
Large language models (LLMs) encounter significant difficulties in performing efficient and logically consistent reasoning. Existing methods, such as CoT prompts, are extremely computationally intensive, are not scalable, and are not suitable for real-time or resource-limited applications. These limitations restrict its applicability in financial analysis and decision making, which require speed and accuracy.
Next-generation reasoning approaches, such as CoT, create structured reasoning paths to improve the accuracy of logic. However, they are computationally demanding and are not viable for applications that require responses in a short time or where resources are limited. They also do not scale well to handle multiple complex queries at the same time, which limits their application in production environments, especially in organizations with limited computing resources.
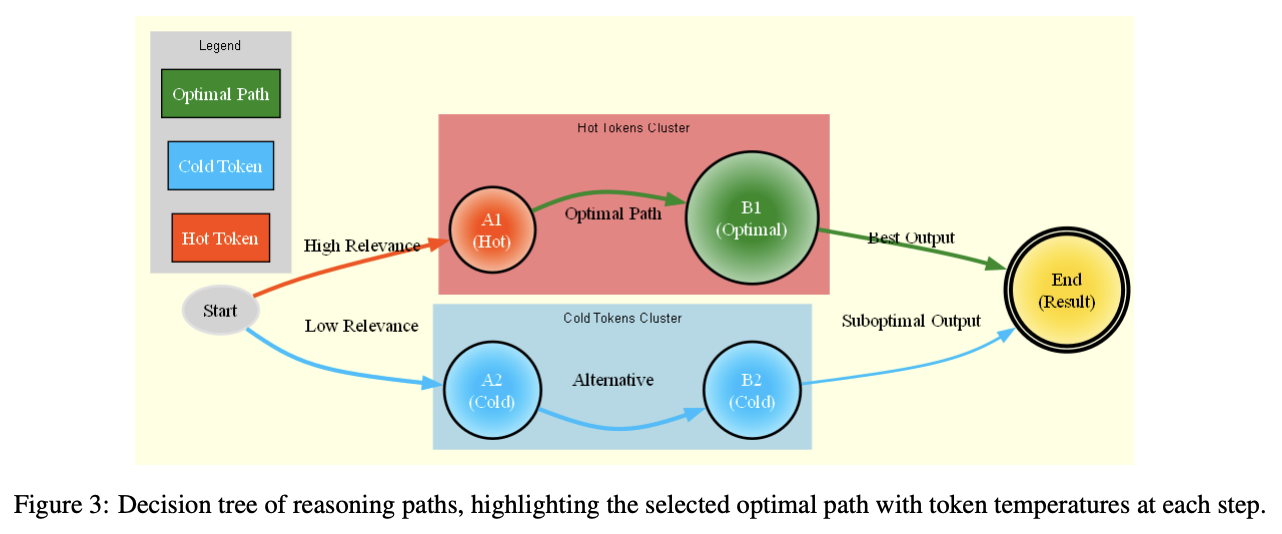
SILX ai researchers introduced Quasar-1, an innovative framework based on temperature-guided reasoning, to address these challenges. The two main components are the Token Temperature Mechanism (TTM), which dynamically changes the importance of tokens during reasoning, and the Guided Sequence of Thought (GSoT), which calculates optimal reasoning paths. This architecture reduces unnecessary computations and maintains logical consistency by using token temperatures to focus on contextually relevant information. The architecture exemplifies considerable advances such as improved scalability, efficiency, and adaptability in practical applications.
The structure is built on a transformer-based design, complemented by temperature-modulated care mechanisms. The TTM calculates specific temperatures of each token to direct reasoning across layers, dynamically modifying token meaning as reasoning evolves. GSoT uses this temperature information to formulate efficient and accurate reasoning pathways. Quasar-1 has 24 layers of transformers with 12 attention heads so that efficiency and effectiveness are optimally balanced. Empirical verifications for a variety of different reasoning tasks ensure that theoretical foundations for convergence toward an optimal solution are provided.
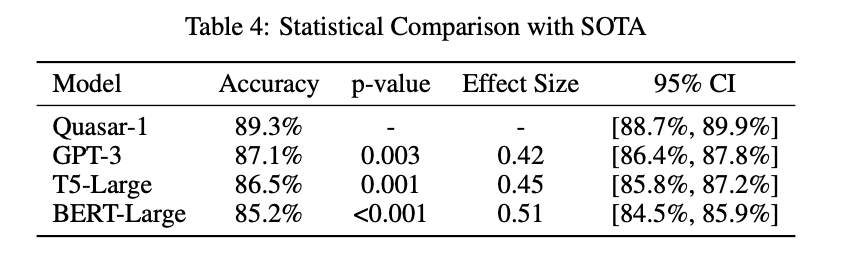
Quasar-1 performs well, achieving an accuracy of 89.3%, outperforming models such as GPT-3 and T5-Large. Reduces computational costs by up to 70% and ensures faster, more resource-efficient reasoning capabilities. The framework dynamically prioritizes critical tokens, enabling adaptive error recovery and logical consistency, making it suitable for complex real-world tasks. These results underline its potential as a practical and scalable solution for environments where both efficiency and precision are vital.
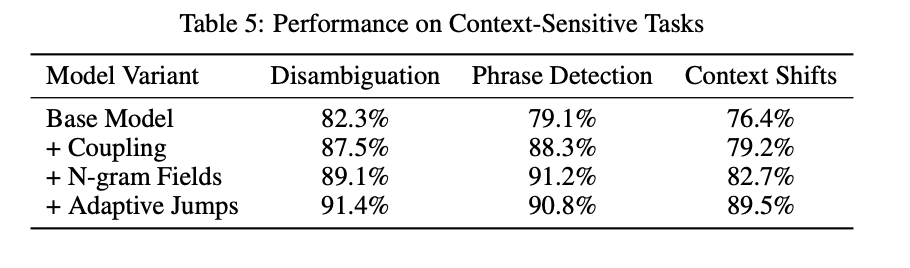
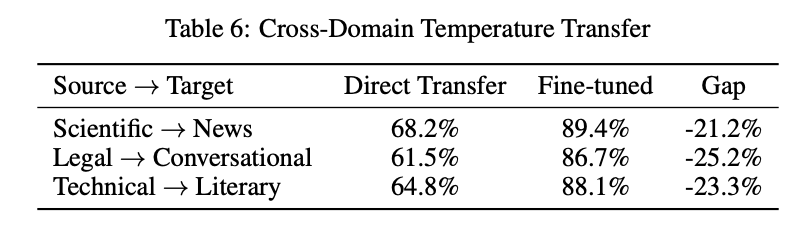
By employing temperature-guided reasoning and optimized decision pathways, Quasar-1 overcomes fundamental flaws in existing models, thereby providing a scalable and practical approach to logical reasoning. Dynamic token prioritization and adaptive error recovery advance the ai domain with practical applications in diverse and resource-constrained environments. This represents an important milestone in the quest for ai systems that are both highly efficient, accurate and flexible.
Verify he Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on <a target="_blank" href="https://twitter.com/Marktechpost”>twitter and join our Telegram channel and LinkedIn Grabove. Don't forget to join our SubReddit over 60,000 ml.
Trending: LG ai Research launches EXAONE 3.5 – three frontier-level bilingual open-source ai models that deliver unmatched instruction following and broad context understanding for global leadership in generative ai excellence….
Aswin AK is a consulting intern at MarkTechPost. He is pursuing his dual degree from the Indian Institute of technology Kharagpur. He is passionate about data science and machine learning, and brings a strong academic background and practical experience solving real-life interdisciplinary challenges.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>





{kind=link}