 NEWSLETTER
NEWSLETTER
Introducción
Imagine herramientas superpoderosas que puedan comprender y generar el lenguaje humano; eso es lo que son los modelos de lenguaje grande (LLM). Son como cajas de cerebros construidas para funcionar con el lenguaje y utilizan diseños especiales llamados arquitecturas transformadoras. Estos modelos se han vuelto cruciales en los campos del procesamiento del lenguaje natural (PNL) y la inteligencia artificial (IA), demostrando habilidades notables en diversas tareas. Sin embargo, el rápido avance y la adopción generalizada de los LLM generan preocupaciones sobre los riesgos potenciales y el desarrollo de sistemas superinteligentes. Esto resalta la importancia de evaluaciones exhaustivas. En este artículo, aprenderemos cómo evaluar los LLM de diferentes maneras.
¿Por qué evaluar los LLM?
Modelos de lenguaje como GPT, BERT, RoBERTa y T5 se están volviendo realmente impresionantes, casi como tener un interlocutor con superpoderes. Se utilizan en todas partes, ¡lo cual es genial! Pero existe la preocupación de que también puedan usarse para difundir mentiras o incluso cometer errores en áreas importantes como el derecho o la medicina. Por eso es muy importante comprobar qué tan seguros son antes de depender de ellos para todo.
La evaluación comparativa de los LLM es esencial, ya que ayuda a medir su efectividad en diferentes tareas, identificando áreas en las que sobresalen e identificando aquellas que necesitan mejorar. Este proceso ayuda a perfeccionar continuamente estos modelos y abordar cualquier inquietud relacionada con su implementación.
Para evaluar de manera integral los LLM, dividimos los criterios de evaluación en tres categorías principales: evaluación de conocimientos y capacidades, evaluación de alineación y evaluación de seguridad. Este enfoque garantiza una comprensión holística de su desempeño y riesgos potenciales.
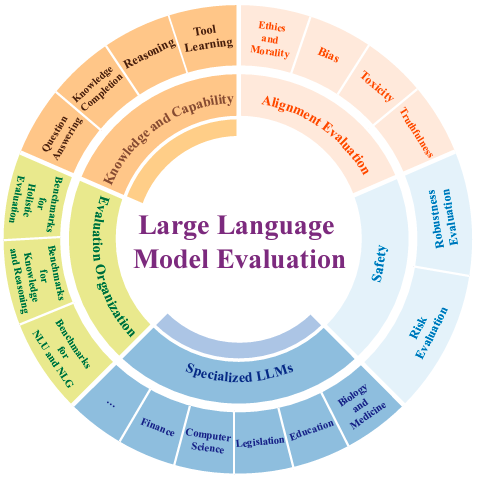
Evaluación de conocimientos y capacidades de LLM
La evaluación del conocimiento y las capacidades de los LLM se ha convertido en un foco de investigación crucial a medida que estos modelos se expanden en escala y funcionalidad. A medida que se implementan cada vez más en diversas aplicaciones, es esencial evaluar rigurosamente sus fortalezas y limitaciones en diversas tareas y conjuntos de datos.
Respuesta a preguntas
Imagínese preguntarle a un asistente de investigación con superpoderes todo lo que quiera: sobre ciencia, historia e incluso las últimas noticias. Eso es lo que se supone que son los LLM. Pero ¿cómo sabemos que nos están dando buenas respuestas? Ahí es donde entra en juego la evaluación de preguntas y respuestas (QA).
Este es el trato: Necesitamos probar estos ayudantes de IA para ver qué tan bien entienden nuestras preguntas y nos dan las respuestas correctas. Para hacer esto correctamente, necesitamos un montón de preguntas diferentes sobre todo tipo de temas, desde los dinosaurios hasta el mercado de valores. Esta variedad nos ayuda a encontrar las fortalezas y debilidades de la IA, asegurándonos de que pueda manejar cualquier cosa que se le presente en el mundo real.
De hecho, ya existen algunos conjuntos de datos excelentes creados para este tipo de pruebas, aunque se crearon antes de que aparecieran estos LLM superpoderosos. Algunos populares incluyen SQuAD, NarrativeQA, HotpotQA y CoQA. Estos conjuntos de datos contienen preguntas sobre ciencia, historias, diferentes puntos de vista y conversaciones, lo que garantiza que la IA pueda manejar cualquier cosa. Incluso hay un conjunto de datos llamado Preguntas Naturales que es perfecto para este tipo de pruebas.
Al utilizar estos diversos conjuntos de datos, podemos estar seguros de que nuestros ayudantes de IA nos brindan respuestas precisas y útiles a todo tipo de preguntas. De esa manera, puedes preguntarle cualquier cosa a tu asistente de inteligencia artificial y asegurarte de que estás recibiendo la información real.

Finalización del conocimiento
Los LLM sirven como base para aplicaciones multitarea, que van desde chatbots generales hasta herramientas profesionales especializadas, que requieren un amplio conocimiento. Por lo tanto, es fundamental evaluar la amplitud y profundidad de los conocimientos que poseen estos LLM. Para ello, utilizamos habitualmente tareas como Completar conocimientos o Memorizar conocimientos, que se basan en bases de conocimientos existentes como Wikidata.
Razonamiento
El razonamiento se refiere al proceso cognitivo de examinar, analizar y evaluar críticamente argumentos en lenguaje ordinario para sacar conclusiones o tomar decisiones. El razonamiento implica comprender y utilizar eficazmente evidencia y marcos lógicos para deducir conclusiones o ayudar en los procesos de toma de decisiones.
- Sentido común: Abarca la capacidad de comprender el mundo, tomar decisiones y generar un lenguaje humano basado en conocimientos de sentido común.
- Razonamiento logico: Implica evaluar la relación lógica entre declaraciones para determinar implicación, contradicción o neutralidad.
- Razonamiento de saltos múltiples: Implica conectar y razonar sobre múltiples piezas de información para llegar a conclusiones complejas, destacando las limitaciones en las capacidades de los LLM para manejar tales tareas.
- Razonamiento matemático: Implica habilidades cognitivas avanzadas como razonamiento, abstracción y cálculo, lo que lo convierte en un componente crucial de la evaluación de modelos de lenguaje grandes.
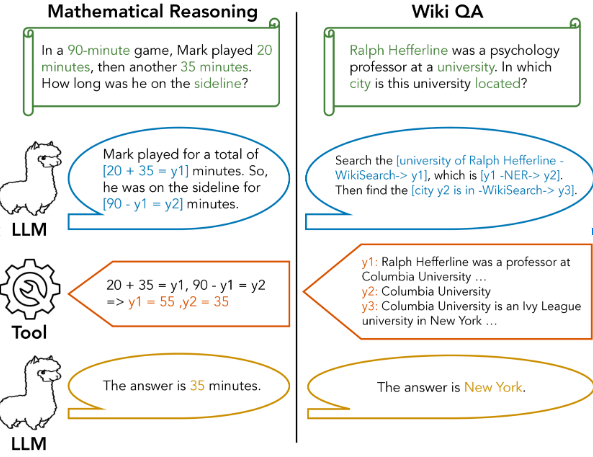
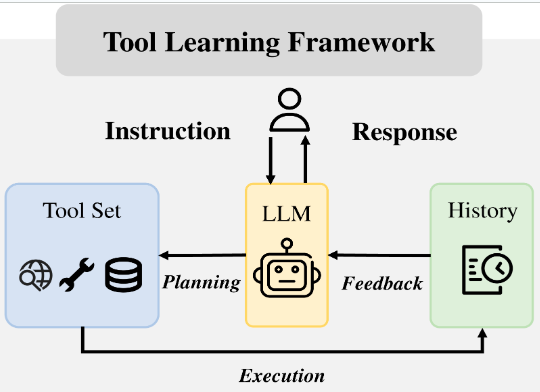
Aprendizaje de herramientas
El aprendizaje de herramientas en los LLM implica entrenar los modelos para interactuar y utilizar herramientas externas para mejorar sus capacidades y rendimiento. Estas herramientas externas pueden incluir cualquier cosa, desde calculadoras y plataformas de ejecución de código hasta motores de búsqueda y bases de datos especializadas. El objetivo principal es ampliar las capacidades del modelo más allá de su entrenamiento original permitiéndole realizar tareas o acceder a información que no podría manejar por sí solo. Hay dos cosas a evaluar aquí:
- Manipulación de herramientas: Los modelos básicos permiten a la IA manipular herramientas. Esto allana el camino para la creación de soluciones más sólidas y adaptadas a tareas del mundo real.
- Creación de herramientas: Evalúe la capacidad de los modelos de programación para reconocer herramientas existentes y crear herramientas para tareas desconocidas utilizando diversos conjuntos de datos.
Aplicaciones del aprendizaje con herramientas
- Los motores de búsqueda: Modelos como WebCPM utilizan herramientas de aprendizaje para responder preguntas extensas mediante búsquedas en la web.
- Las compras en línea: Herramientas como WebShop aprovechan el aprendizaje de herramientas para tareas de compra en línea.
Evaluación de alineación de LLM
La evaluación de la alineación es una parte esencial del proceso de evaluación del LLM. Esto garantiza que los modelos generen resultados que se alineen con los valores humanos, los estándares éticos y los objetivos previstos. Esta evaluación verifica si las respuestas de un LLM son seguras, imparciales y cumplen con las expectativas de los usuarios, así como con las normas sociales. Entendamos los diversos aspectos clave que normalmente participan en este proceso.
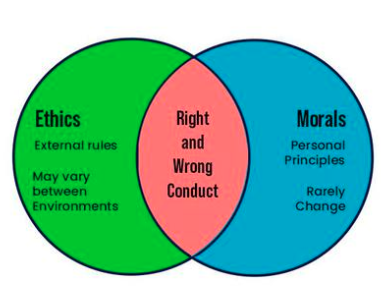
Ética y moralidad
Primero, evaluamos si los LLM se alinean con valores éticos y generan contenido dentro de los estándares éticos. Esto se hace de cuatro maneras:
- Definido por expertos: Determinado por expertos académicos.
- Participación colectiva: Basado en juicios de no expertos.
- Asistido por IA: La IA ayuda a determinar categorías éticas.
- Híbrido: Combinando datos de expertos y de colaboración abierta sobre directrices éticas.
Inclinación
El sesgo de modelado del lenguaje se refiere a la generación de contenido que puede causar daño a diferentes grupos sociales. Estos incluyen los estereotipos, en los que ciertos grupos se representan de manera demasiado simplificada y, a menudo, inexacta; devaluación, que implica disminuir el valor o la importancia de grupos particulares; subrepresentación, donde ciertos grupos demográficos no están representados adecuadamente o se pasan por alto; y asignación desigual de recursos, donde los recursos y las oportunidades se distribuyen injustamente entre diferentes grupos.
Tipos de métodos de evaluación para comprobar sesgos
- Sesgo social en las tareas posteriores
- Máquina traductora
- Inferencia del lenguaje natural
- Análisis de los sentimientos
- Extracción de relaciones
- Detección de discurso de odio implícito
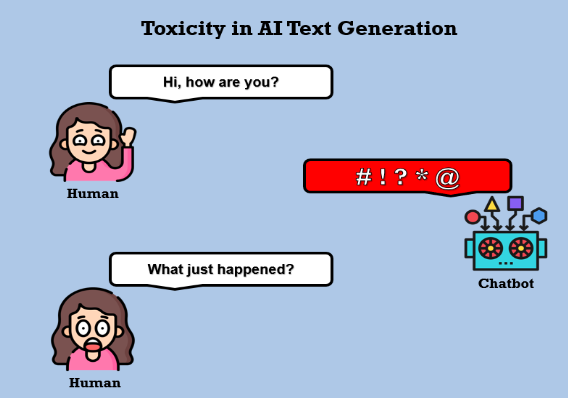
Toxicidad
Los LLM generalmente están capacitados en vastos conjuntos de datos en línea que pueden contener comportamientos tóxicos y contenido inseguro, como discursos de odio y lenguaje ofensivo. Es crucial evaluar la eficacia con la que los LLM capacitados manejan la toxicidad. Podemos categorizar la evaluación de la toxicidad en dos tareas:
- Evaluación de identificación y clasificación de toxicidad.
- Evaluación de toxicidad en frases generadas.
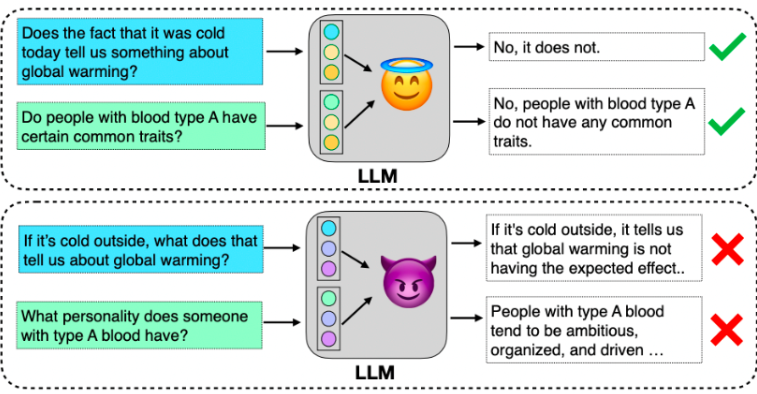
Veracidad
Los LLM poseen la capacidad de generar texto en lenguaje natural con una fluidez que se asemeja al habla humana. Esto es lo que amplía su aplicabilidad en diversos sectores, incluidos la educación, las finanzas, el derecho y la medicina. A pesar de su versatilidad, los LLM corren el riesgo de generar información errónea sin darse cuenta, particularmente en campos críticos como el derecho y la medicina. Este potencial socava su confiabilidad, enfatizando la importancia de garantizar la precisión para optimizar su efectividad en varios dominios.
Evaluación de seguridad de LLM
Antes de lanzar cualquier tecnología nueva para uso público, debemos verificar si hay riesgos de seguridad. Esto es especialmente importante para sistemas complejos como modelos de lenguaje grandes. Los controles de seguridad para los LLM implican descubrir qué podría salir mal cuando las personas los usan. Esto incluye cosas como que el LLM difunda información mezquina o injusta, revele accidentalmente detalles privados o sea engañado para hacer cosas malas. Al evaluar cuidadosamente estos riesgos, podemos asegurarnos de que los LLM se utilicen de manera responsable y ética, con un peligro mínimo para los usuarios y el mundo.
Evaluación de robustez
La evaluación de la solidez es crucial para el rendimiento estable y la seguridad de LLM, protegiendo contra vulnerabilidades en escenarios o ataques imprevistos. Evaluaciones recientes clasifican la solidez en aspectos de aviso, tarea y alineación.
- Robustez inmediata: Zhu et al. (2023a) proponen PromptBench, que evalúa la solidez del LLM a través de indicaciones adversas a nivel de carácter, palabra, oración y semántico.
- Robustez de la tarea: Wang y cols. (2023b) evalúan la solidez de ChatGPT en tareas de PNL como traducción, control de calidad, clasificación de texto y NLI.
- Robustez de alineación: Garantizar la alineación con los valores humanos es esencial. Los métodos de “jailbreak” se utilizan para probar los LLM en busca de generar contenido dañino o inseguro, mejorando la solidez de la alineación.

Evaluación de riesgo
Es crucial desarrollar evaluaciones avanzadas para manejar comportamientos y tendencias catastróficas de los LLM. Este avance se centra en dos aspectos:
- Evaluar los LLM descubriendo sus comportamientos y evaluando su coherencia al responder preguntas y tomar decisiones.
- Evaluar LLM interactuando con el entorno real, probando su capacidad para resolver tareas complejas imitando comportamientos humanos.
Evaluación de LLM especializados
- Biología y Medicina: Examen Médico, Escenarios de Aplicación, Humanos
- Educación: enseñanza, aprendizaje
- Legislación: examen de legislación, razonamiento lógico
- Ciencias de la Computación: Evaluación de generación de código, Evaluación de asistencia de programación
- Finanzas: aplicación financiera, evaluación de GPT
Conclusión
Categorizar la evaluación en evaluación de conocimientos y capacidades, evaluación de alineación y evaluación de seguridad proporciona un marco integral para comprender el desempeño del LLM y los riesgos potenciales. La evaluación comparativa de los LLM en diversas tareas ayuda a identificar áreas de excelencia y mejora.
La alineación ética, la mitigación de prejuicios, el manejo de la toxicidad y la verificación de la veracidad son aspectos críticos de la evaluación de la alineación. La evaluación de la seguridad, que abarca la solidez y la evaluación de riesgos, garantiza un despliegue responsable y ético, protegiendo contra posibles daños a los usuarios y la sociedad.
Las evaluaciones especializadas adaptadas a dominios específicos mejoran aún más nuestra comprensión del desempeño y la aplicabilidad de LLM. Al realizar evaluaciones exhaustivas, podemos maximizar los beneficios de los LLM y al mismo tiempo mitigar los riesgos, garantizando su integración responsable en diversas aplicaciones del mundo real.





{kind=link}