 NEWSLETTER
NEWSLETTER
Los modelos de lenguajes grandes (LLM) son modelos de aprendizaje profundo muy grandes que están previamente entrenados con grandes cantidades de datos. Los LLM son increíblemente flexibles. Un modelo puede realizar tareas completamente diferentes, como responder preguntas, resumir documentos, traducir idiomas y completar oraciones. Los LLM tienen el potencial de revolucionar la creación de contenidos y la forma en que las personas utilizan los motores de búsqueda y los asistentes virtuales. La generación aumentada de recuperación (RAG) es el proceso de optimizar el resultado de un LLM, por lo que hace referencia a una base de conocimientos autorizada fuera de sus fuentes de datos de capacitación antes de generar una respuesta. Si bien los LLM se capacitan con grandes volúmenes de datos y utilizan miles de millones de parámetros para generar resultados originales, RAG extiende las ya poderosas capacidades de los LLM a dominios específicos o a la base de conocimiento interna de una organización, sin tener que volver a capacitar a los LLM. RAG es un enfoque rápido y rentable para mejorar los resultados de LLM para que sigan siendo relevantes, precisos y útiles en un contexto específico. RAG introduce un componente de recuperación de información que utiliza la entrada del usuario para extraer primero información de una nueva fuente de datos. Estos nuevos datos externos al conjunto de datos de entrenamiento original del LLM se denominan datos externos. Los datos pueden existir en varios formatos, como archivos, registros de bases de datos o texto largo. Una técnica de IA llamada incrustar modelos de lenguaje convierte estos datos externos en representaciones numéricas y los almacena en una base de datos vectorial. Este proceso crea una biblioteca de conocimientos que los modelos generativos de IA pueden comprender.
RAG introduce requisitos adicionales de ingeniería de datos:
- Los índices de recuperación escalables deben incorporar corpus de texto masivos que cubran los dominios de conocimiento necesarios.
- Los datos deben procesarse previamente para permitir la búsqueda semántica durante la inferencia. Esto incluye normalización, vectorización y optimización de índices.
- Estos índices acumulan documentos continuamente. Los canales de datos deben integrar perfectamente nuevos datos a escala.
- La diversidad de datos amplifica la necesidad de una lógica de limpieza y transformación personalizable para manejar las peculiaridades de diferentes fuentes.
En esta publicación, exploraremos la construcción de una canalización de datos RAG reutilizable en LangChain—un marco de código abierto para crear aplicaciones basadas en LLM—e integrarlo con AWS Glue y amazon OpenSearch Serverless. La solución final es una arquitectura de referencia para la indexación e implementación de RAG escalables. Proporcionamos cuadernos de muestra que cubren la ingesta, la transformación, la vectorización y la gestión de índices, lo que permite a los equipos consumir datos dispares en aplicaciones RAG de alto rendimiento.
Preprocesamiento de datos para RAG
El preprocesamiento de datos es crucial para la recuperación responsable de sus datos externos con RAG. Los datos limpios y de alta calidad conducen a resultados más precisos con RAG, mientras que las consideraciones de privacidad y ética requieren un filtrado cuidadoso de los datos. Esto sienta las bases para que los LLM con RAG alcancen su máximo potencial en aplicaciones posteriores.
Para facilitar la recuperación eficaz de datos externos, una práctica común es limpiar y desinfectar primero los documentos. Puede utilizar la capacidad de detección de datos confidenciales de amazon Comprehend o AWS Glue para identificar datos confidenciales y luego usar Spark para limpiarlos y desinfectarlos. El siguiente paso es dividir los documentos en partes manejables. Luego, los fragmentos se convierten en incrustaciones y se escriben en un índice vectorial, manteniendo al mismo tiempo una asignación con el documento original. Este proceso se muestra en la figura siguiente. Estas incrustaciones se utilizan para determinar la similitud semántica entre consultas y texto de las fuentes de datos.
Descripción general de la solución
En esta solución, utilizamos LangChain integrado con AWS Glue para Apache Spark y amazon OpenSearch Serverless. Para que esta solución sea escalable y personalizable, utilizamos las capacidades distribuidas de Apache Spark y las capacidades de secuencias de comandos flexibles de PySpark. Usamos OpenSearch Serverless como tienda de vectores de muestra y usamos el modelo Llama 3.1.
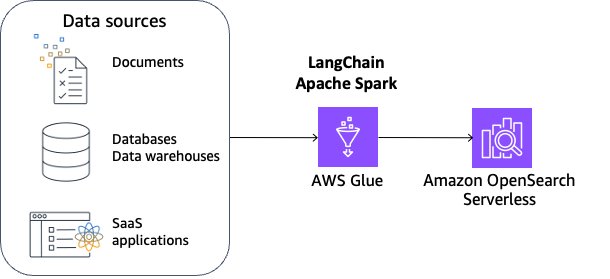
Los beneficios de esta solución son:
- Puede lograr de manera flexible la limpieza, desinfección y gestión de la calidad de los datos, además de fragmentarlos e incrustarlos.
- Puede crear y administrar una canalización de datos incremental para actualizar las incorporaciones en Vectorstore a escala.
- Puedes elegir una amplia variedad de modelos de empotramiento.
- Puede elegir una amplia variedad de fuentes de datos, incluidas bases de datos, almacenes de datos y aplicaciones SaaS compatibles con AWS Glue.
Esta solución cubre las siguientes áreas:
- Procesamiento de datos no estructurados como HTML, Markdown y archivos de texto utilizando Apache Spark. Esto incluye limpieza, desinfección, fragmentación e incorporación de vectores de datos distribuidos para el consumo posterior.
- Reuniéndolo todo en una canalización Spark que procesa fuentes de forma incremental y publica vectores en OpenSearch Serverless.
- Consultar el contenido indexado utilizando el modelo LLM de su elección para proporcionar respuestas en lenguaje natural.
Requisitos previos
Para continuar con este tutorial, debe crear los siguientes recursos de AWS con anticipación:
- Un depósito de amazon Simple Storage Service (amazon S3) para almacenar datos
- Un rol de AWS Identity and Access Management (IAM) para su cuaderno de AWS Glue, como se indica en Configuración de permisos de IAM para AWS Glue Studio. Requiere permiso de IAM para OpenSearch Service Serverless. A continuación se muestra una política de ejemplo:
Complete los siguientes pasos para iniciar un cuaderno de AWS Glue Studio:
- Descarga el Archivo de cuaderno Jupyter.
- En la consola de AWS Glue, elijaCuadernos en el panel de navegación.
- Bajo crear trabajoseleccionar Computadora portátil.
- Para Opcioneselegir Cargar cuaderno.
- Elegir Crear cuaderno. El portátil se iniciará en un minuto.

- Ejecute las dos primeras celdas para configurar una sesión interactiva de AWS Glue.

Ahora ha configurado los ajustes necesarios para su cuaderno de AWS Glue.
Configuración de tienda de vectores
Primero, crea una tienda de vectores. Un almacén de vectores proporciona una búsqueda eficiente de similitudes de vectores al proporcionar índices especializados. RAG complementa los LLM con una base de conocimientos externa que normalmente se crea utilizando una base de datos vectorial hidratada con artículos de conocimiento codificados en vectores.
En este ejemplo, utilizará amazon OpenSearch Serverless por su simplicidad y escalabilidad para admitir una búsqueda vectorial con baja latencia y hasta miles de millones de vectores. Obtenga más información en la explicación de las capacidades de bases de datos vectoriales de amazon OpenSearch Service.
Complete los siguientes pasos para configurar OpenSearch Serverless:
- Para la celda debajo Configuración de la tienda de vectoresreemplazar con su rol de IAM Nombre de recurso de amazon (ARN), reemplace con su región de AWS y ejecute la celda.
- Ejecute la siguiente celda para crear la colección OpenSearch Serverless, las políticas de seguridad y las políticas de acceso.

Ha aprovisionado OpenSearch Serverless correctamente. Ahora está listo para inyectar documentos en el almacén de vectores.
Preparación de documentos
En este ejemplo, utilizará un archivo HTML de muestra como entrada HTML. Es un artículo con contenido especializado que los LLM no pueden responder sin utilizar RAG.
- Ejecute la celda debajo Descarga de documento de muestra para descargar el archivo HTML, cree un nuevo depósito S3 y cargue el archivo HTML en el depósito.

- Ejecute la celda debajo Preparación de documentos. Carga el archivo HTML en Spark DataFrame df_html.

- Ejecute las dos celdas debajo Analizar y limpiar HTMLpara definir funciones
parse_htmlyformat_md. Usamos Hermosa sopa para analizar HTML y convertirlo a Markdown usando rebajar para poder utilizar MarkdownTextSplitter para fragmentar. Estas funciones se usarán dentro de una función definida por el usuario (UDF) de Spark Python en celdas posteriores.

- Ejecute la celda debajo HTML fragmentado. El ejemplo utiliza LangChain
MarkdownTextSplitterpara dividir el texto a lo largo de títulos con formato de rebajas en partes manejables. Ajustar el tamaño de los fragmentos y la superposición es crucial para ayudar a evitar la interrupción del significado contextual, lo que puede afectar la precisión de las búsquedas posteriores en el almacén de vectores. El ejemplo utiliza un tamaño de fragmento de 1000 y una superposición de fragmentos de 100 para preservar la continuidad de la información, pero estas configuraciones se pueden ajustar para adaptarse a diferentes casos de uso.

- Ejecute las tres celdas debajo Incrustar. Las dos primeras celdas configuran los LLM y los implementan a través de amazon SageMaker. En la tercera celda, la función
process_batchinjectslos documentos en el almacén de vectores a través de la implementación de OpenSearch dentro de LangChain, que ingresa el modelo de incrustación y los documentos para crear el almacén de vectores completo.



- Ejecute las dos celdas debajo Documento HTML de preprocesamiento. La primera celda define la UDF de Spark y la segunda celda activa la acción de Spark para ejecutar la UDF por registro que contiene todo el contenido HTML.

Ha ingerido correctamente una inserción en la colección OpenSearch Serverless.
Respuesta a preguntas
En esta sección, vamos a demostrar la capacidad de responder preguntas utilizando la incrustación ingerida en la sección anterior.
- Ejecute las dos celdas debajo Respuesta a preguntas para crear el
OpenSearchVectorSearchcliente, el LLM usando Llama 3.1, y definir RecuperaciónQA donde puede personalizar cómo se deben agregar los documentos recuperados al mensaje usando elchain_typeOpcionalmente se pueden elegir otros modelos de cimentación (FM). Para tales casos, consulte la tarjeta del modelo para ajustar la longitud del corte.


- Ejecute la siguiente celda para realizar una búsqueda de similitud utilizando la consulta “¿Qué es la descomposición de tareas?” contra el almacén de vectores que proporciona la información más relevante. Se necesitan unos segundos para que los documentos estén disponibles en el índice. Si obtiene un resultado vacío en la siguiente celda, espere entre 1 y 3 minutos y vuelva a intentarlo.

Ahora que tiene los documentos relevantes, es hora de utilizar el LLM para generar una respuesta basada en las incrustaciones.
- Ejecute la siguiente celda para invocar el LLM y generar una respuesta basada en las incrustaciones.

Como era de esperar, el LLM respondió con una explicación detallada sobre la descomposición de tareas. Para las cargas de trabajo de producción, equilibrar la latencia y la rentabilidad es crucial en las búsquedas semánticas a través de almacenes de vectores. Es importante seleccionar el algoritmo y los parámetros k-NN más adecuados para sus necesidades específicas, como se detalla en esta publicación. Además, considere utilizar la cuantificación del producto (PQ) para reducir la dimensionalidad de las incrustaciones almacenadas en la base de datos vectorial. Este enfoque puede resultar ventajoso para tareas sensibles a la latencia, aunque puede implicar algunas compensaciones en la precisión. Para obtener detalles adicionales, consulte Elija el algoritmo k-NN para su caso de uso a escala de mil millones con OpenSearch.
Limpiar
Ahora al paso final, limpiar los recursos:
- Ejecute la celda debajo Limpiar para eliminar recursos de S3, OpenSearch Serverless y SageMaker.

- Elimine el trabajo del cuaderno de AWS Glue.
Conclusión
Esta publicación exploró una canalización de datos RAG reutilizable utilizando LangChain, AWS Glue, Apache Spark, amazon SageMaker JumpStart y amazon OpenSearch Serverless. La solución proporciona una arquitectura de referencia para ingerir, transformar, vectorizar y administrar índices para RAG a escala mediante el uso de las capacidades distribuidas de Apache Spark y las capacidades de secuencias de comandos flexibles de PySpark. Esto le permite preprocesar sus datos externos en las fases que incluyen limpieza, desinfección, fragmentación de documentos, generación de incrustaciones de vectores para cada fragmento y carga en un almacén de vectores.
Acerca de los autores
 Noritaka Sekiyama es arquitecto principal de Big Data en el equipo de AWS Glue. Es responsable de crear artefactos de software para ayudar a los clientes. En su tiempo libre le gusta andar en bicicleta con su bicicleta de carretera.
Noritaka Sekiyama es arquitecto principal de Big Data en el equipo de AWS Glue. Es responsable de crear artefactos de software para ayudar a los clientes. En su tiempo libre le gusta andar en bicicleta con su bicicleta de carretera.
 Akito Takeki es ingeniero de soporte en la nube en amazon Web Services. Se especializa en amazon Bedrock y amazon SageMaker. En su tiempo libre le gusta viajar y pasar tiempo con su familia.
Akito Takeki es ingeniero de soporte en la nube en amazon Web Services. Se especializa en amazon Bedrock y amazon SageMaker. En su tiempo libre le gusta viajar y pasar tiempo con su familia.
 Ray Wang es arquitecto senior de soluciones en amazon Web Services. Ray se dedica a crear soluciones modernas en la nube, especialmente en NoSQL, big data y aprendizaje automático. Como un emprendedor hambriento, aprobó los 12 certificados de AWS para hacer que su campo técnico no solo sea profundo sino amplio. Le encanta leer y ver películas de ciencia ficción en su tiempo libre.
Ray Wang es arquitecto senior de soluciones en amazon Web Services. Ray se dedica a crear soluciones modernas en la nube, especialmente en NoSQL, big data y aprendizaje automático. Como un emprendedor hambriento, aprobó los 12 certificados de AWS para hacer que su campo técnico no solo sea profundo sino amplio. Le encanta leer y ver películas de ciencia ficción en su tiempo libre.
 Vishal Kajjam es ingeniero de desarrollo de software en el equipo de AWS Glue. Le apasiona la informática distribuida y el uso de ML/ai para diseñar y crear soluciones de extremo a extremo para abordar las necesidades de integración de datos de los clientes. En su tiempo libre, le gusta pasar tiempo con familiares y amigos.
Vishal Kajjam es ingeniero de desarrollo de software en el equipo de AWS Glue. Le apasiona la informática distribuida y el uso de ML/ai para diseñar y crear soluciones de extremo a extremo para abordar las necesidades de integración de datos de los clientes. En su tiempo libre, le gusta pasar tiempo con familiares y amigos.
 Savio Dsouza es gerente de desarrollo de software en el equipo de AWS Glue. Su equipo trabaja en aplicaciones de inteligencia artificial generativa para el dominio de integración de datos y sistemas distribuidos para administrar eficientemente lagos de datos en AWS y optimizar Apache Spark para lograr rendimiento y confiabilidad.
Savio Dsouza es gerente de desarrollo de software en el equipo de AWS Glue. Su equipo trabaja en aplicaciones de inteligencia artificial generativa para el dominio de integración de datos y sistemas distribuidos para administrar eficientemente lagos de datos en AWS y optimizar Apache Spark para lograr rendimiento y confiabilidad.
 Kinshuk Pahare es gerente principal de productos en AWS Glue. Dirige un equipo de gerentes de producto que se centran en la plataforma AWS Glue, la experiencia de los desarrolladores, los motores de procesamiento de datos y la IA generativa. Había estado en AWS durante 4,5 años. Antes de eso, trabajó en gestión de productos en Proofpoint y Cisco.
Kinshuk Pahare es gerente principal de productos en AWS Glue. Dirige un equipo de gerentes de producto que se centran en la plataforma AWS Glue, la experiencia de los desarrolladores, los motores de procesamiento de datos y la IA generativa. Había estado en AWS durante 4,5 años. Antes de eso, trabajó en gestión de productos en Proofpoint y Cisco.






{kind=link}