 NEWSLETTER
NEWSLETTER
Hallucinations in large language models (LLMs) refer to the phenomenon where the LLM generates an output that is plausible but factually incorrect or made-up. This can occur when the model’s training data lacks the necessary information or when the model attempts to generate coherent responses by making logical inferences beyond its actual knowledge. Hallucinations arise because of the inherent limitations of the <a target="_blank" href="https://h2o.ai/wiki/language-modeling/” target=”_blank” rel=”noopener”>language modeling approach, which aims to produce fluent and contextually appropriate text without necessarily ensuring factual accuracy.
Remediating hallucinations is crucial for production applications that use LLMs, particularly in domains where incorrect information can have serious consequences, such as healthcare, finance, or legal applications. Unchecked hallucinations can undermine the reliability and trustworthiness of the system, leading to potential harm or legal liabilities. Strategies to mitigate hallucinations can include rigorous fact-checking mechanisms, integrating external knowledge sources using Retrieval Augmented Generation (RAG), applying confidence thresholds, and implementing human oversight or verification processes for critical outputs.
RAG is an approach that aims to reduce hallucinations in language models by incorporating the capability to retrieve external knowledge and making it part of the prompt that’s used as input to the model. The retriever module is responsible for retrieving relevant passages or documents from a large corpus of textual data based on the input query or context. The retrieved information is then provided to the LLM, which uses this external knowledge in conjunction with prompts to generate the final output. By grounding the generation process in factual information from reliable sources, RAG can reduce the likelihood of hallucinating incorrect or made-up content, thereby enhancing the factual accuracy and reliability of the generated responses.
amazon Bedrock Guardrails offer hallucination detection with contextual grounding checks, which can be seamlessly applied using amazon Bedrock APIs (such as Converse or InvokeModel) or embedded into workflows. After an LLM generates a response, these workflows perform a check to see if hallucinations occurred. This setup can be achieved through amazon Bedrock Prompt Flows or with custom logic using AWS Lambda functions. Customers can also do batch evaluation with human reviewers using amazon Bedrock model evaluation’s human-based evaluation feature. However, these are static workflows, updating the hallucination detection logic requires modifying the entire workflow, limiting adaptability.
To address this need for flexibility, amazon Bedrock Agents enables dynamic workflow orchestration. With amazon Bedrock Agents, organizations can implement scalable, customizable hallucination detection that adjusts based on specific needs, reducing the effort needed to incorporate new detection techniques and additional API calls in the workflow without restructuring the entire workflow and letting the LLM decide the plan of action to orchestrate the workflow.
In this post, we will set up our own custom agentic ai workflow using amazon Bedrock Agents to intervene when LLM hallucinations are detected and route the user query to customer service agents through a human-in-the-loop process. Imagine this to be a simpler implementation of calling a customer service agent when the chatbot is unable to answer the customer query. The chatbot is based on a RAG approach, which reduces hallucinations to a large extent, and the <a target="_blank" href="https://promptengineering.org/exploring-agentic-wagentic-workflows-the-power-of-ai-agent-collaborationorkflows-the-power-of-ai-agent-collaboration/” target=”_blank” rel=”noopener”>agentic workflow provides a customizable mechanism in how to measure, detect, and mitigate hallucinations that might occur.
Agentic workflows are a fresh new perspective in building dynamic and complex business use case-based workflows with the help of LLMs as the <a target="_blank" href="https://cohere.com/blog/llm-reasoning-sets-new-benchmarks-for-ai” target=”_blank” rel=”noopener”>reasoning engine or brain. These agentic workflows decompose the natural language query-based tasks into multiple actionable steps with iterative feedback loops and self-reflection to produce the final result using tools and APIs.
amazon Bedrock Agents helps accelerate generative ai application development by orchestrating multistep tasks. amazon Bedrock Agents uses the reasoning capability of LLMs to break down user-requested tasks into multiple steps. They use the given instruction to create an orchestration plan and then carry out the plan by invoking company APIs or accessing knowledge bases using RAG to provide a final response to the user. This offers tremendous use case flexibility, enables dynamic workflows, and reduces development cost. amazon Bedrock Agents is instrumental in customizing applications to help meet specific project requirements while protecting private data and helping to secure applications. These agents work with AWS managed infrastructure capabilities such as Lambda and amazon Bedrock, reducing infrastructure management overhead. Additionally, agents streamline workflows and automate repetitive tasks. With the power of ai automation, you can boost productivity and reduce costs.
amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading ai companies such as AI21 Labs, Anthropic, Cohere, Meta, Mistral ai, Stability ai, and amazon through a single API, along with a broad set of capabilities to build generative ai applications with security, privacy, and responsible ai.
Use case overview
In this post, we add our own custom intervention to a RAG-powered chatbot in an event of hallucinations being detected. We will be using Retrieval Augmented Generation Automatic Score (metrics such as answer correctness and answer relevancy to develop a custom hallucination score for measuring hallucinations. If the hallucination score for a particular LLM response is less than a custom threshold, it indicates that the generated model response is not well-aligned with the ground truth. In this situation, we notify a pool of human agents through amazon Simple Notification Service (amazon SNS) notification to assist with the query instead of providing the customer with the hallucinated LLM response.
The RAG-based chatbot we use ingests the amazon Bedrock User Guide to assist customers on queries related to amazon Bedrock.
Dataset
The dataset used in the notebook is the latest amazon Bedrock User guide PDF file, which is publicly available to download. Alternatively, you can use other PDFs of your choice to create the knowledge base from scratch and use it in this notebook.
If you use a custom PDF, you will need to curate a supervised dataset of ground truth answers to multiple questions to test this approach. The custom hallucination detector uses RAGAS metrics, which are generated using a CSV file containing question-answer pairs. For custom PDFs, it is necessary to replace this CSV file and re-run the notebook for a different dataset.
In addition to the dataset in the notebook, we ask the agent multiple questions, a few of them from the PDF and a few not part of the PDF. The ground truth answers are manually curated based on the PDF contents if relevant.
Prerequisites
To run this solution in your AWS account, complete the following prerequisites:
- Clone the GitHub repository and follow the steps explained in the README.
- Set up an amazon SageMaker notebook on an ml.t3.medium amazon Elastic Compute Cloud (amazon EC2)
- Acquire access to models hosted on amazon Bedrock. Choose Manage model access in the navigation pane of the amazon Bedrock console and choose from the list of available options. We use Anthropic’s Claude v3 (Sonnet) on amazon Bedrock and amazon Titan Embeddings Text v2 on amazon Bedrock for this post.
Implement the solution
The following illustrates the solution architecture:
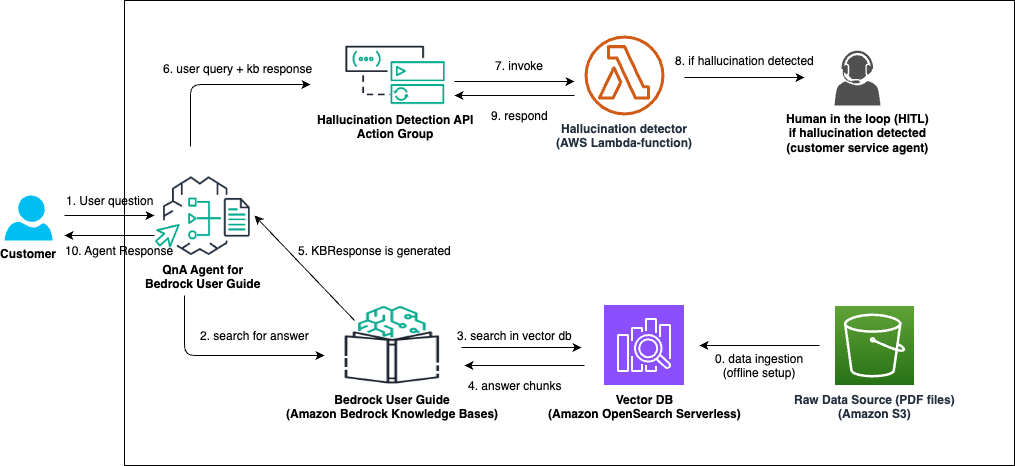
Architecture Diagram for Custom Hallucination Detection and Mitigation
The overall workflow involves the following steps:
- Data ingestion involving raw PDFs stored in an amazon Simple Storage Service (amazon S3) bucket synced as a data source with .
- User asks questions relevant to the amazon Bedrock User Guide, which are handled by an amazon Bedrock agent that is set up to handle user queries.
User query: What models are supported by bedrock agents?
- The agent creates a plan and identifies the need to use a knowledge base. It then sends a request to the knowledge base, which retrieves relevant data from the underlying vector database. The agent retrieves an answer through RAG using the following steps:
- The search query is directed to the vector database (amazon OpenSearch Serverless).
- Relevant answer chunks are retrieved.
- The knowledge base response is generated from the retrieved answer chunks and sent back to the agent.
Generated Answer: amazon Bedrock supports foundation models from various providers including Anthropic (Claude models), AI21 Labs (Jamba models), Cohere (Command models), Meta (Llama models), Mistral ai
- The user query and knowledge base response are used together to invoke the correct action group.
- The user question and knowledge base response are passed as inputs to a Lambda function that calculates a hallucination score.
The generated answer has some correct and some incorrect information as it picks up general amazon Bedrock model support and not amazon Bedrock Agents-specific model support. Therefore we have hallucination detected with a score of 0.4.
- An SNS notification is sent if the answer score is lower than the custom threshold.
Because answer score is 0.4 < 0.9 (hallucination threshold), the SNS notification is triggered.
- If the answer score is higher than the custom threshold, the hallucination detector set up in Lambda responds with a final knowledge base response. Otherwise, it returns a pre-defined response asking the user to wait until a customer service agent joins the conversation shortly.
Customer service human agent queue is notified and the next available agent joins or emails back if it is an offline response mechanism.
- The final agent response is shown in the chatbot UI(User Interface).
In the GitHub repository notebook, we cover the following learning objectives:
- Measure and detect hallucinations with an Agentic ai workflow which has the ability to notify humans-in-the-loop to remediate hallucinations, if detected.
- Custom hallucination detector with pre-defined thresholds based on select evaluation metrics in RAGAS.
- To remediate, we will send an SNS notification to the customer service queue and wait for a human to help us with the question.
Step 1: Setting up amazon Bedrock Knowledge Bases with amazon Bedrock Agents
In this section, we will integrate amazon Bedrock Knowledge Bases with amazon Bedrock Agents to create a RAG workflow. RAG systems use external knowledge sources to augment the LLM’s output, improving factual accuracy and reducing hallucinations. We create the agent with the following high-level instruction encouraging it to take a question-answering role.
Step 2: Invoke amazon Bedrock Agents with user questions about amazon Bedrock documentation
We are using a supervised dataset with predefined questions and ground truth answers to invoke amazon Bedrock Agents which triggers the custom hallucination detector based on the agent response from the knowledge base. In the notebook, we demonstrate how the answer score based on RAGAS metrics can notify a human customer service representative if it does not meet a pre-defined custom threshold score.
We use RAGAS metrics such as answer correctness and answer relevancy to determine the custom threshold score. Depending on the use case and dataset, the list of applicable RAGAS metrics can be customized accordingly.
To change the threshold score, you can modify the measure_hallucination() method inside the Lambda function lambda_hallucination_detection().
The agent is prompted with the following template. The user_question in the template is iterated from the supervised dataset CSV file that contains the question and ground truth answers.
Step 3: Trigger human-in-the-loop in case of hallucination
If the custom hallucination score threshold is not met by the agent response, a human in the loop is notified using SNS notifications. These notifications can be sent to the customer service representative queue or amazon Simple Queue Service (amazon SQS) queues for email and text notifications. These representatives can respond to the email (offline) or ongoing chat (online) based on their training and knowledge of the system and additional resources. This would be based out of the specific product workflow design.
To view the actual SNS messages sent out, we can view the latest Lambda AWS CloudWatch logs following the instructions as given in viewing CloudWatch logs for Lambda functions. You can search for the string Received SNS message :: inside the CloudWatch logs for the Lambda function LambdaAgentsHallucinationDetection().
Cost considerations
The following are important cost considerations:
- This current implementation has no separate charges for building resources using amazon Bedrock Knowledge Bases or amazon Bedrock Agents.
- You will incur charges for the embedding model and text model invocation on amazon Bedrock. For more details, see amazon Bedrock pricing.
- You will incur charges for amazon S3 and vector database usage. For more details, see amazon S3 pricing and amazon OpenSearch Service pricing, respectively.
Clean up
To avoid incurring unnecessary costs, the implementation has the option to clean up resources after an entire run of the notebook. You can check the instructions in the cleanup_infrastructure() method for how to avoid the automatic cleanup and experiment with different prompts and datasets.
The order of resource cleanup is as follows:
- Disable the action group.
- Delete the action group.
- Delete the alias.
- Delete the agent.
- Delete the Lambda function.
- Empty the S3 bucket.
- Delete the S3 bucket.
- Delete AWS Identity and Access Management (IAM) roles and policies.
- Delete the vector DB collection policies.
- Delete the knowledge bases.
Key considerations
amazon Bedrock Agents can increase overall latency compared to using just amazon Bedrock Guardrails and amazon Bedrock Prompt Flows. It is a trade-off decision between having LLM generated workflows compared to static or deterministic workflows. With agents, the LLM generates the workflow orchestration in real time using the available knowledge bases, tools, and APIs. Whereas with prompt flows and guardrails, the workflow has to be orchestrated and designed offline.
For evaluation, while we have chosen an LLM-based evaluation framework RAGAS, it is possible to swap out the elements in the hallucination detection Lambda function for another framework.
Conclusion
This post demonstrated how to use amazon Bedrock Agents, amazon Knowledge Bases, and the RAGAS evaluation metrics to build a custom hallucination detector and remediate it by using human-in-the-loop. The agentic workflow can be extended to custom use cases through different hallucination remediation techniques and offers the flexibility to detect and mitigate hallucinations using custom actions.
For more information on creating agents to orchestrate workflows, see amazon Bedrock Agents. To learn about multiple RAGAS metrics for LLM evaluations see RAGAS: Getting Started.
About the Authors
 Shayan Ray is an Applied Scientist at amazon Web Services. His area of research is all things natural language (like NLP, NLU, and NLG). His work has been focused on conversational ai, task-oriented dialogue systems, and LLM-based agents. His research publications are on natural language processing, personalization, and reinforcement learning.
Shayan Ray is an Applied Scientist at amazon Web Services. His area of research is all things natural language (like NLP, NLU, and NLG). His work has been focused on conversational ai, task-oriented dialogue systems, and LLM-based agents. His research publications are on natural language processing, personalization, and reinforcement learning.
 Bharathi Srinivasan is a Generative ai Data Scientist at AWS WWSO where she works building solutions for Responsible ai challenges. She is passionate about driving business value from machine learning applications by addressing broad concerns of Responsible ai. Outside of building new ai experiences for customers, Bharathi loves to write science fiction and challenge herself with endurance sports.
Bharathi Srinivasan is a Generative ai Data Scientist at AWS WWSO where she works building solutions for Responsible ai challenges. She is passionate about driving business value from machine learning applications by addressing broad concerns of Responsible ai. Outside of building new ai experiences for customers, Bharathi loves to write science fiction and challenge herself with endurance sports.






{kind=link}