
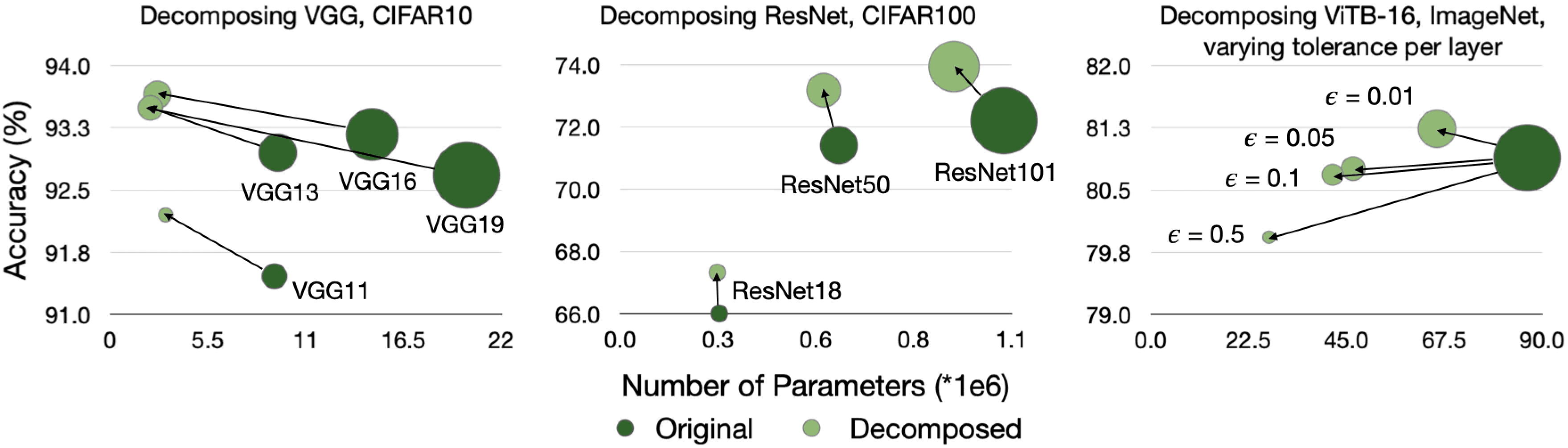
In this work, we study how well the learned weights of a neural network utilize the space available to them. This notion is related to capacity, but additionally incorporates the interaction of the network architecture with the dataset. Most of the learned weights appear to be full-rank and are therefore not amenable to low-rank decomposition. This misleadingly implies that the weights are utilizing all the space available to them. We propose a simple data-driven transformation that projects the weights into the subspace where the data and weight interact. This preserves the functional mapping of the layer and reveals its low-rank structure. In our findings, we conclude that most models utilize a fraction of the available space. For example, for ViTB-16 and ViTL-16 trained on ImageNet, the mean layer utilization is 35% and 20% respectively. Our transformation results in parameter reductions to 50% and 25% respectively, while resulting in an accuracy drop of less than 0.2% after fine-tuning. We also show that self-supervised pre-training increases this utilization up to 70%, justifying its suitability for downstream tasks.






{kind=link}