 NEWSLETTER
NEWSLETTER
Large text-to-image broadcast models have been an innovative tool for creating and editing content because they allow a variety of images to be synthesized with unmatched quality that correspond to a particular text message. Despite the semantic direction of the text indicator, these models still lack logical controls that can drive the spatial features of the synthesized images. An unresolved problem is how to steer a previously trained text-to-image diffusion model during inference with a spatial map from another domain, such as sketches.
To map the guided image into the latent space of the previously trained unconditional diffusion model, one approach is to train a dedicated encoder. However, the trained coder does well within the domain, but has trouble drawing freehand outside of the domain.
In this paper, three researchers from Google Brain and Tel Aviv University addressed this problem by presenting a general method to drive the inference process of a pretrained text-to-image diffusion model with an edge predictor operating on activations. internal to the diffusion model. central grid, which induces the edge of the synthesized image to adhere to a reference sketch.
Latent edge predictor (LEP)
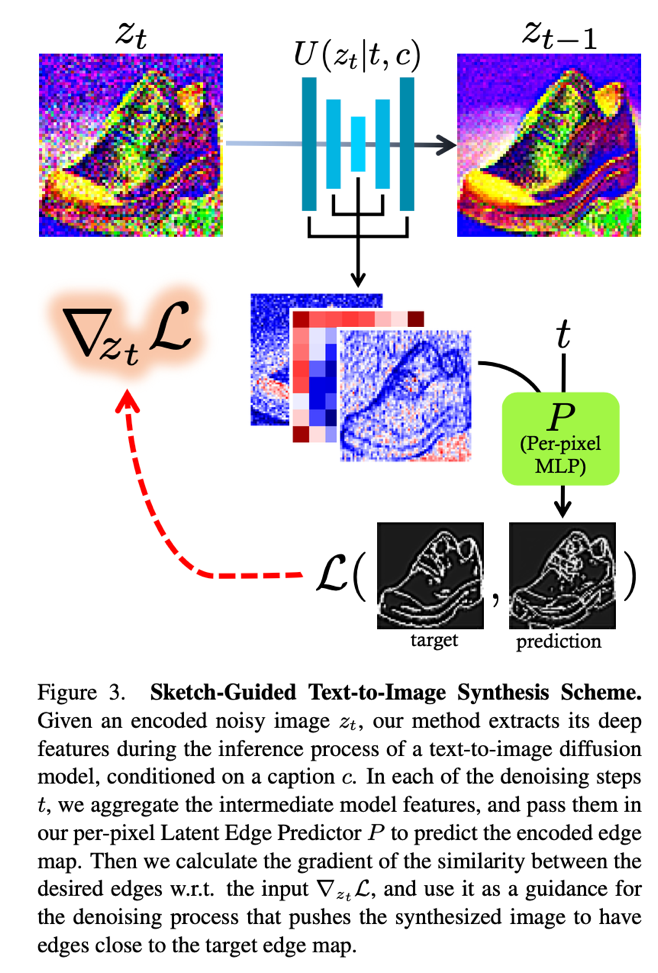
The first goal is to train an MLP that guides the imaging process with a target edge map, as shown in the figure below. The MLP is able to map the internal activations of a denoising diffusion model network onto spatial edge maps. The U-net core network of the broadcast model is then used to extract activations from a predetermined order of intermediate layers.
Triplets (x,e,c) containing an image (x), an edge map (me), and a corresponding text caption (C.) are used to train the network. The edge maps (me) and images (x) are preprocessed by the model encoder me to produce Former) Y and and). Then using text C. and the amount of noise you Given to meactivations are drawn from a predefined sequence of intermediate layers in the U-net core network of the broadcast model.
The extracted features are mapped to the coded edge map and and) training the MLP per pixel with the sum of its channels. The MLP is trained to predict edges locally, being indifferent to the image domain, due to the per-pixel nature of the architecture. Furthermore, it allows training on a small volume of a few thousand images.
Sketch-guided text-to-image synthesis
Once the LEP is trained, they are given a sketch image me and a subtitle C., the goal is to generate a corresponding highly detailed image that follows the outline of the sketch. This process is shown in the following figure.
The authors started from a latent image representation zyou sampled from a uniform Gaussian. Typically, the synthesis of DDPM consists of you consecutive denoising steps, constituting the back diffusion process. The internal activations are once again collected in the U-Net shape network and concatenated into one spatial tensor per pixel. Then, using the pretrained LEP per pixel, a sketch is predicted. The loss is calculated as the similarity between the predicted sketch and the target. me. At the end of the training, the model produces a natural image aligned with the desired sketch.
Results
Some (impressive) results are shown below. At inference time, from a text message and an input sketch, the model can produce realistic samples guided by information from two inputs.

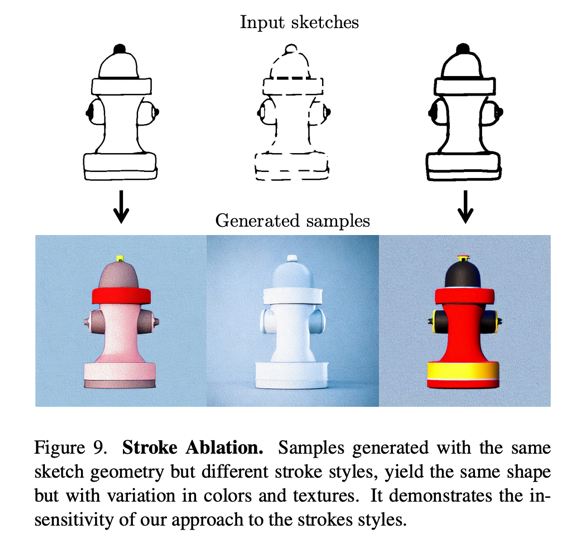
Additionally, as shown below, the authors conducted additional studies on specific use cases, such as realism vs. edge fidelity or stroke importance.

review the Paper Y Project. All credit for this research goes to the researchers of this project. Also, don’t forget to join our reddit page, discord channel, Y electronic newsletterwhere we share the latest AI research news, exciting AI projects, and more.
Leonardo Tanzi is currently a Ph.D. Student at the Polytechnic University of Turin, Italy. His current research focuses on human-machine methodologies for intelligent support during complex interventions in the medical field, using Deep Learning and Augmented Reality for 3D assistance.






{kind=link}