 NEWSLETTER
NEWSLETTER
Neural networks, despite their theoretical ability to fit training sets with as many samples as there are parameters, often fall short in practice due to limitations in training procedures. This gap between theoretical potential and practical performance poses significant challenges for applications that require fine-tuning of data, such as medical diagnosis, autonomous driving, and large-scale language models. Understanding and overcoming these limitations is crucial to advancing ai research and improving the efficiency and effectiveness of neural networks in real-world tasks.
Current methods to address the flexibility of neural networks involve overparameterization, convolutional architectures, various optimizers, and activation functions such as ReLU. However, these methods have notable limitations. Overparameterized models, although theoretically capable of universal function approximation, often fail to achieve optimal minima in practice due to limitations in the training algorithms. Convolutional networks, while more parameter-efficient than MLPs and ViTs, do not fully exploit their potential on randomly labeled data. Optimizers like SGD and Adam are traditionally thought to regularize, but in reality they can restrict the network's ability to fit the data. Additionally, activation functions designed to prevent gradients from fading and exploding inadvertently limit data fitting capabilities.
A team of researchers from New York University, the University of Maryland, and Capital One proposes a comprehensive empirical examination of the data-fitting ability of neural networks using the Effective Model Complexity (EMC) metric. This novel approach measures the largest sample size that a model can perfectly fit, considering realistic training loops and various types of data. By systematically evaluating the effects of architectures, optimizers, and activation functions, the proposed methods offer new insight into the flexibility of neural networks. The innovation lies in the empirical approach to measuring capacity and identifying the factors that actually influence the fit of the data, thus providing insights that go beyond the limits of the theoretical approach.
The EMC metric is calculated using an iterative approach, starting with a small training set and gradually increasing it until the model fails to reach 100% training accuracy. This method is applied on multiple data sets, including MNIST, CIFAR-10, CIFAR-100, and ImageNet, as well as tabular data sets such as Forest Cover Type and Adult Income. Key technical aspects include the use of various neural network architectures (MLP, CNN, ViT) and optimizers (SGD, Adam, AdamW, Shampoo). The study ensures that each training run achieves a minimum of the loss function by checking the gradient norms, the stability of the training loss, and the absence of negative eigenvalues in the Hessian loss.
The study reveals important insights: standard optimizers limit data-fitting ability, while CNNs are more parameter-efficient even with random data. ReLU activation functions allow for better data fitting compared to sigmoidal activations. Convolutional networks (CNN) demonstrated superior ability to fine-tune training data via multi-layer perceptrons (MLP) and vision transformers (ViT), particularly on datasets with semantically consistent labels. Furthermore, CNNs trained with stochastic gradient descent (SGD) fit more training samples than those trained with full-batch gradient descent, and this ability predicted better generalization. The effectiveness of CNNs was especially evident in their ability to fit more correctly labeled samples compared to incorrectly labeled ones, which is indicative of their generalization ability.
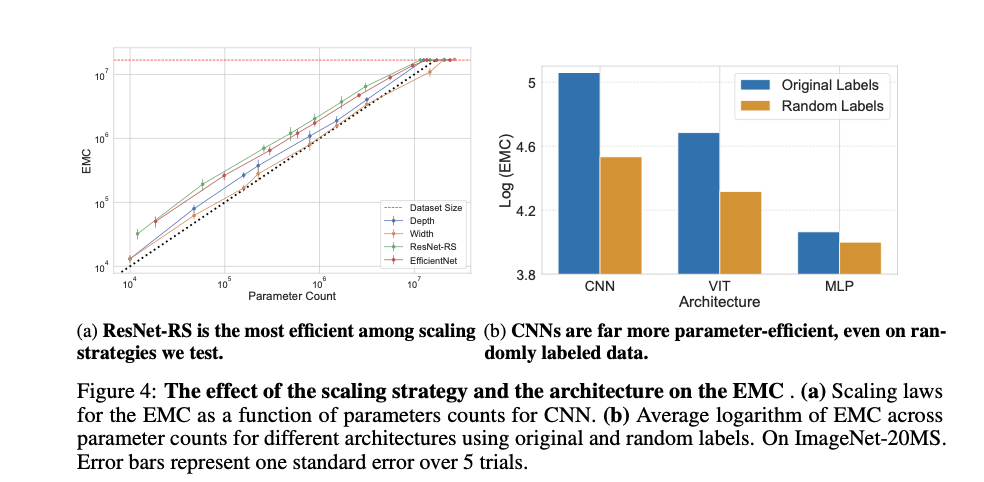
In conclusion, the proposed methods provide a comprehensive empirical assessment of the flexibility of neural networks, challenging conventional wisdom about their data fitting ability. The study introduces the EMC metric to measure practicality and reveals that CNNs are more parameter-efficient than previously thought and that optimizers and activation functions significantly influence data fitting. These insights have substantial implications for improving the architecture design and training of neural networks, advancing the field by addressing a critical challenge in ai research.
Review the Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter.
Join our Telegram channel and LinkedIn Grabove.
If you like our work, you will love our Newsletter..
Don't forget to join our SubReddit over 45,000ml
Aswin AK is a Consulting Intern at MarkTechPost. He is pursuing his dual degree from the Indian Institute of technology Kharagpur. She is passionate about data science and machine learning, and brings a strong academic background and practical experience solving real-life interdisciplinary challenges.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}