 NEWSLETTER
NEWSLETTER
Large language models (LLMs) like ChatGPT-4 and Claude-3 Opus excel at tasks like code generation, data analysis, and reasoning. Their growing influence on decision-making in various areas makes it crucial to align them with human preferences to ensure fair and correct economic decisions. Human preferences vary widely due to cultural background and personal experiences, and LLMs often exhibit biases, favoring dominant views and frequent items. If LLMs do not accurately reflect these various preferences, biased results can lead to unfair and economically harmful outcomes.
Existing methods, particularly reinforcement learning from human feedback (RLHF), suffer from algorithmic biases, leading to preference collapse when minority preferences are ignored. This bias persists even with an Oracle reward model, highlighting the limitations of current approaches in accurately capturing diverse human preferences.
(Featured Article) LLMWare.ai Selected for GitHub 2024 Accelerator: Enabling the Next Wave of Innovation in Enterprise RAG with Small, Specialized Language Models
Researchers have introduced an innovative approach, Preference Matching RLHF, aimed at mitigating algorithmic bias and aligning LLMs with human preferences effectively. At the center of this innovative method is the preference matching regularizer, obtained by solving an ordinary differential equation. This regularizer ensures that the LLM strikes a balance between response diversification and reward maximization, improving the model's ability to accurately capture and reflect human preferences. Preference Matching RLHF provides strong statistical guarantees and effectively eliminates the bias inherent in conventional RLHF approaches. The paper also details a conditional variant designed for natural language generation tasks, improving the model's ability to generate responses that closely align with human preferences.
Experimental validation of Preference Matching RLHF in the OPT-1.3B and Llama-2-7B models yielded convincing results, demonstrating significant improvements in the alignment of LLMs with human preferences. Performance metrics show a 29% to 41% improvement compared to standard RLHF methods, underscoring the approach's ability to capture diverse human preferences and mitigate algorithmic bias. These results highlight the promising potential of Preference Matching RLHF to advance ai research toward more ethical and effective decision-making processes.
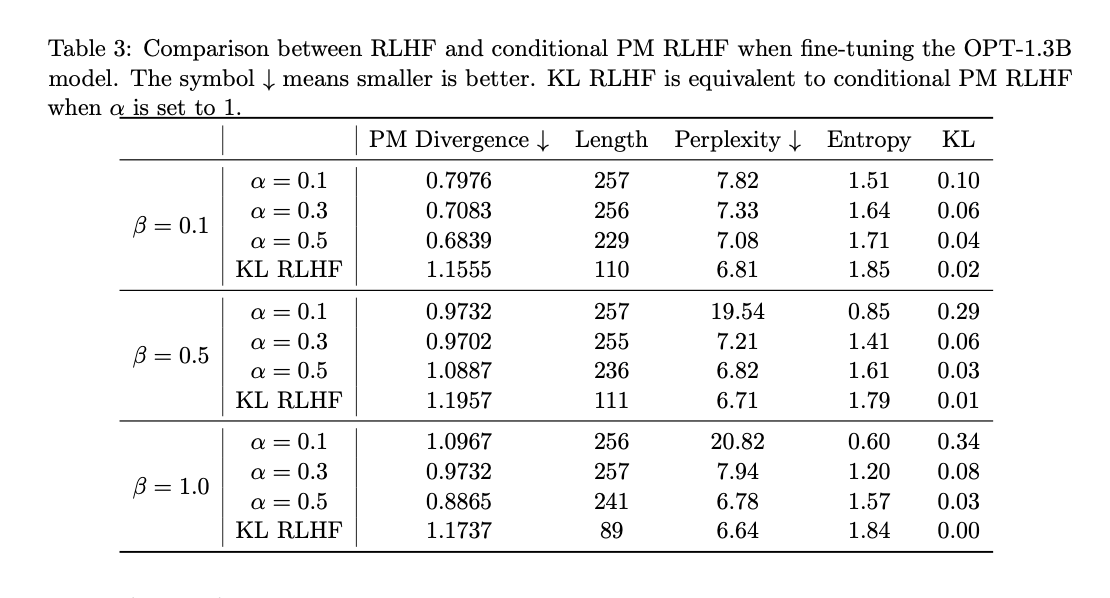
In conclusion, Preference Matching RLHF offers a significant contribution by addressing algorithmic bias and improving the alignment of LLMs with human preferences. This advancement can improve decision-making processes, promote equity, and mitigate biased outcomes of LLMs, advancing the field of ai research.
Review the Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter. Join our Telegram channel, Discord channeland LinkedIn Grabove.
If you like our work, you will love our Newsletter..
Don't forget to join our 43k+ ML SubReddit | Also, check out our ai Event Platform
![]()
Aswin AK is a consulting intern at MarkTechPost. He is pursuing his dual degree from the Indian Institute of technology Kharagpur. She is passionate about data science and machine learning, and brings a strong academic background and practical experience solving real-life interdisciplinary challenges.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>





{kind=link}