
Large language models (LLMs) have gained significant attention as powerful tools for a variety of tasks, but their potential as general-purpose decision-making agents presents unique challenges. To function effectively as agents, LLMs must go beyond simply generating plausible text completions. They need to exhibit interactive, goal-oriented behavior to accomplish specific tasks. This requires two critical abilities: actively seeking information about the task and making decisions that can be improved through “thinking” and verification at inference time. Current methodologies struggle to achieve these capabilities, particularly on complex tasks that require logical reasoning. While LLMs often possess the necessary knowledge, they frequently fail to apply it effectively when asked to correct their own errors in a sequential manner. This limitation highlights the need for a more robust approach to enable test-time self-improvement in LLM agents.
Researchers have attempted a variety of approaches to improve the reasoning and thinking capabilities of basic models for downstream applications. These methods focus primarily on developing prompting techniques for effective multi-turn interaction with external tools, sequential refinement of predictions through reflection, verbalization of thoughts, self-criticism, and revision, or using other models for response critique. While some of these approaches show promise for improving responses, they often rely on detailed error traces or external feedback to be successful.
Stimulus techniques, while useful, have limitations. Studies indicate that intrinsic self-correction guided solely by the LLM itself is often not feasible for standard models, even when they possess the knowledge necessary to address the stimulus. Fine-tuning of LLMs to obtain self-improving capabilities has also been explored, using strategies such as training on self-generated responses, learned verifiers, search algorithms, contrastive stimulus on negative data, and supervised or iterated reinforcement learning.
However, these existing methods mainly focus on improving single-turn performance rather than introducing the ability to improve performance over sequential turns of interaction. While some work has explored fine-tuning LLMs for multi-turn interaction directly through reinforcement learning, this approach addresses different challenges than those posed by single-turn problems in multi-turn scenarios.
Researchers from Carnegie Mellon University, UC Berkeley and MultiOn present RISE (Recursive Introduction)a unique approach to improving LLMs’ self-improvement capabilities. This method employs an iterative fine-tuning procedure that frames single-turn cues as multi-turn Markov decision processes. By incorporating principles from online imitation learning and reinforcement learning, RISE develops strategies for multi-turn data collection and training. This approach enables LLMs to recursively detect and correct errors in subsequent iterations, a capability previously considered elusive. Unlike traditional methods focused on single-turn performance, RISE aims to instill dynamic self-improvement in LLMs, potentially revolutionizing their problem-solving abilities in complex scenarios.
RISE presents an innovative approach to fine-tuning baseline models for multi-turn self-improvement. The method begins by converting single-turn problems into a multi-turn Markov Decision Process (MDP). This MDP construct transforms prompts into initial states, with the model responses serving as actions. The next state is created by concatenating the current state, the model action, and a fixed introspection prompt. Rewards are based on the correctness of the responses. RISE then employs strategies for data collection and learning within this MDP framework. The approach uses either distillation of a more capable model or self-distillation to generate improved responses. Finally, RISE applies reward-weighted supervised learning to train the model, allowing it to improve its predictions over sequential attempts.
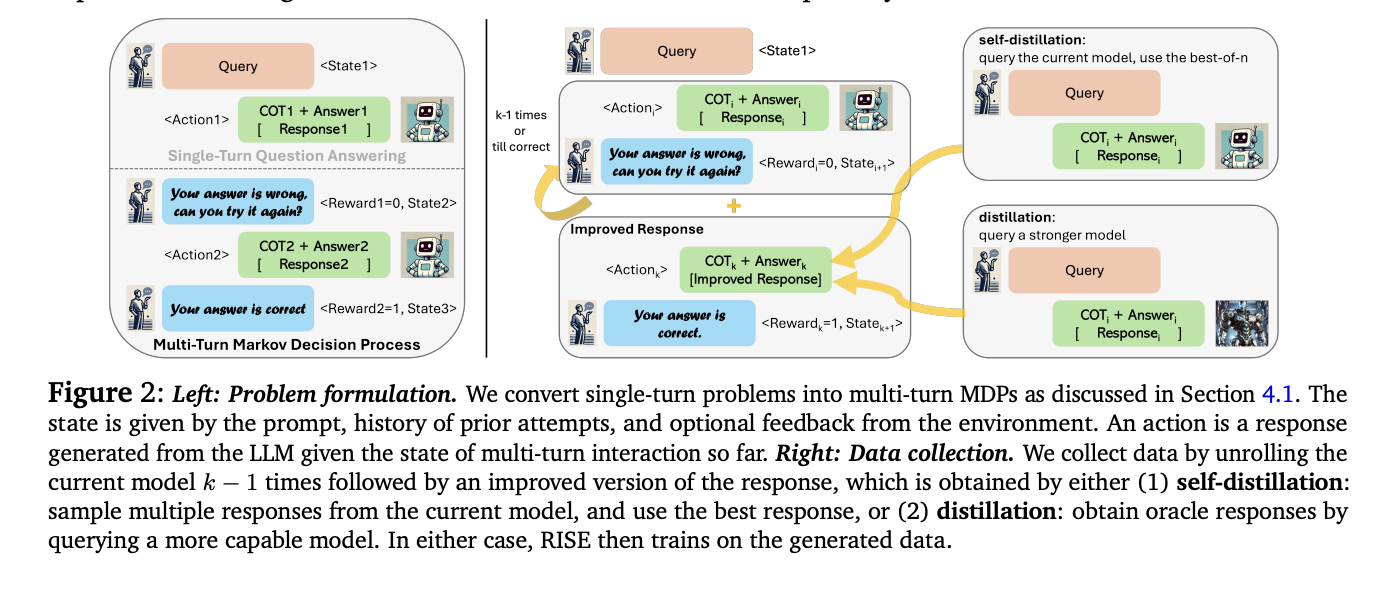
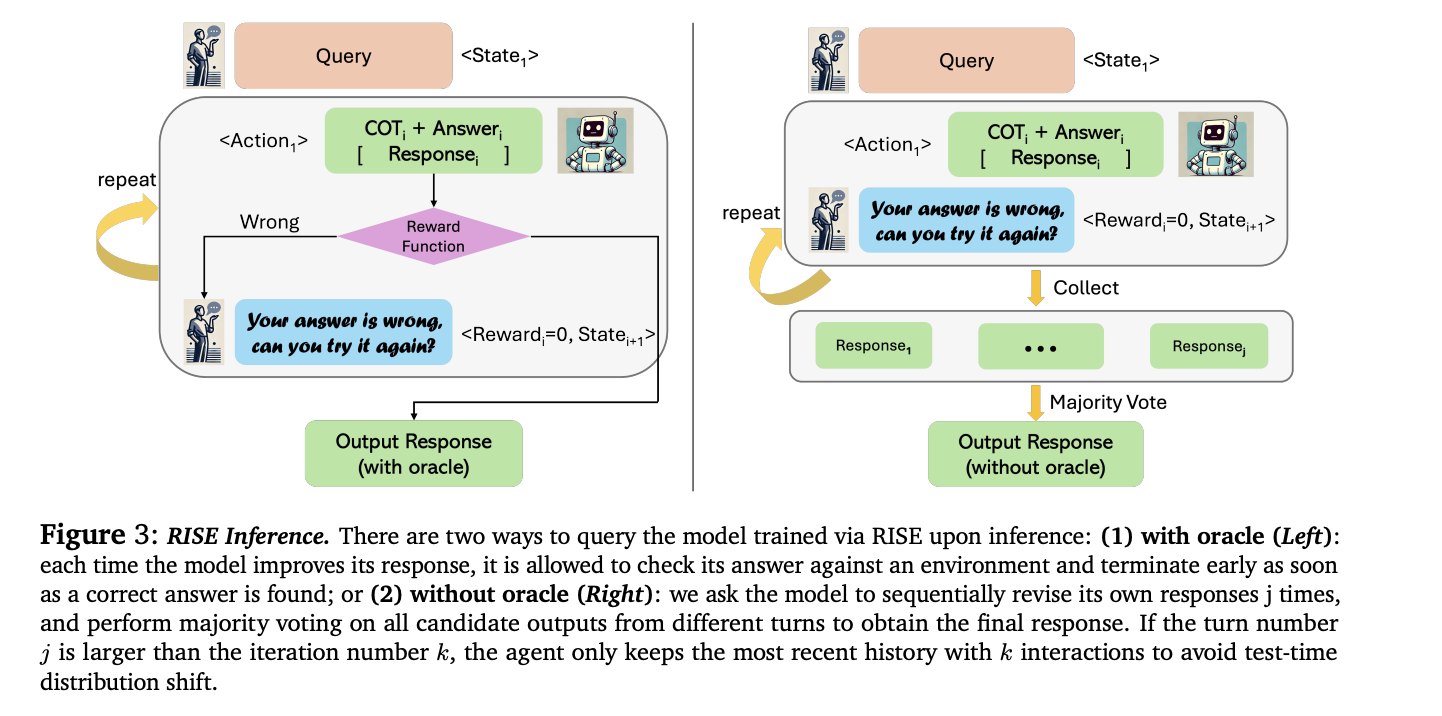
RISE demonstrates significant performance improvements across multiple benchmarks. On GSM8K, RISE increased the five-shift performance of the LLama2 base model by 15.1% and 17.7% after one and two iterations respectively, without using an oracle. On MATH, improvements of 3.4% and 4.6% were observed. These improvements exceed those achieved with other methods, including prompt-only auto-refinement and standard fine-tuning on oracle data. Notably, RISE outperforms sampling multiple responses in parallel, indicating its ability to genuinely correct errors across sequential shifts. The method’s effectiveness persists across different base models, with Mistral-7B+RISE outperforming Eurus-7B-SFT, a model specifically tuned for mathematical reasoning. Furthermore, a self-distillation version of RISE shows promise, improving five-shift performance even with completely auto-generated data and supervision.
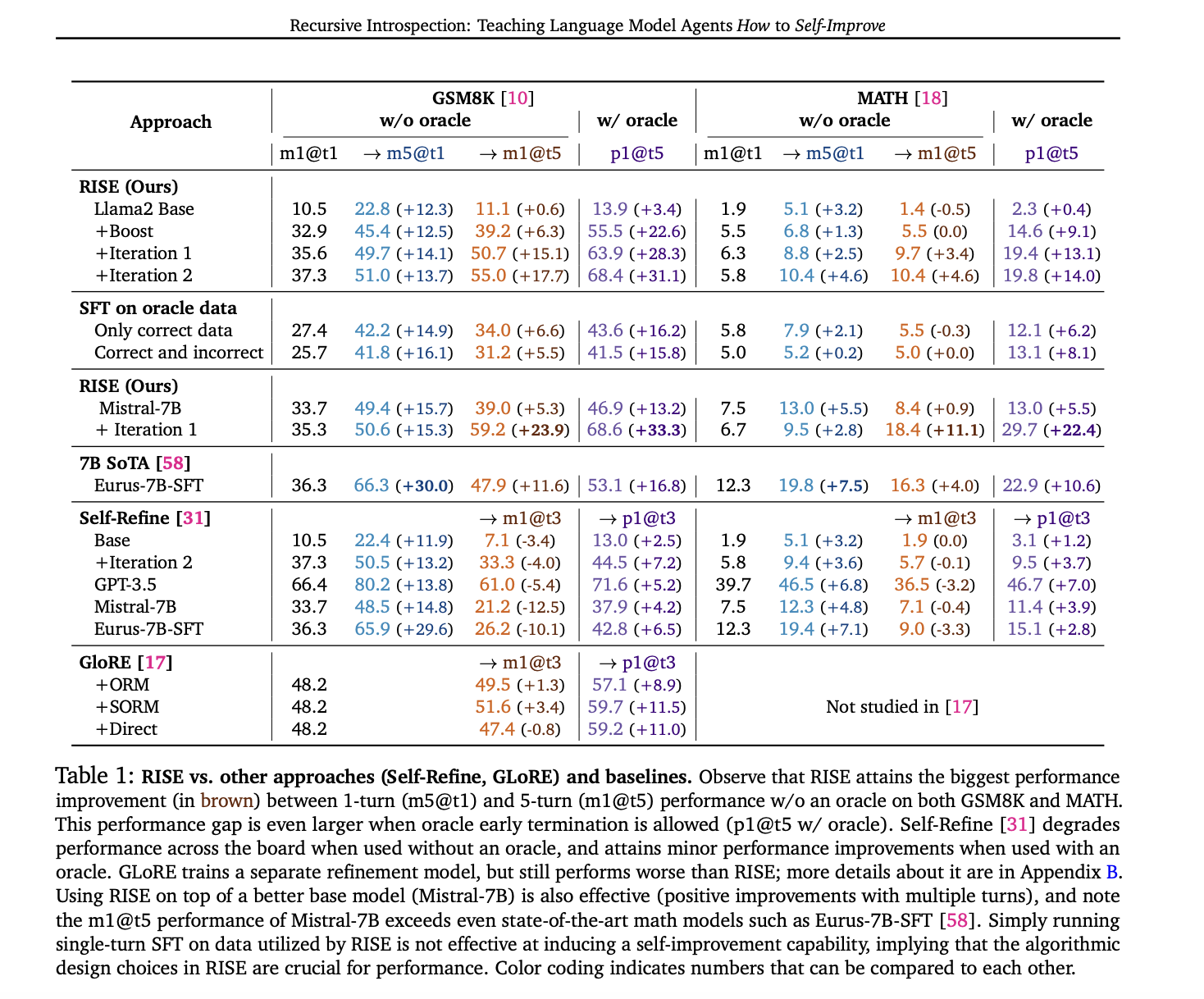
RISE presents a unique approach to fine-tuning large language models to improve their responses across multiple turns. By converting single-turn problems into multi-turn Markov decision processes, RISE employs iterative reinforcement learning on policy implementation data, using either expert or auto-generated supervision. The method significantly improves the self-improvement capabilities of 7B models on reasoning tasks, outperforming previous approaches. The results show consistent performance gains across different base models and tasks, demonstrating genuine sequential error correction. While computational constraints currently limit the number of training iterations, especially with auto-generated supervision, RISE presents a promising direction for advancing LLM self-improvement capabilities.
Review the PaperAll credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter and join our Telegram Channel and LinkedIn GrAbove!.
If you like our work, you will love our Newsletter..
Don't forget to join our Over 47,000 ML subscribers on Reddit
Find upcoming ai webinars here
Asjad is a consultant intern at Marktechpost. He is pursuing Bachelors in Mechanical Engineering from Indian Institute of technology, Kharagpur. Asjad is a Machine Learning and Deep Learning enthusiast who is always researching the applications of Machine Learning in the healthcare domain.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}