
Large language models (LLMs) have gained significant attention for their ability to store large amounts of factual knowledge within their weights during pretraining. This capability has led to promising results in knowledge-intensive tasks, particularly in factual question answering. However, a critical challenge remains: LLMs often generate plausible but incorrect answers to queries, undermining their reliability. This inconsistency in factual accuracy poses a significant obstacle in the widespread adoption and trust of LLMs for knowledge-based applications. Researchers are grappling with the challenge of improving the factuality of LLMs' outputs while maintaining their versatility and generative capabilities. The problem is further complicated by the observation that even when LLMs possess the correct information, they can still produce inaccurate answers, suggesting underlying problems in knowledge retrieval and application.
Researchers have attempted various approaches to improve factuality in LLMs. Some studies focus on the impact of unknown examples during fine-tuning, revealing that these can potentially worsen factuality due to overfitting. Other approaches examine the reliability of factual knowledge, showing that LLMs often underperform on obscure information. Techniques to improve factuality include manipulating attention mechanisms, using unsupervised internal probes, and developing methods for LLMs to refrain from answering uncertain questions. Some researchers have introduced fine-tuning techniques to encourage LLMs to reject questions outside their knowledge bounds. In addition, studies have investigated LLM mechanisms and training dynamics, examining how facts are stored and extracted, and analyzing the pre-training dynamics of syntax acquisition and attention patterns. Despite these efforts, challenges to achieving consistent factual accuracy remain.
In this study, researchers from Carnegie Mellon University’s Department of Machine Learning and Stanford University’s Department of Computer Science found that the impact of fine-tuning examples in LLMs critically depends on how well the facts are encoded in the pre-trained model. Fine-tuning well-encoded facts significantly improves facticity, while using less well-encoded facts can hurt performance. This phenomenon occurs because LLMs may use memorized knowledge or rely on general “shortcuts” to answer questions. The composition of the fine-tuning data determines which mechanism is amplified. Well-known facts reinforce the use of memorized knowledge, while less familiar facts encourage the use of shortcuts. This insight provides a new perspective for improving the facticity of LLMs through strategic selection of fine-tuning data.
The method uses a synthetic setup to study the impact of data fine-tuning on LLM factuality. This setup simulates a simplified token space for subjects, relations, and responses, with a different format between pre- and post-training tasks. Pre-training samples are drawn from a Zipf distribution for subjects and a uniform distribution for relations. Key findings reveal that fine-tuning popular facts significantly improves factuality, with amplified effects for less popular entities. The study examines the influence of the Zipf distribution parameter and pre-training steps on this phenomenon. These observations lead to the concept of “fact salience,” which represents how well a model knows a fact, thereby influencing fine-tuning behavior and subsequent performance. This synthetic approach allows for a controlled investigation of pre-training processes that would be impractical with real, large language models.
Experimental results on multiple datasets (PopQA, Entity-Questions, and MMLU) and models (Llama-7B and Mistral) consistently show that fine-tuning on less popular or less reliable examples underperforms using popular knowledge. This performance gap widens for less popular test points, supporting the hypothesis that less popular facts are more sensitive to fine-tuning choices. Remarkably, even randomly selected subsets outperform fine-tuning on less popular knowledge, suggesting that including some popular facts can mitigate the negative impact of less popular ones. Furthermore, training on a smaller subset of the most popular facts often performs comparable or better than using the entire dataset. These findings indicate that careful selection of fine-tuning data, focusing on well-known facts, can lead to higher factual accuracy in LLMs, potentially enabling more efficient and effective training processes.
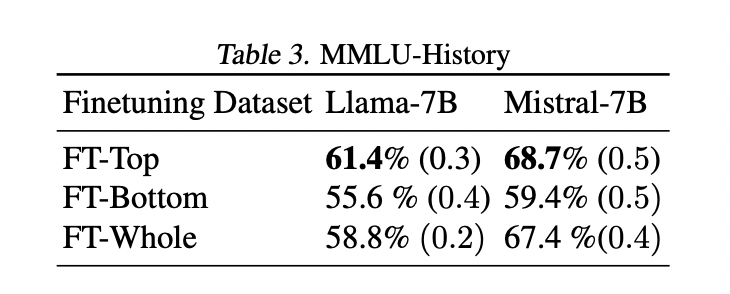
The study provides important insights for improving the veracity of language models by strategically composing QA datasets. Contrary to intuitive assumptions, fine-tuning known facts consistently improves overall veracity. This finding, observed across diverse settings and supported by a conceptual model, challenges conventional approaches to QA dataset design. The research opens new avenues for improving the performance of language models, suggesting potential benefits in regularization techniques to overcome attentional imbalance, curriculum learning strategies, and the development of synthetic data for efficient knowledge extraction. These findings provide a foundation for future work aimed at improving the factual accuracy and reliability of language models in diverse applications.
Review the Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter.
Join our Telegram Channel and LinkedIn GrAbove!.
If you like our work, you will love our Newsletter..
Don't forget to join our Subreddit with over 46 billion users
Asjad is a consultant intern at Marktechpost. He is pursuing Bachelors in Mechanical Engineering from Indian Institute of technology, Kharagpur. Asjad is a Machine Learning and Deep Learning enthusiast who is always researching the applications of Machine Learning in the healthcare domain.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>





{kind=link}