
Self-correcting mechanisms have been a major topic of interest within artificial intelligence, particularly in large language models (LLM). Self-correction is traditionally considered a distinctive human trait. Still, researchers have begun to investigate how it can be applied to LLMs to enhance their capabilities without requiring external input. This emerging area explores ways to enable LLMs to evaluate and refine their responses, making them more autonomous and effective in understanding complex tasks and generating contextually appropriate responses.
The researchers aim to address a critical problem: the dependence of LLMs on external critics and predefined supervision to improve the quality of response. Conventional models, although powerful, often rely on human feedback or external testers to correct errors in the generated content. This dependency limits your ability to improve and function independently. A comprehensive understanding of how LLMs can autonomously correct their errors is essential to building more advanced systems that can function without constant external validation. Achieving this understanding can revolutionize the way ai models learn and evolve.
Most existing methods in this field include reinforcement learning from human feedback (RLHF) or direct preference optimization (DPO). These methods often incorporate external critics or human preference data to guide LLMs in refining their responses. For example, in RLHF, a model receives feedback from humans about its generated responses and uses that feedback to adjust its subsequent results. Although these methods have been successful, they do not allow models to improve their behaviors autonomously. This limitation presents a challenge in developing LLMs that can independently identify and correct their errors, requiring novel approaches to improve self-correction skills.
Researchers from MIT CSAIL, Peking University and TU Munich have introduced an innovative theoretical framework based on alignment in context (ICA). The research proposes a structured process where LLMs use internal mechanisms to self-criticize and refine responses. Adopting a generate-criticize-regenerate methodology, the model starts with an initial response, critiques its performance internally using a reward metric, and then generates an improved response. The process is repeated until the result meets a higher alignment standard. This method transforms the traditional context (query, response) into a more complex triplet format (query, response, reward). The study argues that such a formulation helps models evaluate and align themselves more effectively without requiring predefined human-guided objectives.
The researchers used a multi-layer transformer architecture to implement the proposed self-correction mechanism. Each layer consists of multi-head self-attention and feedback network modules that allow the model to discern between good and bad responses. Specifically, the architecture was designed to allow LLMs to perform gradient descent through in-context learning, allowing for a more dynamic and nuanced understanding of alignment tasks. Through experiments with synthetic data, the researchers validated that transformers could indeed learn from noisy outputs when guided by accurate critics. The study's theoretical contributions also shed light on how specific architectural components such as softmax attention and feedback networks are crucial to enabling effective alignment in context, setting a new standard for transformer-based architectures.
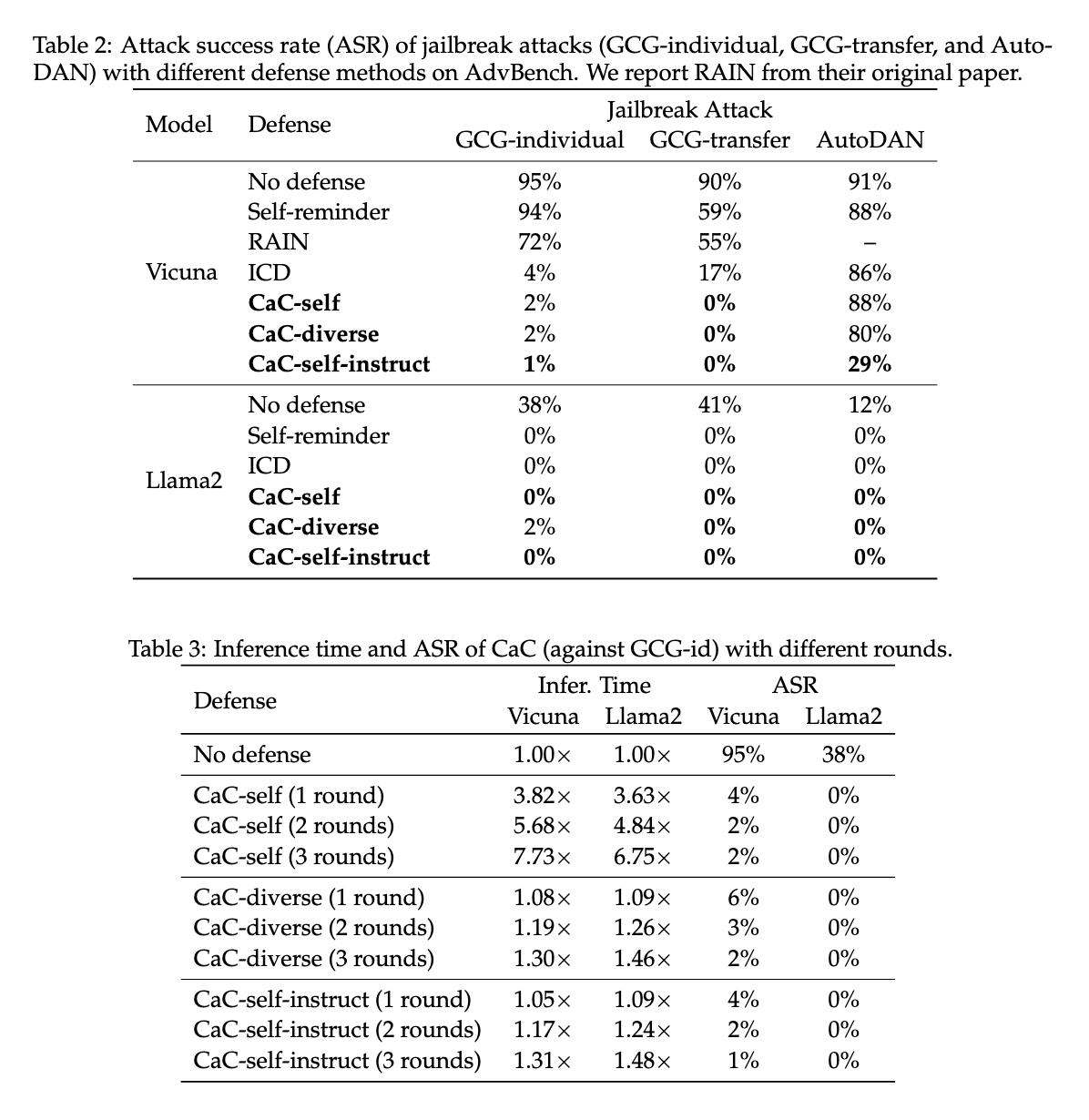
Performance evaluation revealed substantial improvements across multiple test scenarios. The self-correction mechanism significantly reduced error rates and improved alignment in LLMs, even in situations involving noisy feedback. For example, the proposed method showed a drastic reduction in attack success rates during jailbreak testing, with the success rate dropping from 95% to just 1% in certain scenarios using LLM such as Vicuña-7b and Call2-7b-chat. The results indicated that the self-correction mechanisms could defend against sophisticated jailbreak attacks such as GCG-individual, GCG-transfer, and AutoDAN. This strong performance suggests that self-correcting LLMs have the potential to offer greater security and robustness in real-world applications.
The proposed self-correction method also improved significantly in experiments addressing social biases. When applied to the Bias Benchmark for QA (BBQ) data set, which assesses biases across nine social dimensions, the method achieved performance improvements in categories such as gender, race, and socioeconomic status. The study demonstrated a 0% attack success rate across several bias dimensions using Llama2-7b-chat, demonstrating the model's effectiveness in maintaining alignment even in complex social contexts.
In conclusion, this research offers an innovative approach to self-correction in LLMs, emphasizing the potential of models to refine their results autonomously without relying on external feedback. The innovative use of multi-layer transformative architectures and in-context alignment demonstrates a clear path forward to develop more autonomous and intelligent language models. By allowing LLMs to self-assess and improve, the study paves the way for the creation of more robust, secure and context-aware ai systems, capable of tackling complex tasks with minimal human intervention. This advance could significantly improve the future design and application of LLMs in various domains, laying the foundation for models that not only learn but also evolve independently.
look at the Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter and join our Telegram channel and LinkedIn Grabove. If you like our work, you will love our information sheet..
Don't forget to join our SubReddit over 50,000ml.
We are inviting startups, companies and research institutions that are working on small language models to participate in this next Magazine/Report 'Small Language Models' by Marketchpost.com. This magazine/report will be published in late October/early November 2024. Click here to schedule a call!
Nikhil is an internal consultant at Marktechpost. He is pursuing an integrated double degree in Materials at the Indian Institute of technology Kharagpur. Nikhil is an ai/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in materials science, he is exploring new advances and creating opportunities to contribute.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}