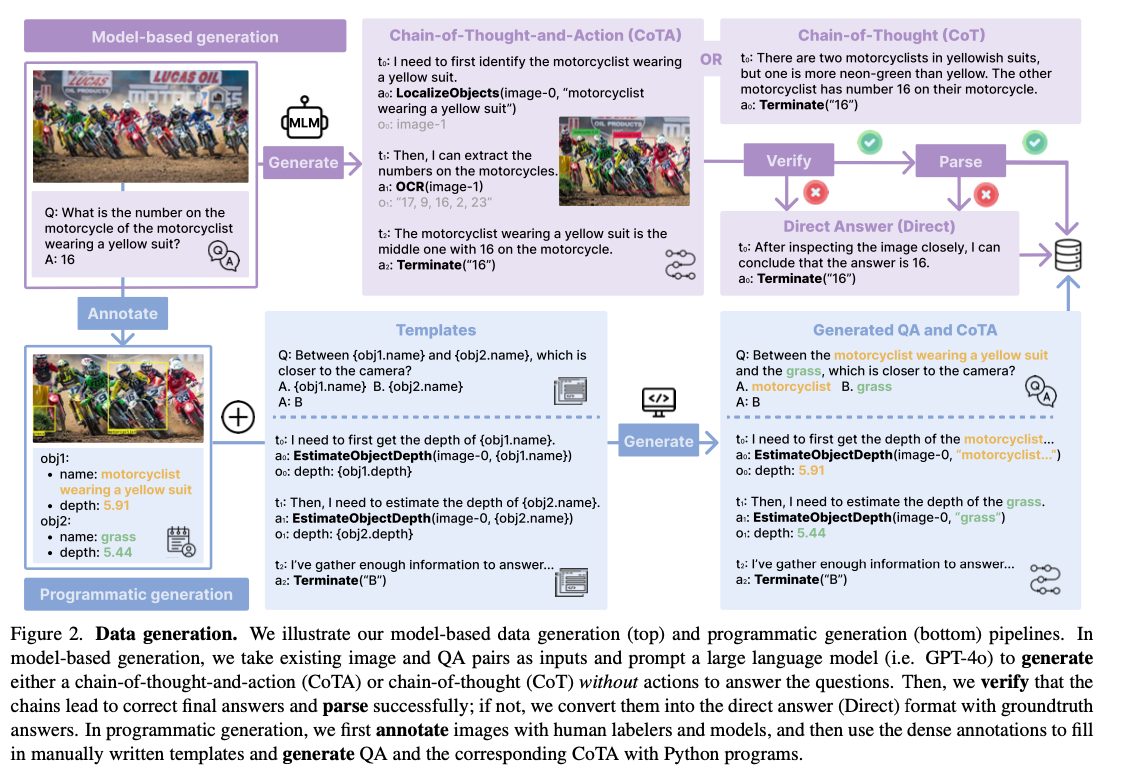
Researchers at the University of Washington and Salesforce Research have developed TACO, an innovative framework for training multimodal action models using synthetic CoTA data sets. This work introduces several key advances to address the limitations of previous methods. First, more than 1.8 million traces were generated using GPT-4 and Python programs, while a subset of 293,000 examples were selected to present high quality after rigorous filtering techniques. These examples ensure the inclusion of diverse sequences of reasoning and action fundamental to multimodal learning. Second, TACO incorporates a robust set of 15 tools, including OCR, object localization, and mathematical solvers, allowing models to handle complex tasks effectively. Third, advanced data filtering and combining techniques further optimize the data set, emphasizing reasoning-action integration and fostering superior learning outcomes. This framework reinterprets multimodal learning by allowing models to produce coherent multi-step reasoning while seamlessly integrating actions, thereby setting a new benchmark for performance in complex scenarios.
The development of TACO involved training on a carefully curated CoTA dataset with 293,000 instances coming from 31 different sources, including Visual Genome. These data sets contain a wide range of tasks, such as mathematical reasoning, optical character recognition, and detailed visual understanding. It is very heterogeneous and the tools provided include object localization and language-based solvers that enable a wide range of reasoning and action tasks. The training architecture combined LLaMA3 as a linguistic base with CLIP as a visual encoder, thus establishing a robust multimodal framework. Fine tuning established hyperparameter tuning that focused on reducing learning rates and increasing the number of training epochs to ensure that the models could adequately solve complex multimodal challenges.
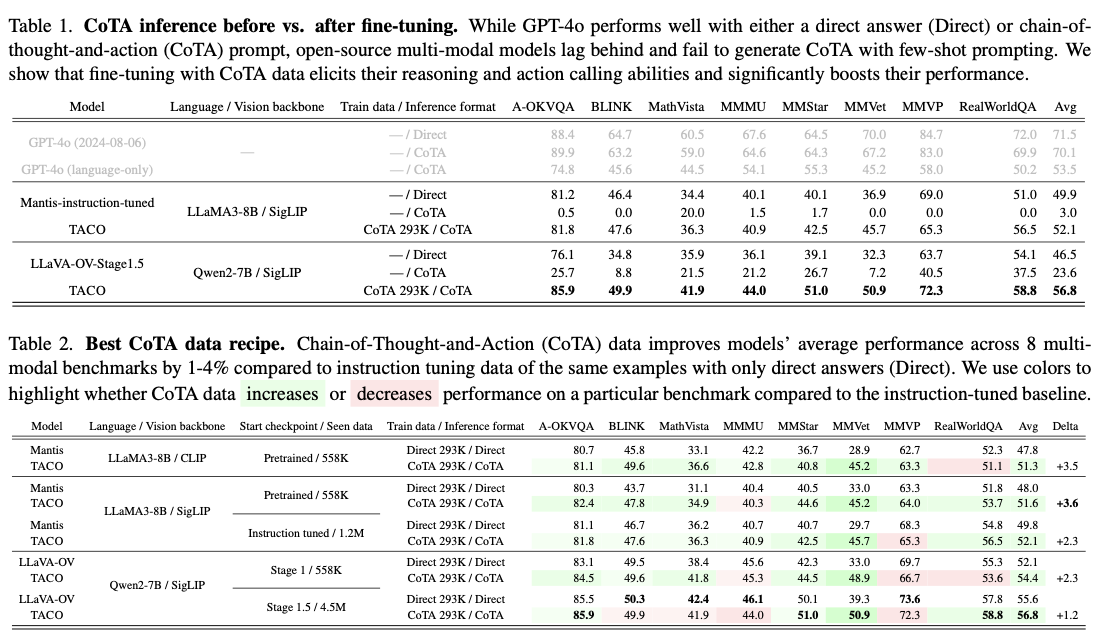
TACO's performance on eight benchmarks demonstrates its substantial impact on advancing multimodal reasoning capabilities. The system achieved an average accuracy improvement of 3.6% over instruction-adjusted baselines, with gains of up to 15% on MMVet tasks involving OCR and mathematical reasoning. In particular, the high-quality CoTA 293K data set outperformed larger, less refined data sets, underscoring the importance of targeted data curation. Additional performance improvements are achieved through adjustments to hyperparameter strategies, including tuning vision encoders and optimizing learning rates. Table 2: Results show excellent performance of TACO compared to benchmarks; The latter was found to be exceptionally better on complex tasks involving the integration of reasoning and action.
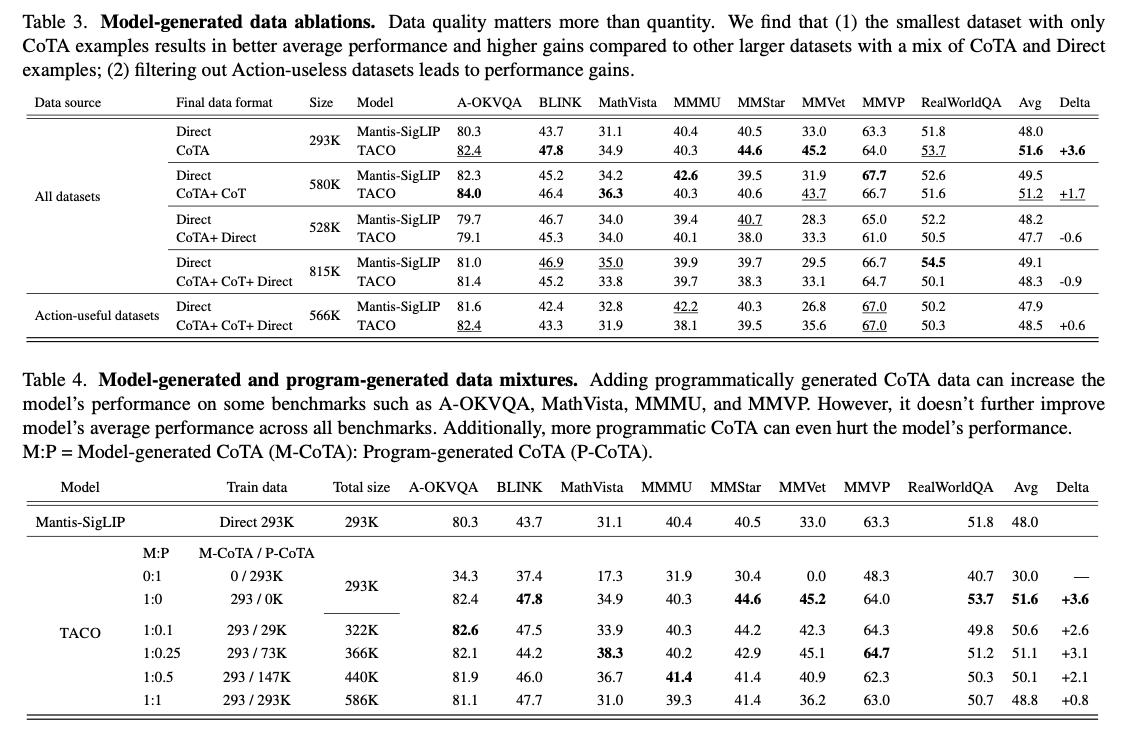

TACO introduces a new methodology for multimodal action modeling that effectively addresses serious shortcomings in both tool-based reasoning and actions through high-quality synthetic data sets and innovative training methodologies. The research overcomes the limitations of traditional instructional-tuned models and its developments are poised to change the face of real-world applications, ranging from visual question answering to complex, multi-step reasoning tasks.
look at the Paper, GitHub page, and Project page. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on <a target="_blank" href="https://x.com/intent/follow?screen_name=marktechpost” target=”_blank” rel=”noreferrer noopener”>twitter and join our Telegram channel and LinkedIn Grabove. Don't forget to join our SubReddit over 65,000 ml.
UPCOMING FREE ai WEBINAR (JANUARY 15, 2025): <a target="_blank" href="https://info.gretel.ai/boost-llm-accuracy-with-sd-and-evaluation-intelligence?utm_source=marktechpost&utm_medium=newsletter&utm_campaign=202501_gretel_galileo_webinar”>Increase LLM Accuracy with Synthetic Data and Assessment Intelligence–<a target="_blank" href="https://info.gretel.ai/boost-llm-accuracy-with-sd-and-evaluation-intelligence?utm_source=marktechpost&utm_medium=newsletter&utm_campaign=202501_gretel_galileo_webinar”>Join this webinar to learn practical information to improve LLM model performance and accuracy while protecting data privacy..
Aswin AK is a Consulting Intern at MarkTechPost. He is pursuing his dual degree from the Indian Institute of technology Kharagpur. He is passionate about data science and machine learning, and brings a strong academic background and practical experience solving real-life interdisciplinary challenges.





{kind=link}