 NEWSLETTER
NEWSLETTER
Large language models (LLMs) have revolutionized generative ai, displaying remarkable capabilities to produce human-like responses. However, these models face a critical challenge known as hallucination, the tendency to generate incorrect or irrelevant information. This issue poses significant risks in high-risk applications, such as medical evaluations, insurance claims processing, and autonomous decision-making systems, where accuracy is most important. The hallucination problem extends beyond text-based models, to vision and language models (VLM) that process images and text queries. Despite developing robust VLMs such as LLaVA, InstructBLIP, and VILA, these systems struggle to generate accurate responses based on image inputs and user queries.
Existing research has introduced several methods to address hallucinations in language models. For text-based systems, FactScore improved accuracy by breaking down long statements into atomic units for better verification. Lookback Lens developed an attention scoring analysis approach to detect contextual hallucinations, while MARS implemented a weighted system that focuses on crucial components of utterances. Specifically for RAG systems, RAGAS and LlamaIndex emerged as evaluation tools, with RAGAS focusing on response accuracy and relevance using human raters, while LlamaIndex employs GPT-4 for fidelity evaluation. However, no existing work provides hallucination scores specifically for multimodal RAG systems, where contexts include multiple pieces of multimodal data.
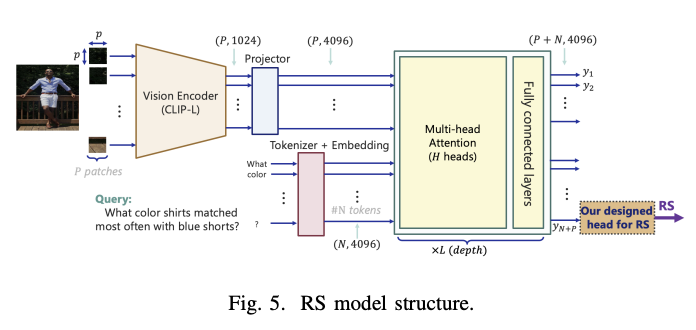
Researchers at the University of Maryland, College Park, MD, and NEC Laboratories America, Princeton, NJ, have proposed RAG-check, a comprehensive method for evaluating multimodal RAG systems. It consists of three key components designed to evaluate both relevance and accuracy. The first component involves a neural network that evaluates the relevance of each retrieved data to the user's query. The second component implements an algorithm that segments and classifies the RAG output into scorable (objective) and non-scorable (subjective) sections. The third component uses another neural network to evaluate the accuracy of target intervals against raw context, which can include both text and images converted to text-based format via VLM.
The RAG-check architecture uses two main evaluation metrics: Relevance Score (RS) and Correctness Score (CS) to evaluate different aspects of RAG system performance. To evaluate the selection mechanisms, the system analyzes the relevance scores of the top five images retrieved in a test set of 1000 questions, providing information on the effectiveness of different retrieval methods. In terms of context generation, the architecture allows flexible integration of various combinations of models, whether separate VLM (such as LLaVA or GPT4) and LLM (such as LLAMA or GPT-3.5), or unified MLLM such as GPT-4. This flexibility allows for a comprehensive evaluation of different model architectures and their impact on response generation quality.
The evaluation results demonstrate significant performance variations between different RAG system configurations. When using CLIP models as vision encoders with cosine similarity for image selection, average relevance scores ranged from 30% to 41%. However, the implementation of the RS model for the evaluation of the query-image pair dramatically improves the relevance scores between 71% and 89.5%, although at the cost of a 35-fold increase in computational requirements when using a A100 GPU. GPT-4o emerges as the top configuration for context generation and error rates, outperforming other configurations by 20%. The remaining RAG configurations show comparable performance, with an accuracy rate between 60% and 68%.
In conclusion, the researchers developed RAG-check, a novel evaluation framework for multimodal RAG systems to address the critical challenge of hallucination detection across multiple images and text inputs. The framework's three-component architecture, comprising relevance scoring, breadth categorization, and correctness evaluation, shows significant improvements in performance evaluation. The results reveal that, although the RS model substantially improves relevance scores from 41% to 89.5%, it entails higher computational costs. Among several configurations tested, GPT-4o emerged as the most effective model for context generation, highlighting the potential of unified multimodal language models to improve the accuracy and reliability of the RAG system.
Verify he Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on <a target="_blank" href="https://x.com/intent/follow?screen_name=marktechpost” target=”_blank” rel=”noreferrer noopener”>twitter and join our Telegram channel and LinkedIn Grabove. Don't forget to join our SubReddit over 65,000 ml.
UPCOMING FREE ai WEBINAR (JANUARY 15, 2025): <a target="_blank" href="https://info.gretel.ai/boost-llm-accuracy-with-sd-and-evaluation-intelligence?utm_source=marktechpost&utm_medium=newsletter&utm_campaign=202501_gretel_galileo_webinar”>Increase LLM Accuracy with Synthetic Data and Assessment Intelligence–<a target="_blank" href="https://info.gretel.ai/boost-llm-accuracy-with-sd-and-evaluation-intelligence?utm_source=marktechpost&utm_medium=newsletter&utm_campaign=202501_gretel_galileo_webinar”>Join this webinar to learn practical information to improve LLM model performance and accuracy while protecting data privacy..

Sajjad Ansari is a final year student of IIT Kharagpur. As a technology enthusiast, he delves into the practical applications of ai with a focus on understanding the impact of ai technologies and their real-world implications. Its goal is to articulate complex ai concepts in a clear and accessible way.






{kind=link}