 NEWSLETTER
NEWSLETTER
Los ingenieros de aprendizaje automático (ML) se han centrado tradicionalmente en lograr un equilibrio entre el entrenamiento del modelo y el costo de implementación frente al rendimiento. Cada vez más, la sostenibilidad (eficiencia energética) se está convirtiendo en un objetivo adicional para los clientes. Esto es importante porque entrenar modelos ML y luego usar los modelos entrenados para hacer predicciones (inferencia) pueden ser tareas que consumen mucha energía. Además, cada vez más aplicaciones a nuestro alrededor se han infundido con ML, y todos los días se conciben nuevas aplicaciones basadas en ML. Un ejemplo popular es ChatGPT de OpenAI, que funciona con un modelo de lenguaje grande (LMM) de última generación. Para referencia, GPT-3, un LLM de generación anterior tiene 175 mil millones de parámetros y requiere meses de entrenamiento continuo en un grupo de miles de procesadores acelerados. El Estudio de rastreador de carbono estima que entrenar GPT-3 desde cero puede emitir hasta 85 toneladas métricas de CO2 equivalente, utilizando grupos de aceleradores de hardware especializados.
Hay varias formas en que AWS permite a los profesionales de ML reducir el impacto ambiental de sus cargas de trabajo. Una forma es proporcionar orientación prescriptiva sobre la arquitectura de sus cargas de trabajo de IA/ML para la sostenibilidad. Otra forma es ofrecer servicios administrados de capacitación y orquestación de ML como Amazon SageMaker Studio, que desmonta y amplía automáticamente los recursos de ML cuando no están en uso, y proporciona una gran cantidad de herramientas listas para usar que ahorran costos y recursos. Otro habilitador importante es el desarrollo de aceleradores de alto rendimiento, eficientes energéticamente y especialmente diseñados para entrenar e implementar modelos de aprendizaje automático.
El enfoque de esta publicación es sobre el hardware como palanca para el aprendizaje automático sostenible. Presentamos los resultados de experimentos recientes de rendimiento y consumo de energía realizados por AWS que cuantifican los beneficios de eficiencia energética que puede esperar al migrar sus cargas de trabajo de aprendizaje profundo desde otras instancias aceleradas de Amazon Elastic Compute Cloud (Amazon EC2) optimizadas para inferencia y capacitación a AWS Inferentia y AWS Trainium. Inferentia y Trainium son la incorporación reciente de AWS a su cartera de aceleradores especialmente diseñados por Amazon Laboratorios Annapurna para cargas de trabajo de entrenamiento e inferencia de ML.
AWS Inferentia y AWS Trainium para un aprendizaje automático sostenible
Para brindarle cifras realistas del potencial de ahorro de energía de AWS Inferentia y AWS Trainium en una aplicación del mundo real, hemos realizado varios experimentos comparativos de consumo de energía. Hemos diseñado estos puntos de referencia teniendo en cuenta los siguientes criterios clave:
- En primer lugar, queríamos asegurarnos de capturar el consumo de energía directo atribuible a la carga de trabajo de prueba, incluido no solo el acelerador de ML, sino también la computación, la memoria y la red. Por lo tanto, en nuestra configuración de prueba, medimos el consumo de energía a ese nivel.
- En segundo lugar, al ejecutar las cargas de trabajo de entrenamiento e inferencia, nos aseguramos de que todas las instancias estuvieran operando en sus respectivos límites físicos de hardware y tomamos medidas solo después de alcanzar ese límite para garantizar la comparabilidad.
- Finalmente, queríamos estar seguros de que los ahorros de energía informados en esta publicación podrían lograrse en una aplicación práctica del mundo real. Por lo tanto, utilizamos casos de uso comunes de ML inspirados en el cliente para la evaluación comparativa y las pruebas.
Los resultados se informan en las siguientes secciones.
Experimento de inferencia: Comprensión de documentos en tiempo real con LayoutLM
La inferencia, a diferencia del entrenamiento, es una carga de trabajo continua e ilimitada que no tiene un punto de finalización definido. Por lo tanto, constituye una gran parte del consumo de recursos de por vida de una carga de trabajo de ML. Obtener la inferencia correcta es clave para lograr un alto rendimiento, bajo costo y sostenibilidad (mejor eficiencia energética) a lo largo de todo el ciclo de vida de ML. Con las tareas de inferencia, los clientes suelen estar interesados en lograr una determinada tasa de inferencia para mantenerse al día con la demanda de ingesta.
El experimento presentado en esta publicación está inspirado en un caso de uso de comprensión de documentos en tiempo real, que es una aplicación común en industrias como la banca o los seguros (por ejemplo, para reclamos o procesamiento de formularios de solicitud). En concreto, seleccionamos DiseñoLM, un modelo de transformador preentrenado que se utiliza para el procesamiento de imágenes de documentos y la extracción de información. Establecemos un SLA objetivo de 1 000 000 de inferencias por hora, un valor que a menudo se considera en tiempo real, y luego especificamos dos configuraciones de hardware capaces de cumplir con este requisito: una que usa instancias Amazon EC2 Inf1, con AWS Inferentia, y otra que usa instancias EC2 aceleradas comparables optimizadas para tareas de inferencia. A lo largo del experimento, rastreamos varios indicadores para medir el rendimiento de inferencia, el costo y la eficiencia energética de ambas configuraciones de hardware. Los resultados se presentan en la siguiente figura.
Resultados de desempeño, costo y eficiencia energética de los puntos de referencia de inferencia
AWS Inferentia ofrece un rendimiento de inferencia 6,3 veces superior. Como resultado, con Inferentia, puede ejecutar la misma carga de trabajo de comprensión de documentos basada en LayoutLM en tiempo real en menos instancias (6 instancias de AWS Inferentia frente a otras 33 instancias EC2 aceleradas optimizadas para inferencia, equivalente a una reducción del 82 %), use menos menos de una décima parte (-92 %) de la energía en el proceso, todo mientras se logra un costo por inferencia significativamente menor (USD 2 vs. USD 25 por millón de inferencias, equivalente a una reducción de costos del 91 %).
Experimento de entrenamiento: Entrenamiento BERT Large desde cero
El entrenamiento, a diferencia de la inferencia, es un proceso finito que se repite con mucha menos frecuencia. Los ingenieros de ML suelen estar interesados en un alto rendimiento del clúster para reducir el tiempo de capacitación y mantener los costos bajo control. La eficiencia energética es una preocupación secundaria (pero creciente). Con AWS Trainium, no hay una decisión de compensación: los ingenieros de ML pueden beneficiarse de un alto rendimiento de capacitación al mismo tiempo que optimizan los costos y reducen el impacto ambiental.
Para ilustrar esto, seleccionamos BERT grande, un modelo de lenguaje popular que se utiliza para casos de uso de comprensión del lenguaje natural, como la respuesta a preguntas basadas en chatbots y la predicción de respuestas conversacionales. El entrenamiento de un modelo BERT grande de buen rendimiento desde cero normalmente requiere el procesamiento de 450 millones de secuencias. Comparamos dos configuraciones de clúster, cada una con un tamaño fijo de 16 instancias y capaces de entrenar BERT Large desde cero (450 millones de secuencias procesadas) en menos de un día. El primero utiliza instancias EC2 aceleradas tradicionales. La segunda configuración utiliza instancias de Amazon EC2 Trn1 con AWS Trainium. Nuevamente, comparamos ambas configuraciones en términos de rendimiento de capacitación, costo e impacto ambiental (eficiencia energética). Los resultados se muestran en la siguiente figura.
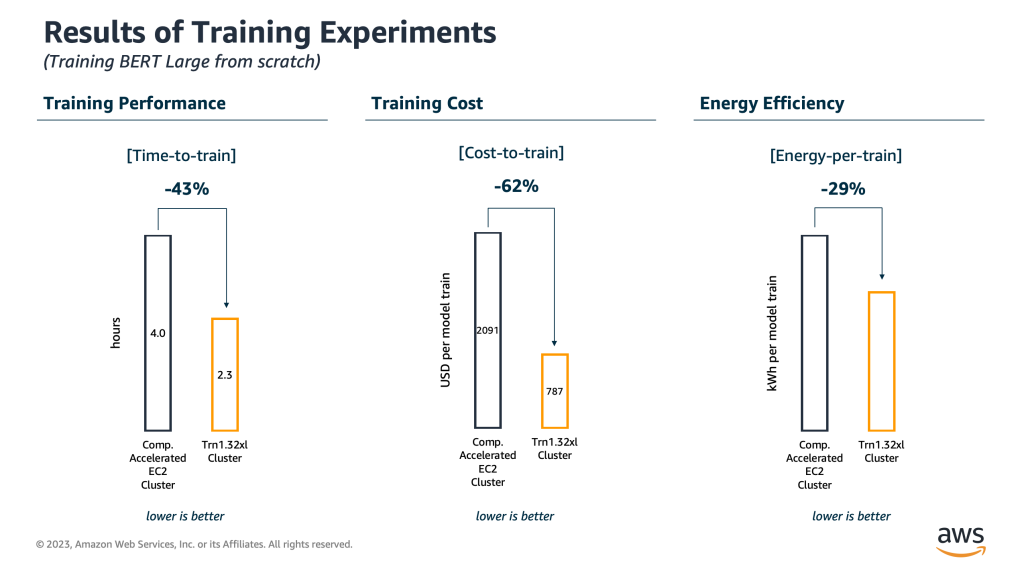
Resultados de Rendimiento, Costo y Eficiencia Energética de los Puntos de Referencia de Capacitación
En los experimentos, las instancias basadas en AWS Trainium superaron a las instancias EC2 aceleradas optimizadas para entrenamiento comparables por un factor de 1,7 en términos de secuencias procesadas por hora, lo que redujo el tiempo total de entrenamiento en un 43 % (2,3 h frente a 4 h en instancias EC2 aceleradas comparables) . Como resultado, cuando se usa un clúster de instancias basado en Trainium, el consumo total de energía para entrenar BERT Large desde cero es aproximadamente un 29 % más bajo en comparación con un clúster del mismo tamaño de instancias EC2 aceleradas comparables. Nuevamente, estos beneficios de rendimiento y eficiencia energética también vienen con importantes mejoras de costos: el costo de capacitación para la carga de trabajo de BERT ML es aproximadamente un 62 % más bajo en las instancias de Trainium (USD 787 frente a USD 2091 por ejecución de capacitación completa).
Primeros pasos con los aceleradores especialmente diseñados de AWS para ML
Aunque todos los experimentos realizados aquí usan modelos estándar del dominio de procesamiento de lenguaje natural (NLP), AWS Inferentia y AWS Trainium sobresalen con muchas otras arquitecturas de modelos complejos, incluidos LLM y las arquitecturas de IA generativa más desafiantes que los usuarios están construyendo (como GPT-3 ). Estos aceleradores funcionan particularmente bien con modelos con más de 10 mil millones de parámetros, o modelos de visión artificial como difusión estable (ver Directrices de ajuste de la arquitectura del modelo para más detalles). De hecho, muchos de nuestros clientes ya utilizan Inferentia y Trainium para una amplia variedad de casos de uso de ML.
Para ejecutar sus cargas de trabajo de aprendizaje profundo de extremo a extremo en instancias basadas en AWS Inferentia y AWS Trainium, puede utilizar AWS Neuron. Neuron es un kit de desarrollo de software (SDK) integral que incluye un compilador de aprendizaje profundo, tiempo de ejecución y herramientas que se integran de forma nativa en los marcos de ML más populares, como TensorFlow y PyTorch. Puede usar Neuron SDK para migrar fácilmente sus cargas de trabajo de ML de aprendizaje profundo TensorFlow o PyTorch existentes a Inferentia y Trainium y comenzar a crear nuevos modelos utilizando los mismos marcos de ML conocidos. Para una configuración más sencilla, use una de nuestras imágenes de máquina de Amazon (AMI) para el aprendizaje profundo, que viene con muchos de los paquetes y dependencias necesarios. Aún más simple: puede usar Amazon SageMaker Studio, que admite de forma nativa TensorFlow y PyTorch en Inferentia y Trainium (consulte el aws-samples repositorio de GitHub para un ejemplo).
Una nota final: si bien Inferentia y Trainium están diseñados específicamente para cargas de trabajo de aprendizaje profundo, muchos algoritmos de ML menos complejos pueden funcionar bien en instancias basadas en CPU (por ejemplo, XGBoost y LightGBM e incluso algunas CNN). En estos casos, una migración a AWS Graviton3 puede reducir significativamente el impacto ambiental de sus cargas de trabajo de ML. Las instancias basadas en Graviton de AWS utilizan hasta un 60 % menos de energía para obtener el mismo rendimiento que las instancias EC2 aceleradas comparables.
Conclusión
Existe una idea errónea común de que ejecutar cargas de trabajo de ML de manera sostenible y eficiente desde el punto de vista energético significa sacrificar el rendimiento o el costo. Con los aceleradores de AWS especialmente diseñados para el aprendizaje automático, los ingenieros de ML no tienen que hacer ese compromiso. En su lugar, pueden ejecutar sus cargas de trabajo de aprendizaje profundo en hardware de aprendizaje profundo diseñado especialmente y altamente especializado, como AWS Inferentia y AWS Trainium, que supera significativamente los tipos de instancias EC2 aceleradas comparables, ofreciendo un menor costo, un mayor rendimiento y una mejor eficiencia energética, hasta 90%, todo al mismo tiempo. Para comenzar a ejecutar sus cargas de trabajo de ML en Inferentia y Trainium, consulte el Documentación de AWS Neuron o gira uno de los cuadernos de muestra. También puede ver la charla de AWS re:Invent 2022 en Sostenibilidad y silicio AWS (SUS206)que cubre muchos de los temas discutidos en esta publicación.
Sobre los autores
 Karsten Schroer es arquitecto de soluciones en AWS. Ayuda a los clientes a aprovechar los datos y la tecnología para impulsar la sostenibilidad de su infraestructura de TI y crear soluciones basadas en datos que permitan operaciones sostenibles en sus respectivas verticales. Karsten se unió a AWS luego de sus estudios de doctorado en administración de operaciones y aprendizaje automático aplicado. Es un verdadero apasionado de las soluciones tecnológicas para los desafíos sociales y le encanta profundizar en los métodos y las arquitecturas de aplicaciones que subyacen a estas soluciones.
Karsten Schroer es arquitecto de soluciones en AWS. Ayuda a los clientes a aprovechar los datos y la tecnología para impulsar la sostenibilidad de su infraestructura de TI y crear soluciones basadas en datos que permitan operaciones sostenibles en sus respectivas verticales. Karsten se unió a AWS luego de sus estudios de doctorado en administración de operaciones y aprendizaje automático aplicado. Es un verdadero apasionado de las soluciones tecnológicas para los desafíos sociales y le encanta profundizar en los métodos y las arquitecturas de aplicaciones que subyacen a estas soluciones.
 kamran khan es gerente sénior de productos técnicos en AWS Annapurna Labs. Trabaja en estrecha colaboración con los clientes de IA/ML para dar forma a la hoja de ruta de las innovaciones de silicio especialmente diseñadas para AWS que salen de Annapurna Labs de Amazon. Su enfoque específico está en los chips de aprendizaje profundo acelerado, incluidos AWS Trainium y AWS Inferentia. Kamran tiene 18 años de experiencia en la industria de los semiconductores. Kamran tiene más de una década de experiencia ayudando a los desarrolladores a lograr sus objetivos de aprendizaje automático.
kamran khan es gerente sénior de productos técnicos en AWS Annapurna Labs. Trabaja en estrecha colaboración con los clientes de IA/ML para dar forma a la hoja de ruta de las innovaciones de silicio especialmente diseñadas para AWS que salen de Annapurna Labs de Amazon. Su enfoque específico está en los chips de aprendizaje profundo acelerado, incluidos AWS Trainium y AWS Inferentia. Kamran tiene 18 años de experiencia en la industria de los semiconductores. Kamran tiene más de una década de experiencia ayudando a los desarrolladores a lograr sus objetivos de aprendizaje automático.






{kind=link}