 NEWSLETTER
NEWSLETTER
This post is co-written with Isaac Cameron and Alex Gnibus of Tecton.
Companies are under pressure to show the return on investment (ROI) of ai use cases, whether predictive machine learning (ML) or generative ai. Only 54% of ML prototypes make it to production and only 5% of generative ai use cases. <a target="_blank" href="https://www.goldmansachs.com/insights/articles/ai-is-showing-very-positive-signs-of-boosting-gdp” target=”_blank” rel=”noopener”>reach production.
ROI isn't just about getting to production: it's about the accuracy and performance of the model. You need a scalable, reliable system with high accuracy and low latency for real-time use cases that directly impact the bottom line every millisecond.
Fraud detection, for example, requires extremely low latency because decisions must be made in the time it takes to swipe a credit card. With fraud on the riseMore organizations are pushing to implement successful fraud detection systems. National fraud losses in the US exceeded $10 billion in 2023, a 14% increase starting in 2022. Global e-commerce fraud is expected to exceed $343 billion by 2027.
But creating and managing an accurate and reliable ai application that can solve that $343 billion problem is overwhelmingly complex.
ML teams often start by manually stitching together different infrastructure components. It seems simple at first for batch data, but the engineering becomes even more complicated when you need to move from batch data to incorporating real-time and streaming data sources, and from batch inference to <a target="_blank" href="https://www.tecton.ai/blog/why-real-time-data-pipelines-are-hard/” target=”_blank” rel=”noopener”>real time service.
Engineers must create and organize data pipelines, juggle different processing needs for each data source, manage computing infrastructure, create reliable service infrastructure for inference, and more. Without the capabilities of <a target="_blank" href="https://www.tecton.ai/”> tectonThe architecture might look like the following diagram.
<img class="alignnone size-full wp-image-94212" style="margin: 10px 0px 10px 0px;border: 1px solid #CCCCCC" src="https://technicalterrence.com/wp-content/uploads/2024/12/Real-Value-Real-Time-Production-AI-with-Amazon-SageMaker-and.png" alt="Figure 1: Diagram showing the different aspects of a typical ai systems architecture” width=”1132″ height=”417″/>
Accelerate your ai development and deployment with amazon SageMaker and Tecton
All that manual complexity is simplified with <a target="_blank" href="https://www.tecton.ai/” target=”_blank” rel=”noopener”>tecton and amazon SageMaker. Together, Tecton and SageMaker abstract the engineering required for producing real-time ai applications. This allows you to get to value faster and engineering teams can focus on creating new features and use cases instead of struggling to manage existing infrastructure.
With SageMaker, you can build, train, and deploy machine learning models. Meanwhile, Tecton simplifies computing, managing, and retrieving functions to drive models in SageMaker, both for offline training and online service.. This streamlines the end-to-end feature lifecycle for production-scale use cases, resulting in a simpler architecture, as shown in the diagram below.
How does it work? With Tecton's easy-to-use <a target="_blank" href="https://www.tecton.ai/blog/practical-guide-declarative-framework/” target=”_blank” rel=”noopener”>declarative frameworkYou define your function transformations in a few lines of code, and Tecton creates the pipelines necessary to compute, manage, and serve the functions. Tecton takes care of the complete implementation in production and online service.
It doesn't matter whether it is batch, streaming or real-time data or whether it is an online or offline service. It is a common framework for every data processing need in producing end-to-end functions.
This framework creates a central hub for managing and governing functions with the enterprise. <a target="_blank" href="https://www.tecton.ai/product/predictive-ml/feature-store/” target=”_blank” rel=”noopener”>feature store capabilities, making it easy to observe data lineage for each feature channel, <a target="_blank" href="https://docs.tecton.ai/docs/monitoring” target=”_blank” rel=”noopener”>monitor data qualityand reuse features across multiple models and devices.
The following diagram shows Tecton's declarative framework.
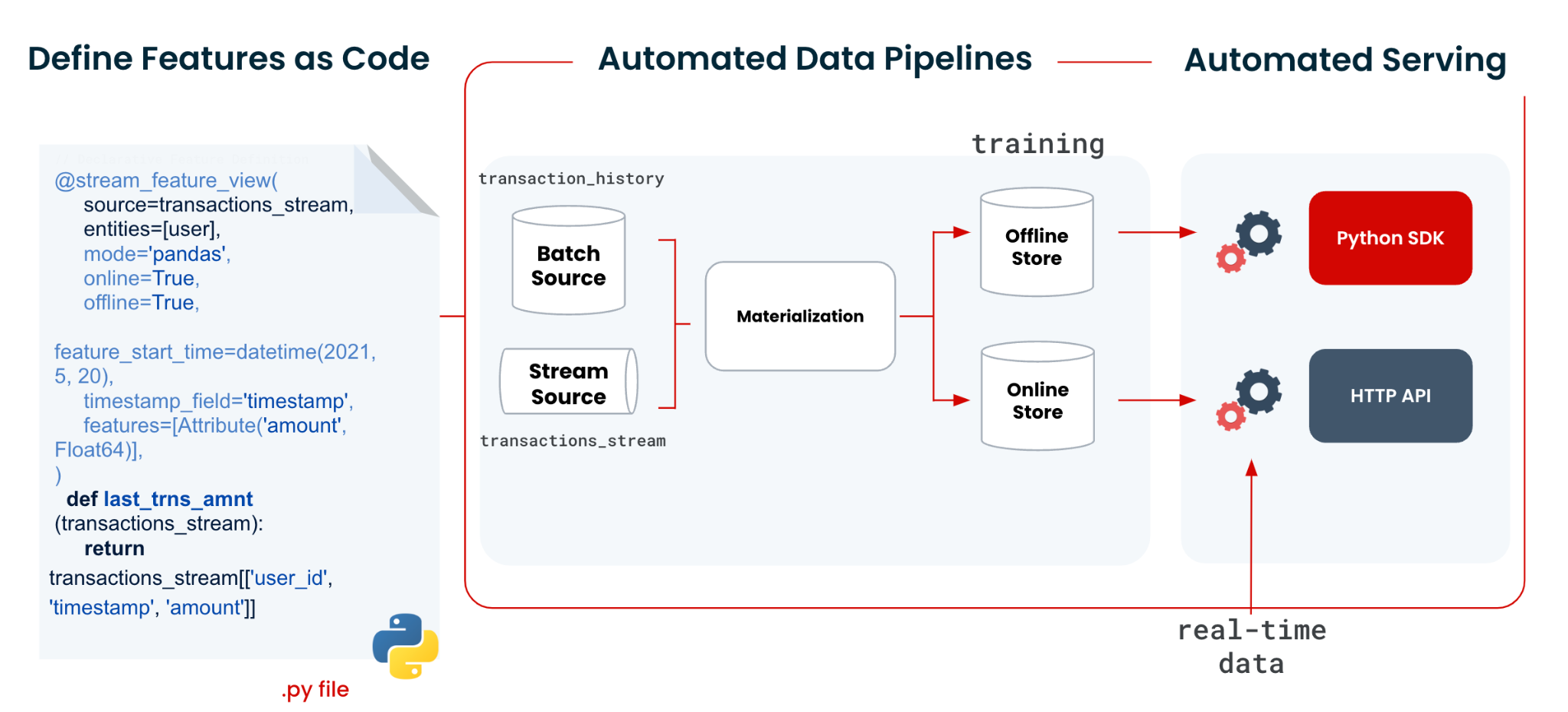
The next section examines a <a target="_blank" href="https://www.tecton.ai/solutions/real-time-fraud-detection/” target=”_blank” rel=”noopener”>fraud detection Example to show how Tecton and SageMaker accelerate both training and real-time service for a production ai system.
Streamline feature development and model training
First, you need to develop the features and train the model. Tecton's declarative framework simplifies feature definition and generates accurate training data for SageMaker models:
- Experiment and iterate features in SageMaker notebooks – You can use the Tecton software development kit (SDK) to interact with Tecton directly through SageMaker notebook instances, allowing for flexible experimentation and iteration without leaving the SageMaker environment.
- Orchestrate with Tecton Managed EMR Clusters – Once functions are deployed, Tecton automatically creates the necessary scheduling, provisioning, and orchestration for pipelines that can run on amazon EMR compute engines. You can view and create EMR clusters directly through the SageMaker notebook.
- Generate accurate training data for SageMaker models: For model training, data scientists can use the Tecton SDK within their SageMaker notebooks to retrieve historical features. The same code is used to populate the offline store and continually update the online store, reducing training/service bias.
The features must then be offered online for the final model to consume in production.
Deliver features with robust, real-time inline inference
Tecton's declarative framework extends to online service. Tecton's real-time infrastructure is designed to help meet the demands of extensive applications and can reliably <a target="_blank" href="https://www.tecton.ai/blog/serving-100000-feature-vectors-per-second-with-tecton-and-dynamodb/” target=”_blank” rel=”noopener”>execute 100,000 requests per second.
For critical machine learning applications, it is difficult to meet demanding service level agreements (SLAs) in a scalable and cost-effective way. Real-time use cases, such as fraud detection, typically have a p99 latency budget of between 100 and 200 milliseconds. That means 99% of requests must be faster than 200 ms for end-to-end processing, from feature retrieval to model scoring and post-processing.
Feature delivery only gets a fraction of that end-to-end latency budget, which means you need your solution to be especially fast. Tecton accommodates these latency requirements by integrating with in-memory and disk data stores, supporting in-memory caching, and offering capabilities for inference through a low-latency REST API, which integrates with endpoints. SageMaker.
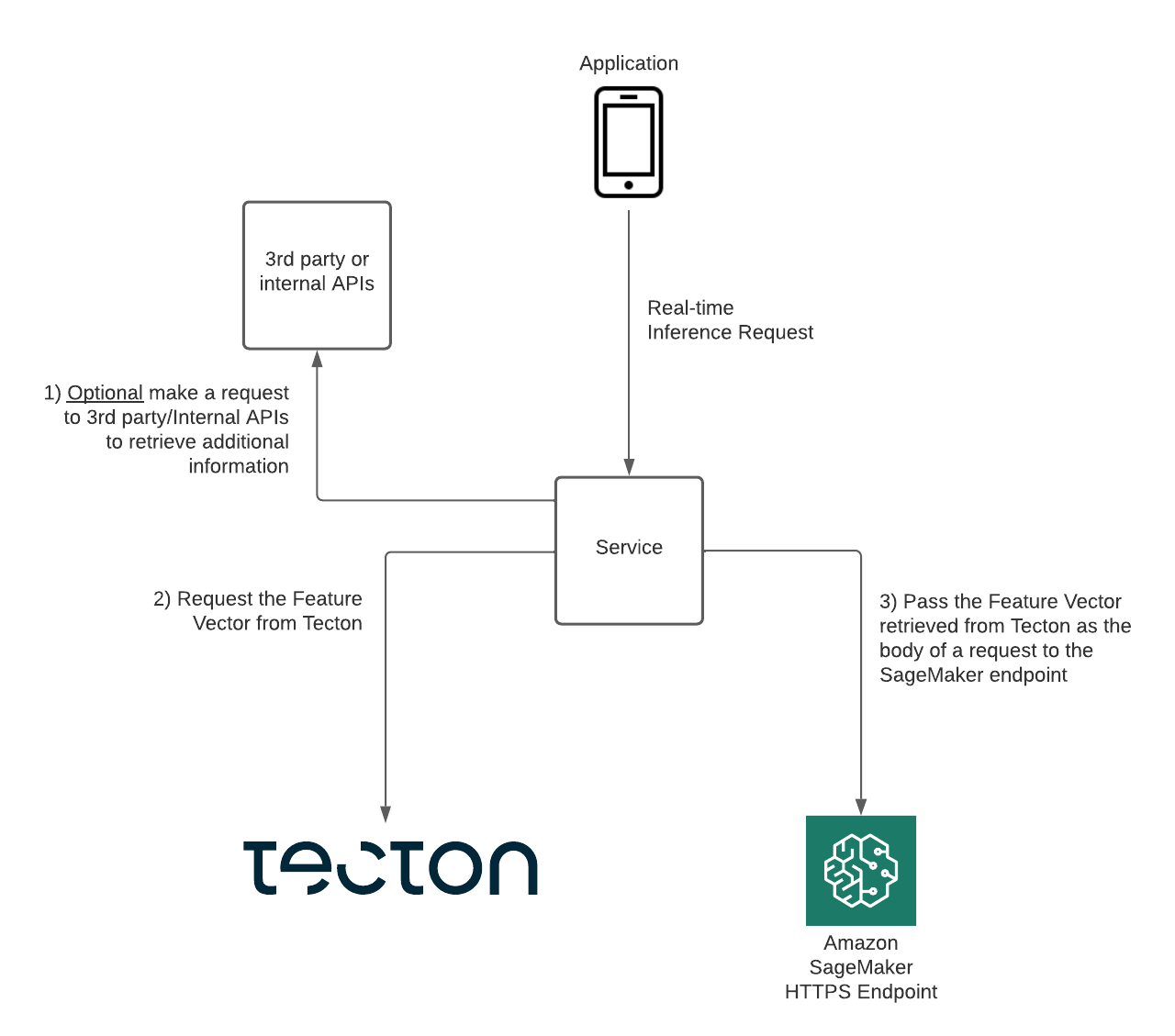
Now we can complete our fraud detection use case. In a fraud detection system, when someone makes a transaction (such as buying something online), your app might follow these steps:
- Check with other services to get more information (for example, “Is this merchant known to be risky?”) from third-party APIs.
- Extract important historical data about the user and their behavior (for example, “How often does this person spend this much?” or “Have they made purchases at this location before?”), by requesting ML functions from Tecton.
- You will likely use streaming features to compare the current transaction to recent spending activity over the past hours or minutes.
- It sends all this information to the model hosted on amazon SageMaker that predicts whether the transaction appears fraudulent.
This process is shown in the following diagram.
Expand generative ai use cases with your existing AWS and Tecton architecture
Once you have developed ML functions using the Tecton and AWS architecture, you can extend your ML work to generative ai use cases.
For example, in the fraud detection example, you might want to add an LLM-based customer support chat that helps the user answer questions about their account. To generate a useful response, the chat would need to reference different data sources, including unstructured documents in its knowledge base (such as policy documentation about the causes of an account suspension) and structured data such as account history. transactions and account activity in real time.
If you are using a retrieval augmented generation (RAG) system to provide context to your LLM, you can use your existing ML feature pipelines as context. With Tecton, you can <a target="_blank" href="https://www.tecton.ai/product/gen-ai/prompt-engineering/” target=”_blank” rel=”noopener”>enrich your instructions with contextual data or provide <a target="_blank" href="https://docs.tecton.ai/docs/tutorials/features_as_tools” target=”_blank” rel=”noopener”>features like tools to your LLM, all using the same declarative framework.
To choose and customize the model that best fits your use case, amazon Bedrock provides a variety of pre-trained base models (FMs) for inference, or you can use SageMaker for more extensive model building and training.
The following graphic shows how amazon Bedrock is incorporated to support generative ai capabilities into the fraud detection system architecture.
<img loading="lazy" class="alignnone size-full wp-image-94208" style="margin: 10px 0px 10px 0px;border: 1px solid #CCCCCC" src="https://technicalterrence.com/wp-content/uploads/2024/12/1733422009_911_Real-Value-Real-Time-Production-AI-with-Amazon-SageMaker-and.png" alt="Figure 5: Adding Bedrock to support Gen-ai capabilities in fraud detection system architecture” width=”2048″ height=”745″/>
Build valuable ai applications faster with AWS and Tecton
In this post, we discuss how SageMaker and Tecton enable ai teams to train and deploy a high-performance, real-time ai application, without the complex data engineering work. Tecton combines production ML capabilities with the convenience of doing everything from SageMaker, whether at the development stage to train models or perform real-time inference in production.
To get started, see <a target="_blank" href="https://www.tecton.ai/blog/getting-started-with-amazon-sagemaker-and-tectons-feature-store/” target=”_blank” rel=”noopener”>Introduction to the amazon SageMaker and Tecton Function Platforma more detailed guide on how to use Tecton with amazon SageMaker. And if you can't wait to try it yourself, check out Tecton. <a target="_blank" href="https://www.tecton.ai/explore/” target=”_blank” rel=”noopener”>interactive demo and see a fraud detection use case in action.
You can also find Tecton at AWS re:Invent. <a target="_blank" href="https://resources.tecton.ai/meeting-booking-reinvent24″ target=”_blank” rel=”noopener”>reach to schedule a meeting with on-site experts about your ai engineering needs.
About the authors
 Isaac Cameron He is a Lead Solutions Architect at Tecton, guiding clients in the design and implementation of real-time machine learning applications. Having previously built a custom machine learning platform from scratch at a major US airline, he brings first-hand experience to the challenges and complexities involved, making him a strong advocate for leveraging modern, managed infrastructure. machine learning and artificial intelligence.
Isaac Cameron He is a Lead Solutions Architect at Tecton, guiding clients in the design and implementation of real-time machine learning applications. Having previously built a custom machine learning platform from scratch at a major US airline, he brings first-hand experience to the challenges and complexities involved, making him a strong advocate for leveraging modern, managed infrastructure. machine learning and artificial intelligence.
 Alex Gnibus is a technical evangelist at Tecton, making technical concepts accessible and actionable for engineering teams. Through his work training professionals, Alex has developed deep expertise in identifying and addressing the practical challenges teams face when producing ai systems.
Alex Gnibus is a technical evangelist at Tecton, making technical concepts accessible and actionable for engineering teams. Through his work training professionals, Alex has developed deep expertise in identifying and addressing the practical challenges teams face when producing ai systems.
 Arnab Sinha is a Senior Solutions Architect at AWS specializing in designing scalable solutions that drive business outcomes in artificial intelligence, machine learning, big data, digital transformation, and application modernization. With experience in industries such as energy, healthcare, retail, and manufacturing, Arnab holds all AWS certifications, including the machine learning specialty, and has led technology and engineering teams before joining AWS.
Arnab Sinha is a Senior Solutions Architect at AWS specializing in designing scalable solutions that drive business outcomes in artificial intelligence, machine learning, big data, digital transformation, and application modernization. With experience in industries such as energy, healthcare, retail, and manufacturing, Arnab holds all AWS certifications, including the machine learning specialty, and has led technology and engineering teams before joining AWS.






{kind=link}