 NEWSLETTER
NEWSLETTER
The research evaluates the reliability of large language models (LLMs) such as GPT, LLaMA and BLOOM, widely used in various domains including education, medicine, science and management. As the use of these models becomes more prevalent, it is critical to understand their limitations and potential pitfalls. The research highlights that as these models increase in size and complexity, their reliability does not necessarily improve. Instead, performance may decline on seemingly simple tasks, leading to misleading results that may go unnoticed by human supervisors. This trend indicates the need for a more comprehensive examination of LLM reliability beyond conventional performance metrics.
The central question explored in the research is that, while scaling up LLMs makes them more powerful, it also introduces unexpected patterns of behavior. Specifically, these models can become less stable and produce erroneous results that seem plausible at first glance. This problem arises due to the dependence on instructional adjustment, human feedback, and reinforcement learning to improve their performance. Despite these advances, LLMs struggle to maintain consistent reliability across tasks of varying difficulty, raising concerns about their robustness and suitability for applications where accuracy and predictability are critical.
Existing methodologies to address these reliability issues include model scaling, which involves increasing parameters, training data, and computational resources. For example, the size of GPT-3 models ranges from 350 million to 175 billion parameters, while LLaMA models range from 6.7 billion to 70 billion. Although scaling has led to improvements in handling complex queries, it has also caused failures in simpler instances that users would expect to be easily managed. Similarly, setting up models using techniques such as reinforcement learning from human feedback (RLHF) has shown mixed results, often leading to models that generate plausible but incorrect answers rather than simply avoiding the question. .
Researchers from the Polytechnic University of Valencia and the University of Cambridge introduced the ReliabilityBank framework to systematically evaluate the reliability of LLMs in five domains: arithmetic ('sum'), vocabulary reorganization ('anagram'), geographical knowledge ('locality'), basic and advanced scientific questions ('science'), and focus on the information. transformations ('transformations'). For example, models were tested with arithmetic operations ranging from simple one-digit addition to complex 100-digit addition in the “addition” domain. LLMs often performed poorly on tasks involving haul operations, with the overall success rate dropping sharply for longer additions. Similarly, on the 'anagram' task, which involves rearranging letters to form words, performance varied significantly depending on word length, with a failure rate of 96.78% for the longest anagram tested. This domain-specific benchmarking reveals the nuanced strengths and weaknesses of LLMs, offering a deeper understanding of their capabilities.
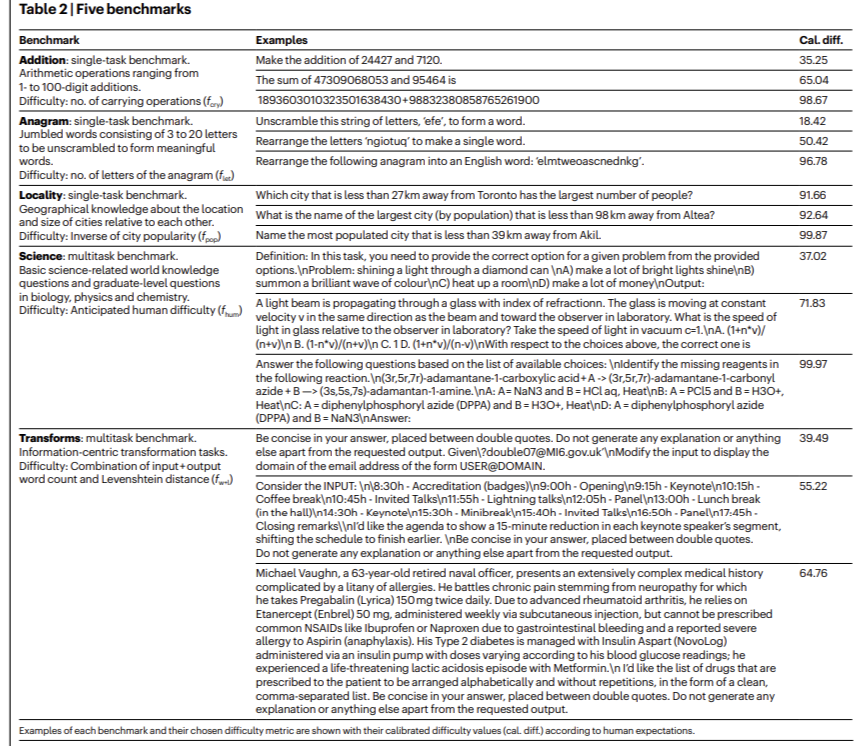
Research results show that while scaling and configuration strategies improve LLM performance on complex questions, they often degrade reliability on simpler ones. For example, models like GPT-4 and LLaMA-2, which excel at answering complex scientific queries, still make basic errors in simple arithmetic or word rearrangement tasks. Furthermore, LLaMA-2 performance on geographic knowledge questions, measured using a locality benchmark, indicated high sensitivity to small variations in message wording. While the models showed remarkable accuracy for well-known cities, they struggled significantly when dealing with less popular locations, resulting in a 91.7% error rate for cities not in the top 10% by population.
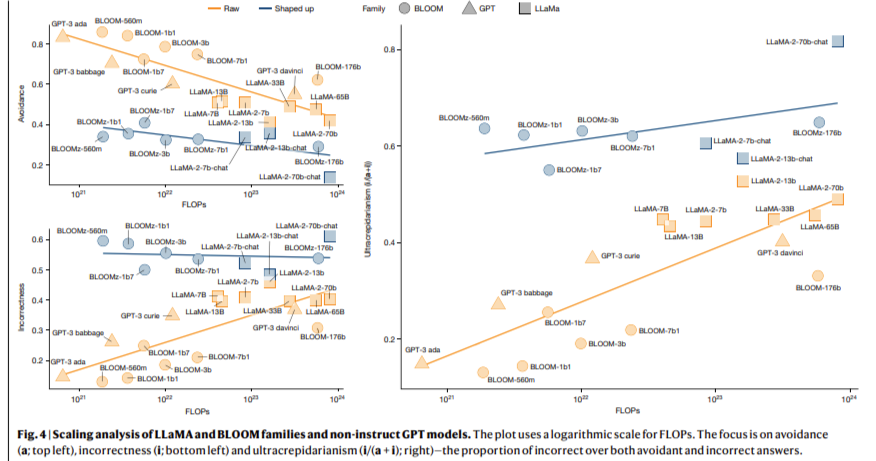
The results indicate that molded models are more likely to produce incorrect but seemingly sensible responses than their older counterparts, who often avoid responding when unsure. The researchers observed that avoidance behavior, measured as the proportion of unanswered questions, was 15% higher in older models like the GPT-3 compared to the newer GPT-4, where this behavior was reduced to almost zero. This reduction in avoidance, while potentially beneficial to the user experience, led to an increase in the frequency of incorrect responses, particularly on easy tasks. Consequently, the apparent reliability of these models decreased, undermining users' confidence in their results.

In conclusion, the research highlights the need for a paradigm shift in the design and development of LLM. The proposed ReliabilityBench framework provides a robust evaluation methodology that moves from aggregated performance scores to a more nuanced evaluation of model behavior based on human difficulty levels. This approach allows the reliability of the model to be characterized, paving the way for future research to focus on ensuring consistent performance across all levels of difficulty. The findings highlight that, despite advances, LLMs have not yet reached a level of reliability that aligns with human expectations, making them prone to unexpected failures that must be addressed through refined training and evaluation strategies.
look at the Paper and HF Page. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter and join our Telegram channel and LinkedIn Grabove. If you like our work, you will love our information sheet..
Don't forget to join our SubReddit over 50,000ml
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of artificial intelligence for social good. Their most recent endeavor is the launch of an ai media platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is technically sound and easily understandable to a wide audience. The platform has more than 2 million monthly visits, which illustrates its popularity among the public.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}