 NEWSLETTER
NEWSLETTER
¡Los modelos de razonamiento con ai están tomando el mundo por asalto en 2025! Con el lanzamiento de Deepseek-R1 y O3-Mini, hemos visto niveles sin precedentes de capacidades lógicas de razonamiento en chatbots de IA. En este artículo, accederemos a estos modelos a través de sus API y evaluaremos sus habilidades de razonamiento lógico para averiguar si O3-Mini puede reemplazar a Deepseek-R1. ¡Compararemos su rendimiento en puntos de referencia estándar, así como aplicaciones del mundo real como resolver rompecabezas lógicos e incluso construir un juego de Tetris! Así que abrochate y únete al viaje.
Deepseek-r1 vs O3-Mini: puntos de referencia de razonamiento lógico
Deepseek-R1 y O3-Mini ofrecen enfoques únicos para el pensamiento y la deducción estructurados, haciéndolos aptos para varios tipos de tareas complejas de resolución de problemas. Antes de hablar de su actuación de referencia, primero echemos un vistazo a la arquitectura de estos modelos.
O3-Mini es el modelo de razonamiento más avanzado de OpenAI. Utiliza una arquitectura de transformador denso, procesando cada token con todos los parámetros del modelo para un rendimiento fuerte pero un alto consumo de recursos. En contraste, el modelo más lógico de Deepseek, R1, emplea un marco de mezcla de expertos (MOE), activando solo un subconjunto de parámetros por entrada para una mayor eficiencia. Esto hace que Deepseek-R1 sea más escalable y computacionalmente optimizado mientras mantiene un rendimiento sólido.
Aprenda más: ¿Es mejor O3-Mini de OpenAI que Deepseek-R1?
Ahora lo que necesitamos ver es qué tan bien funcionan estos modelos en las tareas de razonamiento lógico. Primero, echemos un vistazo a su actuación en las pruebas de referencia LiveBench.
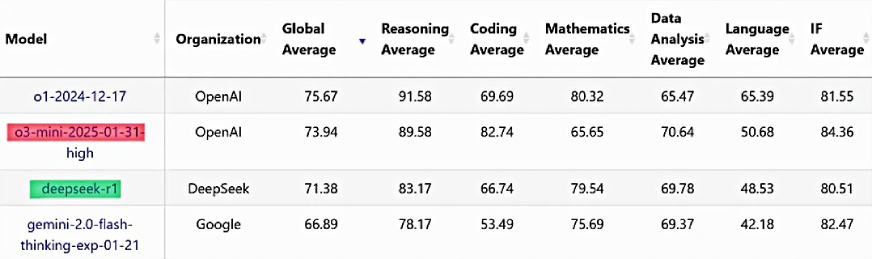
Fuentes: <a target="_blank" href="https://livebench.ai/#/” target=”_blank” rel=”nofollow noopener”>LiveBench.ai
Los resultados de referencia muestran que el O3-Mini de OpenAI supera a Deepseek-R1 en casi todos los aspectos, excepto las matemáticas. Con un puntaje promedio global de 73.94 en comparación con los 71.38 de Deepseek, el O3-Mini demuestra un rendimiento general ligeramente más fuerte. Particularmente sobresale en el razonamiento, logrando 89.58 versus 83.17 de Deepseek, lo que refleja capacidades analíticas y de resolución de problemas superiores.
Lea también: Google Gemini 2.0 Pro vs Deepseek-R1: ¿Quién está mejorando mejor?
Deepseek-r1 vs O3-Mini: comparación de precios de API
Dado que estamos probando estos modelos a través de sus API, veamos cuánto cuestan estos modelos.
| Modelo | Longitud de contexto | Precio de entrada | Precio de entrada en caché | Precio de salida |
| O3-Mini | 200K | Tokens de $ 1.10/m | Tokens de $ 0.55/m | Tokens de $ 4.40/m |
| profundo-chat | 64k | Tokens de $ 0.27/m | Tokens de $ 0.07/m | Tokens de $ 1.10/m |
| Deepseek-Razerer | 64k | Tokens de $ 0.55/m | Tokens de $ 0.14/m | Tokens de $ 2.19/m |
Como se ve en la mesa, el O3-Mini de OpenAI es casi el doble de caro que Deepseek R1 en términos de costos de API. Cobra $ 1.10 por millón de tokens por entrada y $ 4.40 por la producción, mientras que Deepseek R1 ofrece una tasa más rentable de $ 0.55 por millón de tokens por entrada y $ 2.19 para la producción, lo que lo convierte en una opción más económica para aplicaciones a gran escala.
Fuentes: Deepseek-r1 | O3-Mini
Cómo acceder a Deepseek-R1 y O3-Mini a través de API
Antes de entrar en la comparación de rendimiento práctico, aprendamos a acceder a Deepseek-R1 y O3-Mini usando API.
Todo lo que tiene que hacer para esto es importar las bibliotecas y claves API necesarias:
from openai import OpenAI
from IPython.display import display, Markdown
import timewith open("path_of_api_key") as file:
openai_api_key = file.read().strip()with open("path_of_api_key") as file:
deepseek_api = file.read().strip()Deepseek-r1 vs O3-Mini: comparación de razonamiento lógico
Ahora que hemos obtenido el acceso a la API, comparemos Deepseek-R1 y O3-Mini en función de sus capacidades lógicas de razonamiento. Para esto, daremos el mismo aviso tanto a los modelos como a evaluar sus respuestas basadas en estas métricas:
- Tiempo que el modelo tomó la respuesta,
- Calidad de la respuesta generada y
- Costo incurrido para generar la respuesta.
Luego anotaremos los modelos 0 o 1 para cada tarea, dependiendo de su rendimiento. ¡Así que probemos las tareas y veamos quién emerge como el ganador en la batalla de razonamiento Deepseek-R1 vs O3-Mini!
Tarea 1: Construir un juego de Tetris
Esta tarea requiere que el modelo implemente un juego de Tetris completamente funcional usando Python, que administra eficientemente la lógica del juego, el movimiento de las piezas, la detección de colisiones y la representación sin depender de motores de juegos externos.
Inmediato: “Escriba un código de Python para este problema: genere un código de Python para el juego Tetris”
Entrada a la API Deepseek-R1
INPUT_COST_CACHE_HIT = 0.14 / 1_000_000 # $0.14 per 1M tokens
INPUT_COST_CACHE_MISS = 0.55 / 1_000_000 # $0.55 per 1M tokens
OUTPUT_COST = 2.19 / 1_000_000 # $2.19 per 1M tokens
# Start timing
task1_start_time = time.time()
# Initialize OpenAI client for DeepSeek API
client = OpenAI(api_key=api_key, base_url="https://api.deepseek.com")
messages = (
{
"role": "system",
"content": """You are a professional Programmer with a large experience."""
},
{
"role": "user",
"content": """write a python code for this problem: generate a python code for Tetris game."""
}
)
# Get token count using tiktoken (adjust model name if necessary)
encoding = tiktoken.get_encoding("cl100k_base") # Use a compatible tokenizer
input_tokens = sum(len(encoding.encode(msg("content"))) for msg in messages)
# Call DeepSeek API
response = client.chat.completions.create(
model="deepseek-reasoner",
messages=messages,
stream=False
)
# Get output token count
output_tokens = len(encoding.encode(response.choices(0).message.content))
task1_end_time = time.time()
total_time_taken = task1_end_time - task1_start_time
# Assume cache miss for worst-case pricing (adjust if cache info is available)
input_cost = (input_tokens / 1_000_000) * INPUT_COST_CACHE_MISS
output_cost = (output_tokens / 1_000_000) * OUTPUT_COST
total_cost = input_cost + output_cost
# Print results
print("Response:", response.choices(0).message.content)
print("------------------ Total Time Taken for Task 1: ------------------", total_time_taken)
print(f"Input Tokens: {input_tokens}, Output Tokens: {output_tokens}")
print(f"Estimated Cost: ${total_cost:.6f}")
# Display result
from IPython.display import Markdown
display(Markdown(response.choices(0).message.content))Respuesta de Deepseek-R1
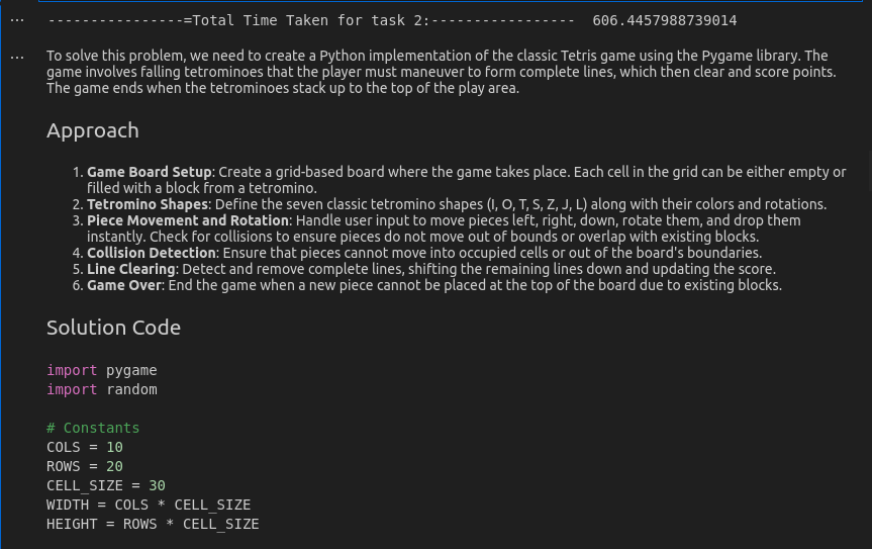
Puedes encontrar la respuesta completa de Deepseek-R1 aquí.
Costo de token de salida:
Tokens de entrada: 28 | Tokens de salida: 3323 | Costo estimado: $ 0.0073
Salida del código
Entrada a la API O3-Mini
task1_start_time = time.time()
client = OpenAI(api_key=api_key)
messages = messages=(
{
"role": "system",
"content": """You are a professional Programmer with a large experience ."""
},
{
"role": "user",
"content": """write a python code for this problem: generate a python code for Tetris game.
"""
}
)
# Use a compatible encoding (cl100k_base is the best option for new OpenAI models)
encoding = tiktoken.get_encoding("cl100k_base")
# Calculate token counts
input_tokens = sum(len(encoding.encode(msg("content"))) for msg in messages)
completion = client.chat.completions.create(
model="o3-mini-2025-01-31",
messages=messages
)
output_tokens = len(encoding.encode(completion.choices(0).message.content))
task1_end_time = time.time()
input_cost_per_1k = 0.0011 # Example: $0.005 per 1,000 input tokens
output_cost_per_1k = 0.0044 # Example: $0.015 per 1,000 output tokens
# Calculate cost
input_cost = (input_tokens / 1000) * input_cost_per_1k
output_cost = (output_tokens / 1000) * output_cost_per_1k
total_cost = input_cost + output_cost
print(completion.choices(0).message)
print("----------------=Total Time Taken for task 1:----------------- ", task1_end_time - task1_start_time)
print(f"Input Tokens: {input_tokens}, Output Tokens: {output_tokens}")
print(f"Estimated Cost: ${total_cost:.6f}")
# Display result
from IPython.display import Markdown
display(Markdown(completion.choices(0).message.content))Respuesta de O3-Mini
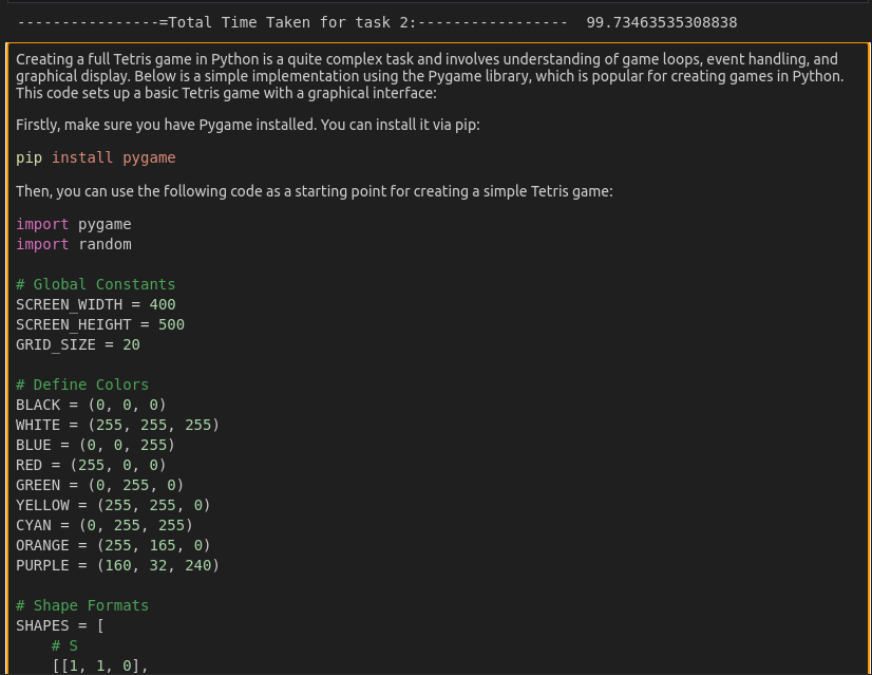
Puedes encontrar la respuesta completa de O3-Mini aquí.
Costo de token de salida:
Tokens de entrada: 28 | Tokens de salida: 3235 | Costo estimado: $ 0.014265
Salida del código
Análisis comparativo
En esta tarea, se requería que los modelos generen un código TETRIS funcional que permita un juego real. Deepseek-R1 produjo con éxito una implementación completamente en funcionamiento, como se demuestra en el video de salida del código. En contraste, mientras que el código de O3-Mini parecía bien estructurado, encontró errores durante la ejecución. Como resultado, Deepseek-R1 supera a O3-Mini en este escenario, ofreciendo una solución más confiable y jugable.
Puntaje: Deepseek-r1: 1 | O3-Mini: 0
Tarea 2: Análisis de desigualdades relacionales
Esta tarea requiere que el modelo analice eficientemente las desigualdades relacionales en lugar de depender de los métodos de clasificación básicos.
Inmediato: ” En la siguiente pregunta, suponiendo que las declaraciones dadas sean verdaderas, encuentre cuál de la conclusión entre las conclusiones dadas es/son definitivamente verdaderas y luego dan sus respuestas en consecuencia.
Declaraciones:
H> f ≤ o ≤ l; F ≥ V <D
Conclusiones: I. L ≥ V II. O> D
Las opciones son:
A. Solo yo es verdad
B. Solo II es verdadero
C. Tanto I como II son ciertos
D. O I o II es cierto
E. ni yo ni II son verdaderos “.
Entrada a la API Deepseek-R1
INPUT_COST_CACHE_HIT = 0.14 / 1_000_000 # $0.14 per 1M tokens
INPUT_COST_CACHE_MISS = 0.55 / 1_000_000 # $0.55 per 1M tokens
OUTPUT_COST = 2.19 / 1_000_000 # $2.19 per 1M tokens
# Start timing
task2_start_time = time.time()
# Initialize OpenAI client for DeepSeek API
client = OpenAI(api_key=api_key, base_url="https://api.deepseek.com")
messages = (
{"role": "system", "content": "You are an expert in solving Reasoning Problems. Please solve the given problem."},
{"role": "user", "content": """ In the following question, assuming the given statements to be true, find which of the conclusions among given conclusions is/are definitely true and then give your answers accordingly.
Statements: H > F ≤ O ≤ L; F ≥ V < D
Conclusions:
I. L ≥ V
II. O > D
The options are:
A. Only I is true
B. Only II is true
C. Both I and II are true
D. Either I or II is true
E. Neither I nor II is true
"""}
)
# Get token count using tiktoken (adjust model name if necessary)
encoding = tiktoken.get_encoding("cl100k_base") # Use a compatible tokenizer
input_tokens = sum(len(encoding.encode(msg("content"))) for msg in messages)
# Call DeepSeek API
response = client.chat.completions.create(
model="deepseek-reasoner",
messages=messages,
stream=False
)
# Get output token count
output_tokens = len(encoding.encode(response.choices(0).message.content))
task2_end_time = time.time()
total_time_taken = task2_end_time - task2_start_time
# Assume cache miss for worst-case pricing (adjust if cache info is available)
input_cost = (input_tokens / 1_000_000) * INPUT_COST_CACHE_MISS
output_cost = (output_tokens / 1_000_000) * OUTPUT_COST
total_cost = input_cost + output_cost
# Print results
print("Response:", response.choices(0).message.content)
print("------------------ Total Time Taken for Task 2: ------------------", total_time_taken)
print(f"Input Tokens: {input_tokens}, Output Tokens: {output_tokens}")
print(f"Estimated Cost: ${total_cost:.6f}")
# Display result
from IPython.display import Markdown
display(Markdown(response.choices(0).message.content))Costo de token de salida:
Tokens de entrada: 136 | Tokens de salida: 352 | Costo estimado: $ 0.000004
Respuesta de Deepseek-R1
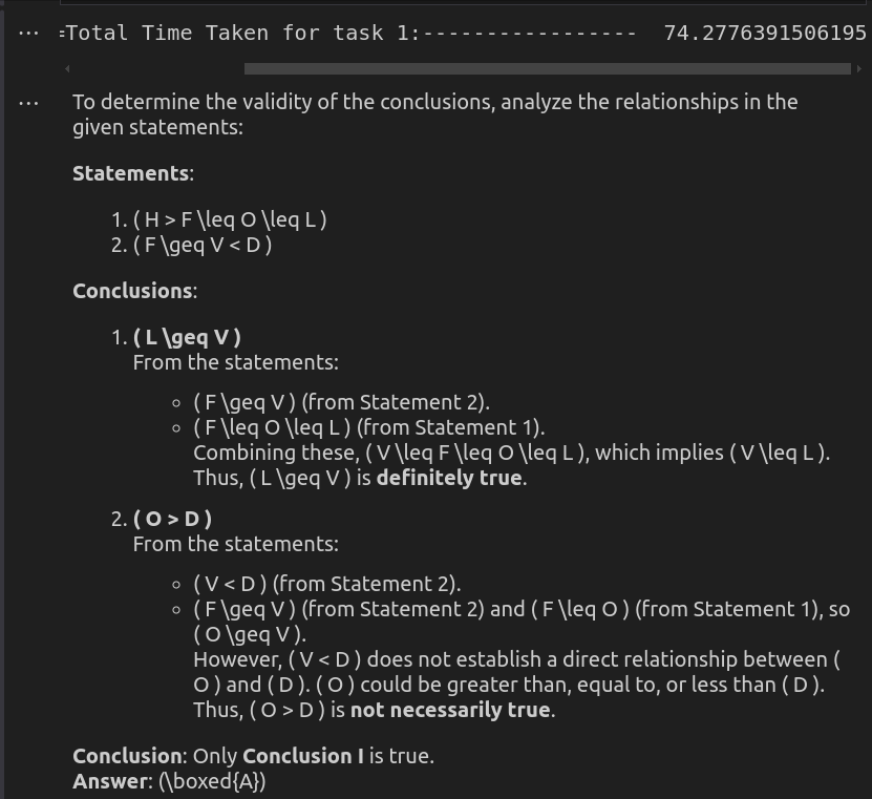
Entrada a la API O3-Mini
task2_start_time = time.time()
client = OpenAI(api_key=api_key)
messages = (
{
"role": "system",
"content": """You are an expert in solving Reasoning Problems. Please solve the given problem"""
},
{
"role": "user",
"content": """In the following question, assuming the given statements to be true, find which of the conclusions among given conclusions is/are definitely true and then give your answers accordingly.
Statements: H > F ≤ O ≤ L; F ≥ V < D
Conclusions:
I. L ≥ V
II. O > D
The options are:
A. Only I is true
B. Only II is true
C. Both I and II are true
D. Either I or II is true
E. Neither I nor II is true
"""
}
)
# Use a compatible encoding (cl100k_base is the best option for new OpenAI models)
encoding = tiktoken.get_encoding("cl100k_base")
# Calculate token counts
input_tokens = sum(len(encoding.encode(msg("content"))) for msg in messages)
completion = client.chat.completions.create(
model="o3-mini-2025-01-31",
messages=messages
)
output_tokens = len(encoding.encode(completion.choices(0).message.content))
task2_end_time = time.time()
input_cost_per_1k = 0.0011 # Example: $0.005 per 1,000 input tokens
output_cost_per_1k = 0.0044 # Example: $0.015 per 1,000 output tokens
# Calculate cost
input_cost = (input_tokens / 1000) * input_cost_per_1k
output_cost = (output_tokens / 1000) * output_cost_per_1k
total_cost = input_cost + output_cost
# Print results
print(completion.choices(0).message)
print("----------------=Total Time Taken for task 2:----------------- ", task2_end_time - task2_start_time)
print(f"Input Tokens: {input_tokens}, Output Tokens: {output_tokens}")
print(f"Estimated Cost: ${total_cost:.6f}")
# Display result
from IPython.display import Markdown
display(Markdown(completion.choices(0).message.content))Costo de token de salida:
Tokens de entrada: 135 | Tokens de salida: 423 | Costo estimado: $ 0.002010
Respuesta de O3-Mini
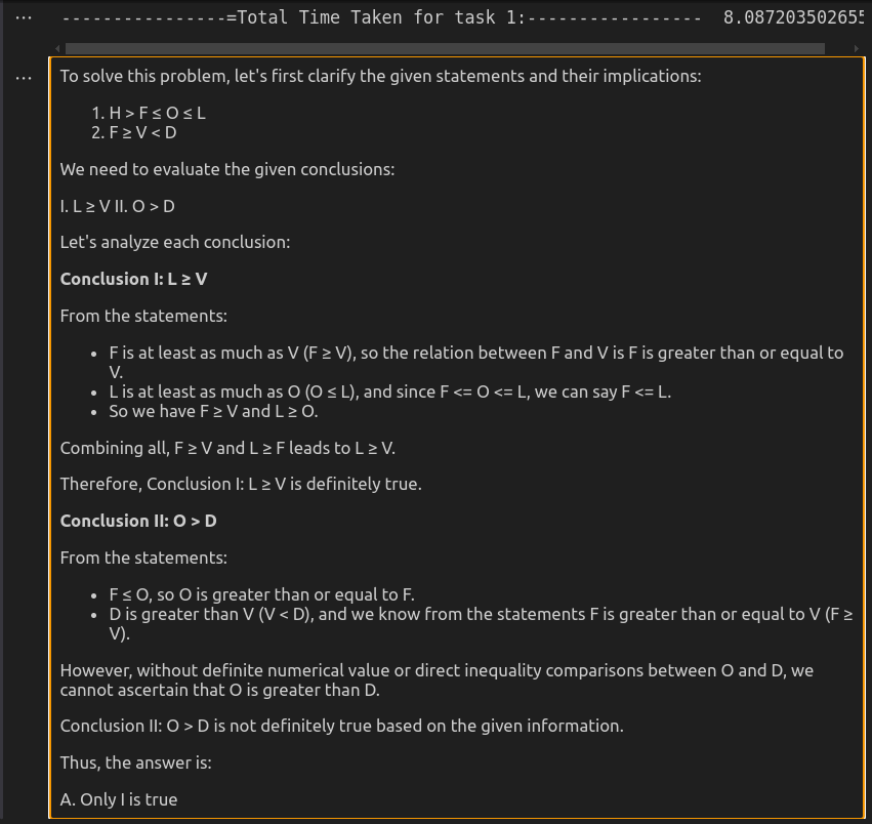
Análisis comparativo
O3-Mini ofrece la solución más eficiente, proporcionando una respuesta concisa pero precisa en un tiempo significativamente menor. Mantiene la claridad al tiempo que garantiza la solidez lógica, lo que la hace ideal para tareas de razonamiento rápido. Deepseek-R1, aunque igualmente correcto, es mucho más lento y más detallado. Su desglose detallado de las relaciones lógicas mejora la explicabilidad, pero puede sentirse excesivo para evaluaciones directas. Aunque ambos modelos llegan a la misma conclusión, la velocidad y el enfoque directo de O3-Mini lo convierten en la mejor opción para el uso práctico.
Puntaje: Deepseek-r1: 0 | O3-Mini: 1
Tarea 3: razonamiento lógico en matemáticas
Esta tarea desafía al modelo a reconocer patrones numéricos, que pueden involucrar operaciones aritméticas, multiplicación o una combinación de reglas matemáticas. En lugar de la búsqueda de fuerza bruta, el modelo debe adoptar un enfoque estructurado para deducir la lógica oculta de manera eficiente.
Inmediato: “Estudie cuidadosamente la matriz dada y seleccione el número entre las opciones dadas que pueden reemplazar el signo de interrogación () en ella.
____________
| 7 | 13 | 174 |
| 9 | 25 | 104 |
| 11 | 30 | ? |
| _____ | ____ | ___ |
Las opciones son:
Un 335
B 129
C 431
D 100
Por favor, mencione su enfoque que ha tomado en cada paso “.
Entrada a la API Deepseek-R1
INPUT_COST_CACHE_HIT = 0.14 / 1_000_000 # $0.14 per 1M tokens
INPUT_COST_CACHE_MISS = 0.55 / 1_000_000 # $0.55 per 1M tokens
OUTPUT_COST = 2.19 / 1_000_000 # $2.19 per 1M tokens
# Start timing
task3_start_time = time.time()
# Initialize OpenAI client for DeepSeek API
client = OpenAI(api_key=api_key, base_url="https://api.deepseek.com")
messages = (
{
"role": "system",
"content": """You are a Expert in solving Reasoning Problems. Please solve the given problem"""
},
{
"role": "user",
"content": """
Study the given matrix carefully and select the number from among the given options that can replace the question mark (?) in it.
__________________
| 7 | 13 | 174|
| 9 | 25 | 104|
| 11 | 30 | ? |
|_____|_____|____|
The options are:
A 335
B 129
C 431
D 100
Please mention your approch that you have taken at each step
"""
}
)
# Get token count using tiktoken (adjust model name if necessary)
encoding = tiktoken.get_encoding("cl100k_base") # Use a compatible tokenizer
input_tokens = sum(len(encoding.encode(msg("content"))) for msg in messages)
# Call DeepSeek API
response = client.chat.completions.create(
model="deepseek-reasoner",
messages=messages,
stream=False
)
# Get output token count
output_tokens = len(encoding.encode(response.choices(0).message.content))
task3_end_time = time.time()
total_time_taken = task3_end_time - task3_start_time
# Assume cache miss for worst-case pricing (adjust if cache info is available)
input_cost = (input_tokens / 1_000_000) * INPUT_COST_CACHE_MISS
output_cost = (output_tokens / 1_000_000) * OUTPUT_COST
total_cost = input_cost + output_cost
# Print results
print("Response:", response.choices(0).message.content)
print("------------------ Total Time Taken for Task 3: ------------------", total_time_taken)
print(f"Input Tokens: {input_tokens}, Output Tokens: {output_tokens}")
print(f"Estimated Cost: ${total_cost:.6f}")
# Display result
from IPython.display import Markdown
display(Markdown(response.choices(0).message.content))Costo de token de salida:
Tokens de entrada: 134 | Tokens de salida: 274 | Costo estimado: $ 0.000003
Respuesta de Deepseek-R1

Entrada a la API O3-Mini
task3_start_time = time.time()
client = OpenAI(api_key=api_key)
messages = (
{
"role": "system",
"content": """You are a Expert in solving Reasoning Problems. Please solve the given problem"""
},
{
"role": "user",
"content": """
Study the given matrix carefully and select the number from among the given options that can replace the question mark (?) in it.
__________________
| 7 | 13 | 174|
| 9 | 25 | 104|
| 11 | 30 | ? |
|_____|_____|____|
The options are:
A 335
B 129
C 431
D 100
Please mention your approch that you have taken at each step
"""
}
)
# Use a compatible encoding (cl100k_base is the best option for new OpenAI models)
encoding = tiktoken.get_encoding("cl100k_base")
# Calculate token counts
input_tokens = sum(len(encoding.encode(msg("content"))) for msg in messages)
completion = client.chat.completions.create(
model="o3-mini-2025-01-31",
messages=messages
)
output_tokens = len(encoding.encode(completion.choices(0).message.content))
task3_end_time = time.time()
input_cost_per_1k = 0.0011 # Example: $0.005 per 1,000 input tokens
output_cost_per_1k = 0.0044 # Example: $0.015 per 1,000 output tokens
# Calculate cost
input_cost = (input_tokens / 1000) * input_cost_per_1k
output_cost = (output_tokens / 1000) * output_cost_per_1k
total_cost = input_cost + output_cost
# Print results
print(completion.choices(0).message)
print("----------------=Total Time Taken for task 3:----------------- ", task3_end_time - task3_start_time)
print(f"Input Tokens: {input_tokens}, Output Tokens: {output_tokens}")
print(f"Estimated Cost: ${total_cost:.6f}")
# Display result
from IPython.display import Markdown
display(Markdown(completion.choices(0).message.content))Costo de token de salida:
Tokens de entrada: 134 | Tokens de salida: 736 | Costo estimado: $ 0.003386
Salida de O3-Mini




Análisis comparativo
Aquí, el patrón seguido en cada fila es:
(Primer número)^3− (2º número)^2 = 3er número
Aplicando este patrón:
- Fila 1: 7^3 – 13^2 = 343 – 169 = 174
- Fila 2: 9^3 – 25^2 = 729 – 625 = 104
- Fila 3: 11^3 – 30^2 = 1331 – 900 = 431
Por lo tanto, la respuesta correcta es 431.
Deepseek-R1 identifica y aplica correctamente este patrón, lo que lleva a la respuesta correcta. Su enfoque estructurado garantiza la precisión, aunque lleva significativamente más tiempo calcular el resultado. O3-Mini, por otro lado, no puede establecer un patrón consistente. Intenta múltiples operaciones, como la multiplicación, la adición y la exponenciación, pero no llega a una respuesta definitiva. Esto da como resultado una respuesta poco clara e incorrecta. En general, Deepseek-R1 supera a O3-Mini en un razonamiento y precisión lógicos, mientras que O3-Mini lucha debido a su enfoque inconsistente e ineficaz.
Puntaje: Deepseek-r1: 1 | O3-Mini: 0
Puntuación final: Deepseek-R1: 2 | O3-Mini: 1
Resumen de comparación de razonamiento lógico
| Tarea No. | Tipo de tarea | Modelo | Actuación | Tiempo tomado (segundos) | Costo |
| 1 | Generación de código | Deepseek-r1 | Código de trabajo | 606.45 | $ 0.0073 |
| O3-Mini | Código no laboral | 99.73 | $ 0.014265 | ||
| 2 | Razonamiento alfabético | Deepseek-r1 | Correcto | 74.28 | $ 0.000004 |
| O3-Mini | Correcto | 8.08 | $ 0.002010 | ||
| 3 | Razonamiento matemático | Deepseek-r1 | Correcto | 450.53 | $ 0.000003 |
| O3-Mini | Respuesta incorrecta | 12.37 | $ 0.003386 |
Conclusión
Como hemos visto en esta comparación, tanto Deepseek-R1 como O3-Mini demuestran fortalezas únicas que satisfacen diferentes necesidades. Deepseek-R1 sobresale en tareas basadas en la precisión, particularmente en razonamiento matemático y generación de código complejo, lo que lo convierte en un candidato fuerte para las aplicaciones que requieren profundidad lógica y corrección. Sin embargo, un inconveniente significativo son sus tiempos de respuesta más lentos, en parte debido a los problemas continuos de mantenimiento del servidor que han afectado su accesibilidad. Por otro lado, O3-Mini ofrece tiempos de respuesta significativamente más rápidos, pero su tendencia a producir resultados incorrectos limita su confiabilidad para las tareas de razonamiento de alto riesgo.
Este análisis subraya las compensaciones entre la velocidad y la precisión en los modelos de idiomas. Si bien O3-Mini puede ser útil para aplicaciones rápidas y de bajo riesgo, Deepseek-R1 se destaca como la opción superior para tareas de razonamiento, siempre que se aborden sus problemas de latencia. A medida que los modelos de IA continúan evolucionando, lograr un equilibrio entre la eficiencia del rendimiento y la corrección será clave para optimizar los flujos de trabajo impulsados por la IA en varios dominios.
Lea también: ¿Puede el O3-Mini de Openi vencer a Claude Sonnet 3.5 en la codificación?
Preguntas frecuentes
A. Deepseek-R1 sobresale en razonamiento matemático y generación de código complejo, lo que lo hace ideal para aplicaciones que requieren profundidad y precisión lógicas. O3-Mini, por otro lado, es significativamente más rápido pero a menudo sacrifica la precisión, lo que lleva a resultados ocasionales incorrectos.
A. Deepseek-R1 es la mejor opción para la codificación y las tareas intensivas en el razonamiento debido a su precisión superior y su capacidad para manejar la lógica compleja. Si bien O3-Mini proporciona respuestas más rápidas, puede generar errores, lo que lo hace menos confiable para las tareas de programación de alto riesgo.
A. O3-Mini es el más adecuado para aplicaciones de bajo riesgo y dependientes de la velocidad, como chatbots, generación de texto casual y experiencias interactivas de IA. Sin embargo, para las tareas que requieren alta precisión, Deepseek-R1 es la opción preferida.
A. Deepseek-R1 tiene un razonamiento lógico superior y capacidades de resolución de problemas, lo que lo convierte en una fuerte opción para cálculos matemáticos, asistencia de programación y consultas científicas. O3-Mini proporciona respuestas rápidas pero a veces inconsistentes en escenarios complejos de resolución de problemas.

¡Hola! Soy Vipin, un apasionado entusiasta de la ciencia de datos y el aprendizaje automático con una base sólida en análisis de datos, algoritmos de aprendizaje automático y programación. Tengo experiencia práctica en la creación de modelos, gestionar datos desordenados y resolver problemas del mundo real. Mi objetivo es aplicar información basada en datos para crear soluciones prácticas que generen resultados. Estoy ansioso por contribuir con mis habilidades en un entorno colaborativo mientras continúo aprendiendo y creciendo en los campos de la ciencia de datos, el aprendizaje automático y la PNL.





