 NEWSLETTER
NEWSLETTER
amazon Q Developer es un asistente impulsado por IA para el desarrollo de software que reinventa la experiencia durante todo el ciclo de vida del desarrollo de software, agilizando la creación, seguridad, administración y optimización de aplicaciones dentro o fuera de AWS. amazon Q Developer Agent incluye un agente para el desarrollo de funciones que implementa automáticamente funciones de varios archivos, correcciones de errores y pruebas unitarias en su espacio de trabajo del entorno de desarrollo integrado (IDE) mediante entrada de lenguaje natural. Después de ingresar su consulta, el agente de desarrollo de software analiza su código base y formula un plan para cumplir con la solicitud. Puede aceptar el plan o pedirle al agente que lo repita. Una vez validado el plan, el agente genera los cambios de código necesarios para implementar la función que usted solicitó. Luego puede revisar y aceptar los cambios del código o solicitar una revisión.
amazon Q Developer utiliza inteligencia artificial (IA) generativa para ofrecer precisión de vanguardia a todos los desarrolladores, ocupando el primer lugar en la clasificación de banco SWE, un conjunto de datos que prueba la capacidad de un sistema para resolver automáticamente problemas de GitHub. Esta publicación describe cómo comenzar con el agente de desarrollo de software, brinda una descripción general de cómo funciona el agente y analiza su desempeño en puntos de referencia públicos. También profundizamos en el proceso de introducción a amazon Q Developer Agent y brindamos una descripción general de los mecanismos subyacentes que lo convierten en un agente de desarrollo de funciones de última generación.
Empezando
Para comenzar, debe tener un ID de AWS Builder o ser parte de una organización con una instancia de AWS IAM Identity Center configurada que le permita usar amazon Q. Para usar amazon Q Developer Agent para el desarrollo de funciones en Visual Studio Code, comience instalando el amazon-q-vscode” target=”_blank” rel=”noopener”>Extensión de amazon Q. La extensión también está disponible para JetBrains, Visual Studio (en versión preliminar) y en la línea de comandos en macOS. Encuentre la última versión en la página para desarrolladores de amazon Q.
<img class="alignnone wp-image-77119 size-full" style="margin: 10px 0px 10px 0px;border: 1px solid #CCCCCC" src="https://technicalterrence.com/wp-content/uploads/2024/06/Reimaginando-el-desarrollo-de-software-con-Amazon-Q-Developer-Agent.jpg" alt="Tarjeta de la aplicación amazon Q en VS Code” width=”844″ height=”78″/>
Después de autenticarse, puede invocar al agente de desarrollo de funciones ingresando /dev en el campo de chat.
<img loading="lazy" class="alignnone wp-image-77120 size-full" style="margin: 10px 0px 10px 0px;border: 1px solid #CCCCCC" src="https://technicalterrence.com/wp-content/uploads/2024/06/1718129333_708_Reimaginando-el-desarrollo-de-software-con-Amazon-Q-Developer-Agent.jpg" alt="Invocando /dev en amazon Q” width=”844″ height=”254″/>
El agente de desarrollo de funciones ya está listo para sus solicitudes. Usemos el repositorio de amazon-science/chronos-forecasting” target=”_blank” rel=”noopener”>El modelo de previsión Chronos de amazon para demostrar cómo funciona el agente. El código de Chronos ya es de alta calidad, pero la cobertura de las pruebas unitarias podría mejorarse en algunos lugares. Pidamos al agente de desarrollo de software que mejore la cobertura de prueba unitaria del archivo cronos.py. Exponer su solicitud de la forma más clara y precisa posible ayudará al agente a ofrecer la mejor solución posible.
El agente devuelve un plan detallado para agregar las pruebas faltantes en el conjunto de pruebas existente. test/test_chronos.py. Para generar el plan (y luego el cambio de código), el agente ha explorado su código base para comprender cómo satisfacer su solicitud. El agente funcionará mejor si los nombres de los archivos y funciones describen su intención.
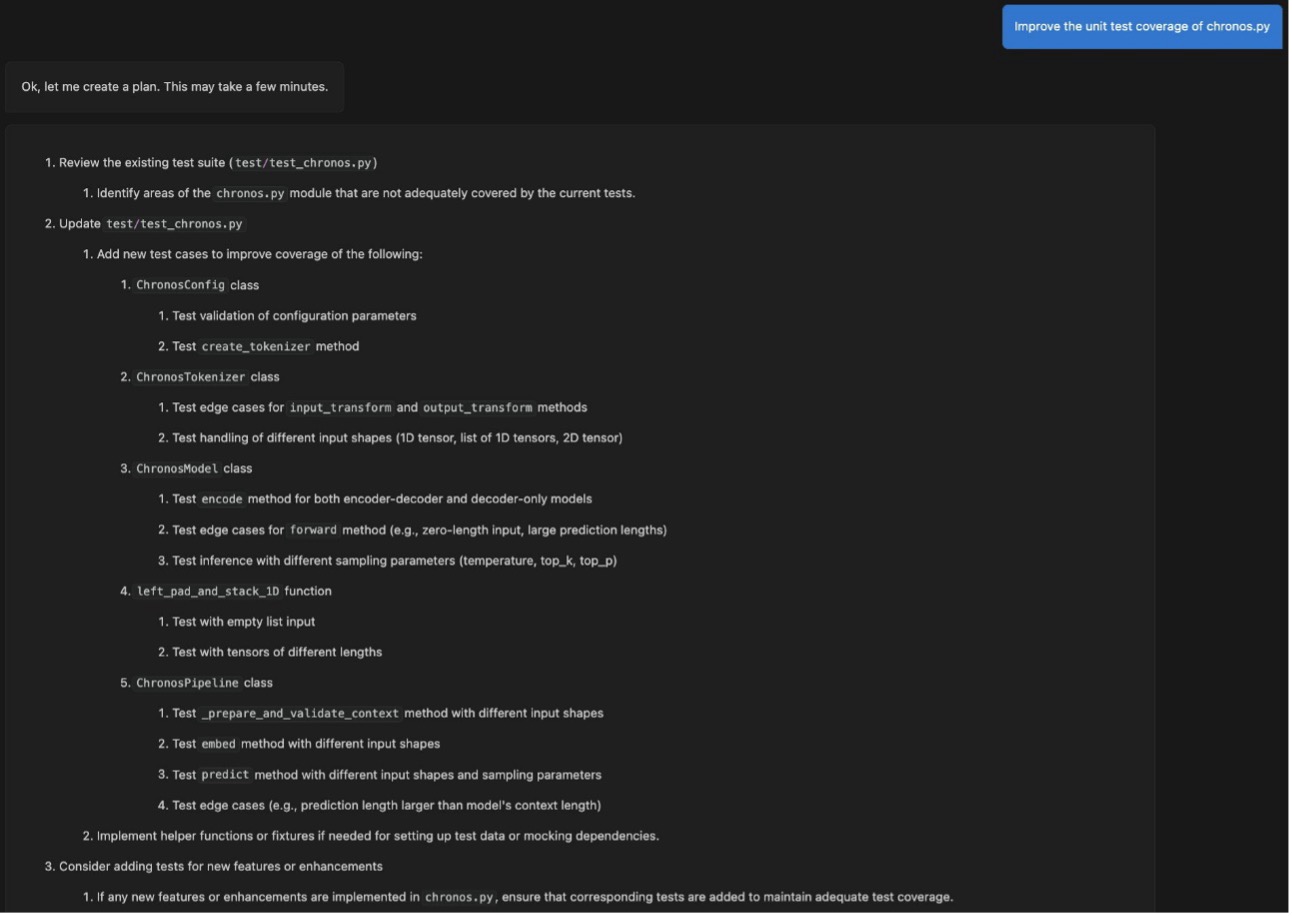
Se le pide que revise el plan. Si el plan se ve bien y desea continuar, elija Generar codigo. Si descubre que se puede mejorar en algunos lugares, puede brindar comentarios y solicitar un plan mejorado.
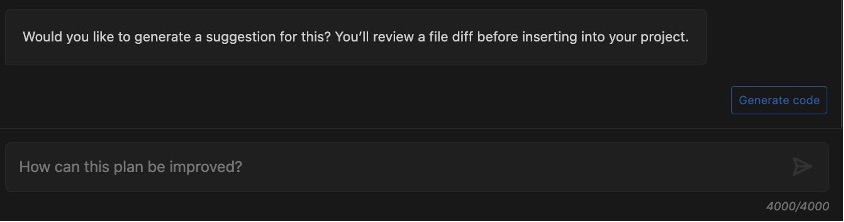
Después de generar el código, el agente de desarrollo de software enumerará los archivos para los cuales ha creado un diff (para esta publicación, test/test_chronos.py). Puede revisar los cambios de código y decidir insertarlos en su base de código o proporcionar comentarios sobre posibles mejoras y regenerar el código.
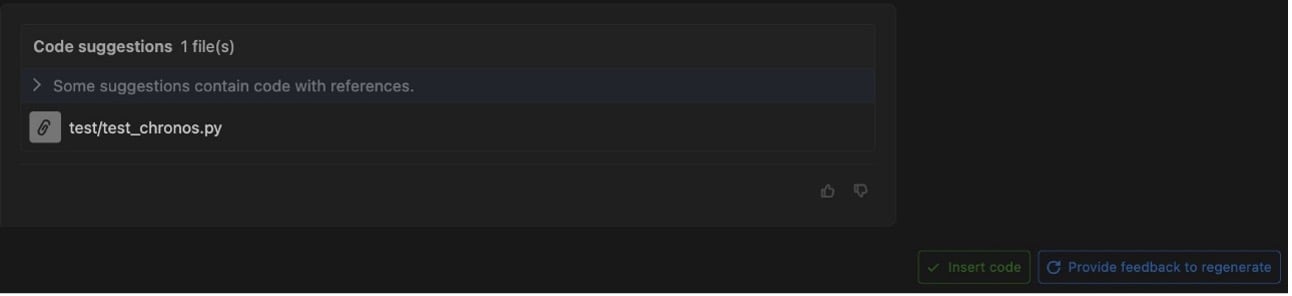
Al elegir un archivo modificado, se abre una vista de diferencias en el IDE que muestra qué líneas se han agregado o modificado. El agente agregó múltiples pruebas unitarias para partes de cronos.py que no estaban cubiertas anteriormente.
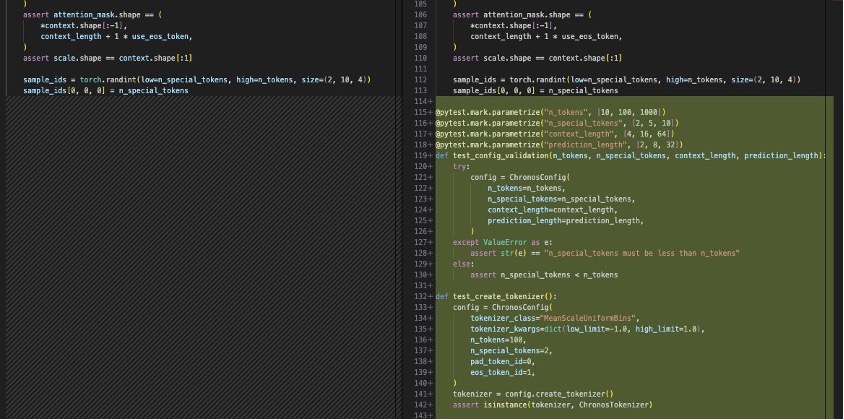
Después de revisar los cambios en el código, puede decidir insertarlos, proporcionar comentarios para generar el código nuevamente o descartarlo por completo. Eso es todo; no hay nada más que puedas hacer. Si desea solicitar otra función, invoque \dev nuevamente en amazon Q Developer.
Resumen del sistema
Ahora que le hemos mostrado cómo utilizar amazon Q Developer Agent para el desarrollo de software, exploremos cómo funciona. Esta es una descripción general del sistema a mayo de 2024. El agente se mejora continuamente. La lógica descrita en esta sección evolucionará y cambiará.
Cuando envía una consulta, el agente genera una representación estructurada del sistema de archivos del repositorio en XML. El siguiente es un resultado de ejemplo, truncado por motivos de brevedad:
Luego, un LLM utiliza esta representación con su consulta para determinar qué archivos son relevantes y deben recuperarse. Utilizamos sistemas automatizados para comprobar que todos los archivos identificados por el LLM sean válidos. El agente utiliza los archivos recuperados con su consulta para generar un plan sobre cómo resolverá la tarea que le ha asignado. Este plan se le devuelve para su validación o iteración. Después de validar el plan, el agente pasa al siguiente paso, que finalmente finaliza con una propuesta de cambio de código para resolver el problema.
El contenido de cada archivo de código recuperado se analiza con un analizador de sintaxis para obtener una representación de árbol de sintaxis XML del código, que el LLM es capaz de usar de manera más eficiente que el código fuente mismo y al mismo tiempo usar muchos menos tokens. El siguiente es un ejemplo de esa representación. Los archivos sin código se codifican y fragmentan utilizando una lógica comúnmente utilizada en los sistemas de recuperación de generación aumentada (RAG) para permitir la recuperación eficiente de fragmentos de documentación.
La siguiente captura de pantalla muestra una parte del código Python.
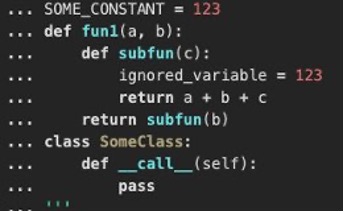
La siguiente es su representación en árbol de sintaxis.
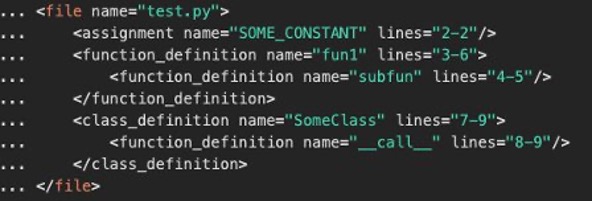
Al LLM se le solicita nuevamente el planteamiento del problema, el plan y la estructura de árbol XML de cada uno de los archivos recuperados para identificar los rangos de líneas que necesitan actualizarse para resolver el problema. Este enfoque le permite ser más frugal con el uso del ancho de banda de LLM.
El agente de desarrollo de software ahora está listo para generar el código que resolverá su problema. El LLM reescribe directamente secciones de código, en lugar de intentar generar un parche. Esta tarea es mucho más cercana a aquellas para las que se optimizó el LLM en comparación con intentar generar directamente un parche. El agente procede a realizar una validación sintáctica del código generado e intenta solucionar los problemas antes de pasar al paso final. El código original y reescrito se pasan a una biblioteca de diferencias para generar un parche mediante programación. Esto crea el resultado final que luego se comparte con usted para que lo revise y acepte.
Precisión del sistema
En el amazon-q-the-most-capable-generative-ai-powered-assistant-for-accelerating-software-development-and-leveraging-companies-internal-data” target=”_blank” rel=”noopener”>presione soltar Al anunciar el lanzamiento de amazon Q Developer Agent para el desarrollo de funciones, compartimos que el modelo obtuvo una puntuación del 13,82 % en SWE-bench y del 20,33 % en SWE-bench lite, lo que lo sitúa en la cima de la lista. Tabla de clasificación del banco SWE a mayo de 2024. SWE-bench es un conjunto de datos públicos de más de 2000 tareas de 12 repositorios populares de código abierto de Python. La métrica clave reportada en la tabla de clasificación de SWE-bench es la tasa de aprobación: con qué frecuencia vemos que todas las pruebas unitarias asociadas a un problema específico pasan después de que se aplican cambios en el código generado por IA. Esta es una métrica importante porque nuestros clientes quieren utilizar el agente para resolver problemas del mundo real y estamos orgullosos de informar una tasa de aprobación de última generación.
Una sola métrica nunca cuenta toda la historia. Consideramos el desempeño de nuestro agente como un punto en el frente de Pareto sobre múltiples métricas. El amazon Q Developer Agent para el desarrollo de software no está optimizado específicamente para SWE-bench. Nuestro enfoque se centra en la optimización para una variedad de métricas y conjuntos de datos. Por ejemplo, nuestro objetivo es lograr un equilibrio entre precisión y eficiencia de recursos, como la cantidad de llamadas de LLM y tokens de entrada/salida utilizados, porque esto afecta directamente el tiempo de ejecución y el costo. En este sentido, estamos orgullosos de la capacidad de nuestra solución para ofrecer resultados consistentes en cuestión de minutos.
Limitaciones de los puntos de referencia públicos
Los puntos de referencia públicos como SWE-bench son una contribución increíblemente útil a la comunidad de generación de códigos de IA y presentan un desafío científico interesante. Agradecemos al equipo que haya publicado y mantenido este punto de referencia. Estamos orgullosos de poder compartir nuestros resultados de última generación en este punto de referencia. No obstante, nos gustaría señalar algunas limitaciones, que no son exclusivas de SWE-bench.
La métrica de éxito de SWE-bench es binaria. Un cambio de código pasa todas las pruebas o no. Creemos que esto no capta todo el valor que los agentes de desarrollo de funciones pueden generar para los desarrolladores. Los agentes ahorran mucho tiempo a los desarrolladores incluso cuando no implementan la totalidad de una función a la vez. La latencia, el costo, la cantidad de llamadas de LLM y la cantidad de tokens son métricas altamente correlacionadas que representan la complejidad computacional de una solución. Esta dimensión es tan importante como la precisión para nuestros clientes.
Los casos de prueba incluidos en el benchmark SWE-bench están disponibles públicamente en GitHub. Como tal, es posible que estos casos de prueba se hayan utilizado en los datos de entrenamiento de varios modelos de lenguaje grandes. Aunque los LLM tienen la capacidad de memorizar partes de sus datos de entrenamiento, es un desafío cuantificar hasta qué punto se produce esta memorización y si los modelos están filtrando esta información sin darse cuenta durante las pruebas.
Para investigar esta posible preocupación, hemos realizado múltiples experimentos para evaluar la posibilidad de fuga de datos en diferentes modelos populares. Un enfoque para probar la memorización implica pedir a los modelos que predigan la siguiente línea de una descripción de un problema en un contexto muy breve. Esta es una tarea con la que, en teoría, deberían luchar si no tienen memorización. Nuestros hallazgos indican que los modelos recientes muestran signos de haber sido entrenados en el conjunto de datos del banco SWE.
La siguiente figura muestra la distribución de las puntuaciones de rougeL cuando se pide a cada modelo que complete la siguiente oración de una descripción de un problema del banco SWE dadas las oraciones anteriores.
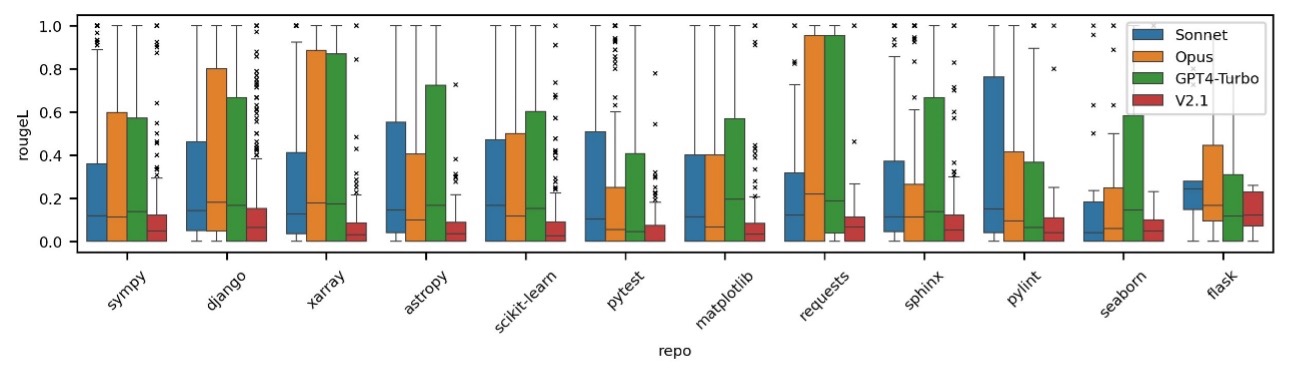
Hemos compartido mediciones del desempeño de nuestro agente de desarrollo de software en SWE-bench para ofrecer un punto de referencia. Recomendamos probar los agentes en repositorios de código privados que no se hayan utilizado en la capacitación de ningún LLM y comparar estos resultados con los de las líneas de base disponibles públicamente. Continuaremos comparando nuestro sistema en SWE-bench mientras centramos nuestras pruebas en conjuntos de datos de evaluación comparativa privados que no se han utilizado para entrenar modelos y que representan mejor las tareas enviadas por nuestros clientes.
Conclusión
En esta publicación se analiza cómo comenzar con amazon Q Developer Agent para el desarrollo de software. El agente implementa automáticamente funciones que usted describe con lenguaje natural en su IDE. Le brindamos una descripción general de cómo trabaja el agente detrás de escena y analizamos su precisión de vanguardia y su posición en la cima de la clasificación de SWE-bench.
¡Ahora está listo para explorar las capacidades de amazon Q Developer Agent para el desarrollo de software y convertirlo en su asistente personal de codificación de IA! Instale el complemento de amazon Q en el IDE de su elección y comience a usar amazon Q (incluido el agente de desarrollo de software) de forma gratuita con su ID de AWS Builder o suscríbase a amazon Q para desbloquear límites más altos.
Sobre los autores
 Christian Bock es un científico aplicado en amazon Web Services que trabaja en IA para código.
Christian Bock es un científico aplicado en amazon Web Services que trabaja en IA para código.
 Laurent Callot es científico aplicado principal en amazon Web Services y lidera equipos que crean soluciones de inteligencia artificial para desarrolladores.
Laurent Callot es científico aplicado principal en amazon Web Services y lidera equipos que crean soluciones de inteligencia artificial para desarrolladores.
 Tim Esler es un científico aplicado senior en amazon Web Services que trabaja en IA generativa y agentes de codificación para crear herramientas de desarrollo y herramientas fundamentales para los productos amazon Q.
Tim Esler es un científico aplicado senior en amazon Web Services que trabaja en IA generativa y agentes de codificación para crear herramientas de desarrollo y herramientas fundamentales para los productos amazon Q.
 Prabhu Teja es científico aplicado en amazon Web Services. Prabhu trabaja en la generación de código asistida por LLM con un enfoque en la interacción del lenguaje natural.
Prabhu Teja es científico aplicado en amazon Web Services. Prabhu trabaja en la generación de código asistida por LLM con un enfoque en la interacción del lenguaje natural.
 Martín Wistuba es un científico aplicado senior en amazon Web Services. Como parte de amazon Q Developer, ayuda a los desarrolladores a escribir más código en menos tiempo.
Martín Wistuba es un científico aplicado senior en amazon Web Services. Como parte de amazon Q Developer, ayuda a los desarrolladores a escribir más código en menos tiempo.
 Giovanni Zappella es un científico aplicado principal que trabaja en la creación de agentes inteligentes para la generación de código. Mientras estuvo en amazon, también contribuyó a la creación de nuevos algoritmos para aprendizaje continuo, AutoML y sistemas de recomendaciones.
Giovanni Zappella es un científico aplicado principal que trabaja en la creación de agentes inteligentes para la generación de código. Mientras estuvo en amazon, también contribuyó a la creación de nuevos algoritmos para aprendizaje continuo, AutoML y sistemas de recomendaciones.






{kind=link}