 NEWSLETTER
NEWSLETTER
Los trabajos de investigación y los documentos de ingeniería a menudo contienen una gran cantidad de información en forma de fórmulas matemáticas, gráficos y gráficos. Navegar por estos documentos no estructurados para encontrar información relevante puede ser una tarea tediosa y lenta, especialmente cuando se trata de grandes volúmenes de datos. Sin embargo, al usar Claude de Anthrope en amazon Bedrock, los investigadores e ingenieros ahora pueden automatizar la indexación y etiquetado de estos documentos técnicos. Esto permite el procesamiento eficiente del contenido, incluidas las fórmulas científicas y las visualizaciones de datos, y la población de las bases de conocimiento de la roca madre de amazon con metadatos apropiados.
amazon Bedrock es un servicio totalmente administrado que proporciona una API única para acceder y utilizar varios modelos de base de alto rendimiento (FMS) de las principales compañías de inteligencia artificial. Ofrece un amplio conjunto de capacidades para construir aplicaciones de IA generativas con seguridad, privacidad y prácticas responsables de IA. El soneto Claude 3 de Anthrope ofrece las mejores capacidades de visión en su clase en comparación con otros modelos líderes. Puede transcribir con precisión el texto de imágenes imperfectas: una capacidad central para la venta minorista, logística y los servicios financieros, donde la IA podría obtener más información de una imagen, gráfico o ilustración que solo por texto. El último de los modelos Claude de Anthrope demuestra una fuerte aptitud para comprender una amplia gama de formatos visuales, incluidas fotos, gráficos, gráficos y diagramas técnicos. Con el Claude de Anthrope, puede extraer más información de documentos, web UIS y documentación diversa del producto, generar metadatos del catálogo de imágenes y más.
En esta publicación, exploramos cómo puede usar estos modelos ai generativos multimodales para optimizar la gestión de documentos técnicos. Al extraer y estructurar la información clave de los materiales de origen, los modelos pueden crear una base de conocimiento de búsqueda que le permita ubicar rápidamente los datos, fórmulas y visualizaciones que necesita para apoyar su trabajo. Con el contenido del documento organizado en una base de conocimiento, los investigadores e ingenieros pueden utilizar las capacidades de búsqueda avanzadas para producir la información más relevante para sus necesidades específicas. Esto puede acelerar significativamente los flujos de trabajo de investigación y desarrollo, porque los profesionales ya no tienen que examinar manualmente grandes volúmenes de datos no estructurados para encontrar las referencias que necesitan.
Descripción general de la solución
Esta solución demuestra el potencial transformador de la IA generativa multimodal cuando se aplica a los desafíos que enfrentan las comunidades científicas y de ingeniería. Al automatizar la indexación y el etiquetado de documentos técnicos, estos modelos poderosos pueden permitir una gestión de conocimiento más eficiente y acelerar la innovación en una variedad de industrias.
Además de Claude de Anthrope en amazon Bedrock, la solución utiliza los siguientes servicios:
- amazon Sagemaker Jupyterlab -La aplicación SageMakerJupyterLab es un entorno de desarrollo interactivo basado en la web (IDE) para cuadernos, código y datos. La interfaz flexible y extensa de JupyterLab Application se puede utilizar para configurar y organizar flujos de trabajo de aprendizaje automático (ML). Usamos JupyterLab para ejecutar el código para procesar fórmulas y gráficos.
- amazon Simple Storage Service (amazon S3) – amazon S3 es un servicio de almacenamiento de objetos construido para almacenar y proteger cualquier cantidad de datos. Utilizamos amazon S3 para almacenar documentos de muestra que se utilizan en esta solución.
- AWS Lambda –AWS Lambda es un servicio de cómputo que ejecuta código en respuesta a desencadenantes, como cambios en los datos, cambios en el estado de la aplicación o las acciones del usuario. Debido a que servicios como amazon S3 y amazon Simple Notification Service (amazon SNS) pueden activar directamente una función Lambda, puede construir una variedad de sistemas de procesamiento de datos sin servidor en tiempo real.
El flujo de trabajo de la solución contiene los siguientes pasos:
- Divida el PDF en páginas individuales y guárdelas como archivos PNG.
- Con cada página:
- Extraiga el texto original.
- Renderiza las fórmulas en látex.
- Genere una descripción semántica de cada fórmula.
- Genere una explicación de cada fórmula.
- Genere una descripción semántica de cada gráfico.
- Genere una interpretación para cada gráfico.
- Genere metadatos para la página.
- Genere metadatos para el documento completo.
- Cargue el contenido y los metadatos a amazon S3.
- Crea una base de conocimiento de amazon Bedrock.
El siguiente diagrama ilustra este flujo de trabajo.
Requisitos previos
- Si eres nuevo en AWS, primero debes crear y configurar una cuenta de AWS.
- Además, en su cuenta bajo amazon Bedrock, solicite acceso a
anthropic.claude-3-5-sonnet-20241022-v2:0Si aún no lo tienes.
Implementar la solución
Complete los siguientes pasos para configurar la solución:
- Iniciar la plantilla de AWS CloudFormation eligiendo Pila de lanzamiento (Esto crea la pila en el
us-east-1Región de AWS):

- Cuando se complete la implementación de la pila, abra el amazon Sagemaker ai
- Elegir Cuadernos En el panel de navegación.
- Localizar el cuaderno
claude-scientific-docs-notebooky elegir Abrir jupyterlab.

- En el cuaderno, navegue a
notebooks/process_scientific_docs.ipynb.
- Elegir conda_python3 Como el núcleo, luego elige Seleccionar.
- Camine a través del código de muestra.
Explicación del código del cuaderno
En esta sección, atravesamos el código del cuaderno.
Cargar datos
Utilizamos documentos de investigación de ejemplo de arxiv Para demostrar la capacidad descrita aquí. ARXIV es un servicio de distribución gratuito y un archivo de acceso abierto para casi 2,4 millones de artículos académicos en los campos de física, matemáticas, informática, biología cuantitativa, finanzas cuantitativas, estadísticas, ingeniería eléctrica y ciencia de sistemas, y economía.
Descargamos los documentos y los almacenamos en una carpeta de muestras localmente. Los modelos de IA generativos multimodales funcionan bien con la extracción de texto de los archivos de imagen, por lo que comenzamos convirtiendo el PDF en una colección de imágenes, una para cada página.
Obtenga metadatos de fórmulas
Después de que los documentos de la imagen estén disponibles, puede usar el Claude de Anthrope para extraer fórmulas y metadatos con la API Converse Bedrock de amazon. Además, puede usar la API Converse Bedrock amazon para obtener una explicación de las fórmulas extraídas en lenguaje sencillo. Al combinar la fórmula y las capacidades de extracción de metadatos de Claude de Anthrope con las habilidades de conversación de la API Converse Bedrock amazon, puede crear una solución integral para procesar y comprender la información contenida en los documentos de imagen.
Comenzamos con el siguiente ejemplo de archivo PNG.

Usamos el siguiente mensaje de solicitud:
Obtenemos la siguiente respuesta, que muestra la fórmula extraída convertida en formato de látex y descrita en lenguaje sencillo, encerrada en signos de doble dólar.

Obtenga metadatos de los gráficos
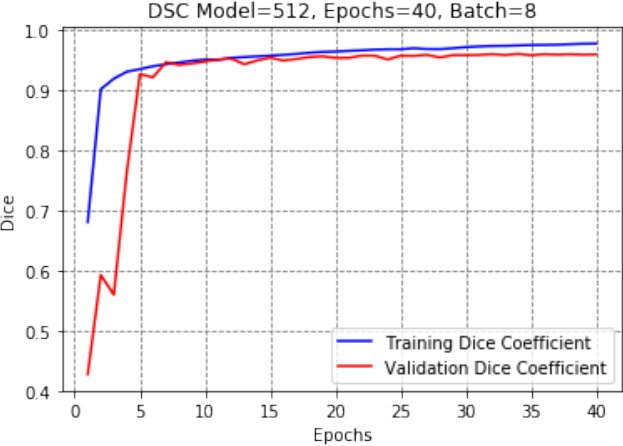
Otra capacidad útil de los modelos de IA generativos multimodales es la capacidad de interpretar gráficos y generar resúmenes y metadatos. El siguiente es un ejemplo de cómo puede obtener metadatos de los gráficos y gráficos utilizando una conversación de lenguaje natural simple con modelos. Usamos el siguiente gráfico.
Proporcionamos la siguiente solicitud:
La respuesta devuelta proporciona su interpretación del gráfico que explica las líneas codificadas por colores y sugiere que, en general, el modelo DSC está funcionando bien en los datos de entrenamiento, logrando un coeficiente de dados alto de alrededor de 0.98. Sin embargo, el coeficiente de dados de validación más bajo y fluctuante indica un potencial de sobreajuste y espacio para mejorar el rendimiento de generalización del modelo.

Generar metadatos
Usando el procesamiento del lenguaje natural, puede generar metadatos para que el documento ayude en la capacidad de búsqueda.
Usamos la siguiente solicitud:
Obtenemos la siguiente respuesta, incluida la Markdown de fórmula y una descripción.
Use sus datos extraídos en una base de conocimiento
Ahora que hemos preparado nuestros datos con fórmulas, gráficos analizados y metadatos, crearemos una base de conocimiento de amazon Bedrock. Esto hará que la información se pueda buscar y habilitará las capacidades de preguntas sobre preguntas.
Prepare su base de conocimiento de amazon Bedrock
Para crear una base de conocimiento, primero cargue los archivos y metadatos procesados a amazon S3:
Cuando sus archivos hayan terminado de cargar, complete los siguientes pasos:
- Crea una base de conocimiento de amazon Bedrock.
- Cree una fuente de datos de amazon S3 para su base de conocimiento y especifique la fragmentación jerárquica como la estrategia de fragmentación.
La fragmentación jerárquica implica organizar la información en estructuras anidadas de fragmentos de niños y padres.
La estructura jerárquica permite una recuperación más rápida y específica de la información relevante, primero realizando una búsqueda semántica en la fragmentación del niño y luego devolver la fragmentación de los padres durante la recuperación. Al reemplazar los trozos de los niños con la fragmentación de los padres, proporcionamos un contexto grande e integral a la FM.
La fragmentación jerárquica es la más adecuada para documentos complejos que tienen una estructura anidada o jerárquica, como manuales técnicos, documentos legales o documentos académicos con complejos formatear y tablas anidadas.
Consulta la base de conocimiento
Puede consultar la base de conocimiento para recuperar información de la fórmula extraída y los metadatos gráficos de los documentos de muestra. Con una consulta, se recuperan fragmentos relevantes de texto de la fuente de datos y se genera una respuesta para la consulta, basada en los fragmentos de fuente recuperados. La respuesta también cita fuentes que son relevantes para la consulta.
Utilizamos la función de plantilla de solicitud personalizada de las bases de conocimiento para formatear la salida como markdown:
Obtenemos la siguiente respuesta, que proporciona información sobre cuándo se usa la pérdida focal de Tversky.

Limpiar
Para limpiar y evitar incurrir en cargos, ejecute los pasos de limpieza en el cuaderno para eliminar los archivos que cargó a amazon S3 junto con la base de conocimiento. Luego, en la consola de CloudFormation de AWS, localice la pila claude-scientific-doc y eliminarlo.
Conclusión
Extraer ideas de documentos científicos complejos puede ser una tarea desalentadora. Sin embargo, el advenimiento de la IA generativa multimodal ha revolucionado este dominio. Al aprovechar la comprensión del lenguaje natural avanzado y las capacidades de percepción visual de Claude de Anthrope, ahora puede extraer con precisión fórmulas y datos de los gráficos, lo que permite ideas más rápidas y toma de decisiones informadas.
Ya sea que sea un investigador, científico de datos o desarrollador que trabaje con literatura científica, la integración de Claude de Anthrope en su flujo de trabajo en amazon Bedrock puede aumentar significativamente su productividad y precisión. Con la capacidad de procesar documentos complejos a escala, puede centrarse en tareas de nivel superior y descubrir ideas valiosas de sus datos.
Abrace el futuro del procesamiento de documentos impulsado por la IA y desbloquea nuevas posibilidades para su organización con Claude de Anthrope en amazon Bedrock. Lleve su análisis de documentos científicos al siguiente nivel y manténgase por delante de la curva en este paisaje en rápida evolución.
Para una mayor exploración y aprendizaje, recomendamos revisar los siguientes recursos:
Sobre los autores
 Erik Cordsen es un arquitecto de soluciones en AWS que sirve a los clientes en Georgia. Le apasiona aplicar tecnologías de nubes y ML para resolver problemas de la vida real. Cuando no está diseñando soluciones en la nube, Erik disfruta de viajar, cocinar y ciclismo.
Erik Cordsen es un arquitecto de soluciones en AWS que sirve a los clientes en Georgia. Le apasiona aplicar tecnologías de nubes y ML para resolver problemas de la vida real. Cuando no está diseñando soluciones en la nube, Erik disfruta de viajar, cocinar y ciclismo.
 Renu Yadav es una arquitecta de soluciones en amazon Web Services (AWS), donde trabaja con clientes de AWS de nivel empresarial que les proporciona orientación técnica y les ayudan a alcanzar sus objetivos comerciales. Renu tiene una fuerte pasión por el aprendizaje con su área de especialización en DevOps. Ella aprovecha su experiencia en este dominio para ayudar a los clientes de AWS a optimizar su infraestructura en la nube y optimizar sus procesos de desarrollo y implementación de software.
Renu Yadav es una arquitecta de soluciones en amazon Web Services (AWS), donde trabaja con clientes de AWS de nivel empresarial que les proporciona orientación técnica y les ayudan a alcanzar sus objetivos comerciales. Renu tiene una fuerte pasión por el aprendizaje con su área de especialización en DevOps. Ella aprovecha su experiencia en este dominio para ayudar a los clientes de AWS a optimizar su infraestructura en la nube y optimizar sus procesos de desarrollo y implementación de software.
 Venkata Moparthi es un arquitecto de soluciones senior en AWS que capacita a las organizaciones de servicios financieros y otras industrias para navegar por la transformación de la nube con experiencia especializada en migraciones en la nube, IA generativa y diseño de arquitectura segura. Su enfoque centrado en el cliente combina la innovación técnica con la implementación práctica, ayudando a las empresas a acelerar las iniciativas digitales y lograr resultados estratégicos a través de soluciones AWS personalizadas que maximicen el potencial en la nube.
Venkata Moparthi es un arquitecto de soluciones senior en AWS que capacita a las organizaciones de servicios financieros y otras industrias para navegar por la transformación de la nube con experiencia especializada en migraciones en la nube, IA generativa y diseño de arquitectura segura. Su enfoque centrado en el cliente combina la innovación técnica con la implementación práctica, ayudando a las empresas a acelerar las iniciativas digitales y lograr resultados estratégicos a través de soluciones AWS personalizadas que maximicen el potencial en la nube.






{kind=link}