 NEWSLETTER
NEWSLETTER
Pre-training language models (LMs) plays a crucial role in enabling their ability to understand and generate text. However, a major challenge lies in effectively leveraging the diversity of training corpora, which often include data from diverse sources such as Wikipedia, blogs, and social media. Models typically treat all input data equivalently, without taking into account contextual cues about source or style. This approach has two main shortcomings:
- Missed Contextual Cues: Without considering metadata such as source URLs, LMs miss important contextual information that could guide their understanding of the intent or quality of a text.
- Inefficiency in specialized tasks: Treating heterogeneous data uniformly can reduce the model's efficiency in handling tasks that require specific factual or stylistic knowledge.
These problems result in a less robust training process, higher computational costs, and suboptimal performance of subsequent tasks. Addressing these inefficiencies is essential to developing more effective and versatile language models.
Researchers at Princeton University have introduced metadata conditioning then cooling (MeCo) to address the challenges of standard pretraining. MeCo leverages readily available metadata, such as source URLs, during the pre-training phase. By prepending this metadata to the input text, the method allows the model to better associate documents with their contextual information.
MeCo operates in two stages:
- Metadata conditioning (first 90%): During the initial phase, metadata such as “URL: wikipedia.org” is prepended to the document. The model learns to recognize the relationship between metadata and document content.
- Cooling phase (last 10%): In this phase, training continues without metadata to ensure that the model can generalize to scenarios where metadata is not available during inference.
This simple approach not only speeds up pre-training but also improves the flexibility of language models, allowing them to adapt to various tasks or contexts with minimal additional effort.
Technical details and benefits of MeCo
Central mechanism:
- MeCo adds metadata, such as domain names, to the input text in the training data. For example, a Wikipedia article about Tim Cook would include the prefix “URL:wikipedia.org.”
- The objective of the training remains unchanged; The model predicts the next token based on the combined metadata and document text.
Advantages:
- Improved data efficiency: MeCo reduces the amount of training data needed. For example, a 1.6 billion parameter model trained with MeCo achieves the same post-performance as standard pre-training while using 33% less data.
- Improved model adaptability: Conditioning inference on specific metadata allows models trained with MeCo to produce results with desired attributes, such as increased feasibility or reduced toxicity.
- Minimum overhead: Unlike computationally intensive methods such as data filtering, MeCo introduces almost no additional complexity or cost.
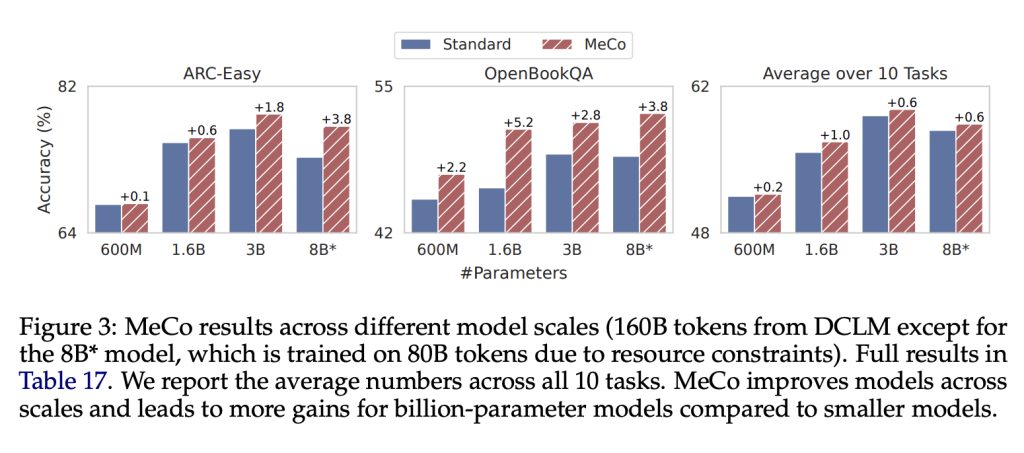
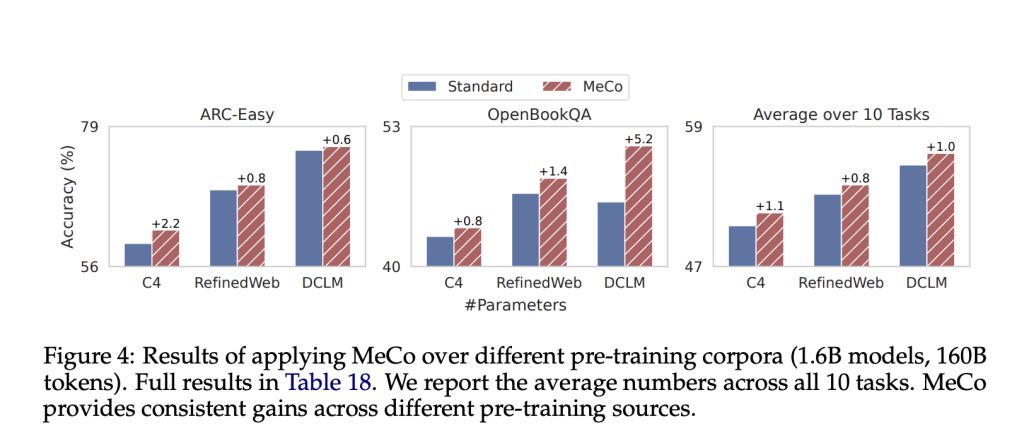
Results and insights
Performance gains: The researchers evaluated MeCo on various model scales (parameters from 600M to 8B) and data sets (C4, RefinedWeb, and DCLM). Key findings include:
- MeCo consistently outperformed standard pretraining on subsequent tasks such as question answering and common sense reasoning.
- For a 1.6B model trained on the DCLM dataset, MeCo achieved an average performance improvement of 1.0% across 10 tasks compared to standard methods.
Data efficiency: MeCo's ability to achieve equivalent results with 33% less data translates into substantial savings in computational resources. This efficiency is particularly valuable in large-scale training scenarios.
Conditional inference: The method also supports “conditional inference”, where prepending specific metadata (e.g. “factquizmaster.com”) to a message can guide the behavior of the model. For example:
- The use of “wikipedia.org” reduced the toxicity of the results generated.
- Prepending synthetic URLs improved performance on tasks such as answering common knowledge questions.
Ablation studies: Experiments showed that the benefits of MeCo derive primarily from its ability to group documents by metadata rather than the specific semantic content of the metadata. This suggests that even synthetic metadata or hashes can improve training efficiency.
Conclusion
The metadata conditioning then cooling (MeCo) method is a practical and effective approach to optimize language model pre-training. By leveraging metadata, MeCo addresses inefficiencies in standard pre-training, reducing data requirements and improving both performance and adaptability. Its simplicity and minimal computational overhead make it an attractive option for researchers and practitioners developing robust and efficient language models.
As natural language processing evolves, techniques like MeCo highlight the value of using metadata to refine training processes. Future research could explore integrating MeCo with other innovative approaches, such as domain-specific tuning or dynamic metadata generation, to further improve its effectiveness.
Verify he Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on <a target="_blank" href="https://twitter.com/Marktechpost”>twitter and join our Telegram channel and LinkedIn Grabove. Don't forget to join our SubReddit over 60,000 ml.
UPCOMING FREE ai WEBINAR (JANUARY 15, 2025): <a target="_blank" href="https://info.gretel.ai/boost-llm-accuracy-with-sd-and-evaluation-intelligence?utm_source=marktechpost&utm_medium=newsletter&utm_campaign=202501_gretel_galileo_webinar”>Increase LLM Accuracy with Synthetic Data and Assessment Intelligence–<a target="_blank" href="https://info.gretel.ai/boost-llm-accuracy-with-sd-and-evaluation-intelligence?utm_source=marktechpost&utm_medium=newsletter&utm_campaign=202501_gretel_galileo_webinar”>Join this webinar to learn practical information to improve LLM model performance and accuracy while protecting data privacy..
Nikhil is an internal consultant at Marktechpost. He is pursuing an integrated double degree in Materials at the Indian Institute of technology Kharagpur. Nikhil is an ai/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in materials science, he is exploring new advances and creating opportunities to contribute.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}