
Large language models (LLMs) have demonstrated impressive capabilities in handling knowledge-intensive tasks through their parametric knowledge stored within the model parameters. However, stored knowledge can become inaccurate or outdated, leading to the adoption of retrieval methods and improved tools that provide external contextual knowledge. A critical challenge arises when this contextual knowledge conflicts with the parametric knowledge of the model, causing undesired behavior and incorrect results. LLMs prefer contextual knowledge over parametric knowledge, but during conflicts, existing solutions that need additional model interactions result in high latency times, making them impractical for real-world applications.
Existing methods for understanding and controlling LLM behavior have followed several key directions, including representation engineering, knowledge conflicts, and sparse autoencoder (SAE). Representation engineering emerged as a high-level framework for understanding the behavior of LLMs at scale. It includes mechanistic interpretability that analyzes individual network components, such as circuits and neurons, but struggles with complex phenomena. Furthermore, there are three types of knowledge conflicts: inter-context conflicts, context-memory conflicts, and intra-memory conflicts. Furthermore, SAEs have been developed as post-hoc analysis tools to identify disentangled features within LLM representations, showing promise in identifying sparse circuits and enabling controlled generation of text via monosemantic features.
Researchers from the University of Edinburgh, the Chinese University of Hong Kong, Sapienza University of Rome, University College London and Miniml.ai have proposed SPARE (Sparse Autoencoder-Based Representation Engineering), a novel representation engineering method without training. The method uses pre-trained sparse autoencoders to control knowledge selection behavior in LLMs. It effectively resolves knowledge conflicts in open-domain question answering tasks by identifying functional features that govern knowledge selection and editing internal activations during inference. SPARE outperforms existing representation engineering methods by 10% and contrastive decoding methods by 15%.
The effectiveness of SPARE is evaluated using multiple models, including Llama3-8B, Gemma2-9B with pre-trained public SAEs, and Llama2-7B with pre-trained custom SAEs. The method is tested on two prominent open-domain question-answering datasets with knowledge conflicts: NQSwap and Macnoise. The evaluation uses greedy decoding for open generation environments. Performance comparisons are made with several inference time representation engineering methods, including TaskVec, ActAdd, SEA (both linear and nonlinear versions), and contrastive decoding methods such as DoLa and CAD. Additionally, the researchers also compared the use of in-context learning (ICL) to direct knowledge selection.
SPARE outperforms existing representation engineering methods TaskVec, ActAdd and SEA, showing superior performance in controlling the use of both contextual and parametric knowledge compared to existing methods. Furthermore, it outperforms contrastive decoding strategies such as DoLa and CAD, which demonstrate effectiveness in improving the use of contextual knowledge, but face challenges with the control of parametric knowledge. SPARE's ability to add and remove specific functional features results in finer control over both types of knowledge. Furthermore, SPARE outperforms inference-free time tracking approaches such as ICL, highlighting its efficiency and effectiveness. These results underscore the potential of SPARE for practical applications that require real-time control over LLM behavior.
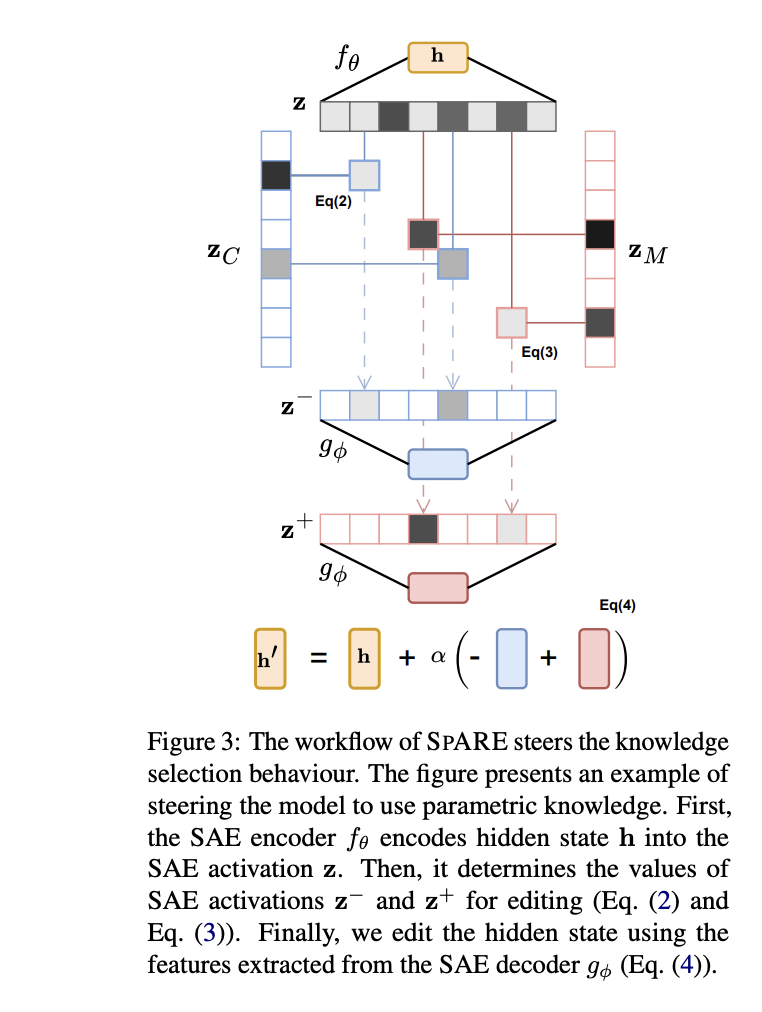
In conclusion, researchers introduced SPARE, which addresses the challenge of context memory knowledge conflicts in LLMs by examining the residual flow of the model and implementing representation engineering without training. The effectiveness of the method in controlling knowledge selection behavior without computational overhead represents a significant advance in LLM knowledge management. However, there are some limitations, including the method's reliance on pretrained SAEs and the current focus on specific ODQA tasks. Despite these limitations, SPARE's ability to improve the accuracy of knowledge selection while maintaining efficiency makes it a promising solution for managing knowledge conflicts in practical LLM applications.
look at the Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter and join our Telegram channel and LinkedIn Grabove. If you like our work, you will love our information sheet.. Don't forget to join our SubReddit over 55,000ml.
(Next live webinar: October 29, 2024) Best platform to deliver optimized models: Predibase inference engine (promoted)

Sajjad Ansari is a final year student of IIT Kharagpur. As a technology enthusiast, he delves into the practical applications of ai with a focus on understanding the impact of ai technologies and their real-world implications. Its goal is to articulate complex ai concepts in a clear and accessible way.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}