NEWSLETTER
NEWSLETTER
En los últimos años, se han logrado avances significativos en la investigación y mejora de las capacidades de razonamiento de modelos de lenguaje grandes, con un fuerte enfoque en mejorar su competencia para resolver
Problemas aritméticos y matemáticos.
Un modelo con buen razonamiento aritmético y matemático puede ayudar en:
- Aprendizaje personalizado: Los tutores con tecnología de inteligencia artificial pueden adaptarse a las necesidades individuales de los estudiantes, ayudándolos a comprender conceptos matemáticos complejos de manera más efectiva.
- Asistencia para la resolución de problemas: La automatización de explicaciones paso a paso para la resolución de problemas mejora la participación y la comprensión de los estudiantes.
- Diseño curricular: Creación de módulos de aprendizaje adaptativos y progresivos en materias como álgebra y cálculo.
Este artículo explora cómo los avances en el razonamiento matemático están impulsando innovaciones en modelos de IA como Qwen2.5-Math y sus aplicaciones en el aprendizaje personalizado, la resolución de problemas y el diseño curricular.
Objetivos de aprendizaje
- Comprender y explorar la serie Qwen2.5-Math y sus componentes.
- Obtenga más información sobre la arquitectura del modelo Qwen2.5-Math.
- Obtenga exposición práctica sobre Qwen2.5-Math con ejemplos.
- Conozca el rendimiento de Qwen2.5-Math en varios puntos de referencia.
¿Qué es Qwen2.5-Math?
La serie Qwen2.5-Math es la última incorporación a la serie Qwen de Alibaba Cloud de modelos de lenguaje grande de código abierto específicos para matemáticas. Sigue al lanzamiento anterior de Qwen2-Math, una serie de modelos de lenguaje matemático especializados basados en los LLM de Qwen2. Estos modelos demuestran capacidades matemáticas superiores, superando tanto las alternativas de código abierto como incluso algunos modelos de código cerrado como GPT-4o.
Esta serie demuestra mejoras significativas en el rendimiento con respecto a la serie Qwen2-Math en los puntos de referencia de matemáticas en chino e inglés. Si bien esta serie aplica Chain-of-Thought (CoT) para resolver problemas matemáticos específicos en inglés únicamente, la serie Qwen2.5-Math amplía sus capacidades al incorporar CoT y Tool-Integrated Reasoning (TIR), para abordar problemas matemáticos en ambos. Chino e inglés de manera efectiva.
Qwen2.5-Math y Qwen2-Math
La comparación entre Qwen2.5-Math y Qwen2-Math destaca los avances en el razonamiento matemático y las capacidades de resolución de problemas logrados en la última versión de los modelos de lenguaje específicos de matemáticas de Alibaba Cloud.
| Propiedad | Qwen2-Matemáticas | Qwen2.5-Matemáticas |
|---|---|---|
| Tamaño de los datos previos al entrenamiento | 700B tokens (de Qwen Math Corpus v1) | Más de 1T de tokens (de Qwen Math Corpus v2) |
| Idiomas admitidos | Inglés | inglés y chino |
| Acercarse | Cadena de pensamiento (COT) | Cadena de pensamiento (COT), razonamiento integrado en herramientas (TIR) |
| Puntuación de referencia (GSM8K, Matemáticas y MMLU-STEM) | 89,1, 60,5, 79,1 | 90,8, 66,8, 82,8 |
| Variantes de modelo | Qwen2-Matemáticas-1.5B/7B/72B | Qwen2.5-Matemáticas-1.5B/7B/72B |
Optimización de datos de entrenamiento
La serie Qwen2.5-Math se entrena utilizando Qwen Math Corpus v2, que comprende más de 1 billón de tokens de datos matemáticos de alta calidad tanto en inglés como en chino. Este conjunto de datos incluye datos matemáticos sintéticos generados utilizando el modelo Qwen2-Math-72B-Instruct y datos matemáticos chinos agregados obtenidos de contenido web, libros y repositorios de códigos a través de múltiples ciclos de recuperación.
Conjunto de datos de cadena de pensamiento (CoT)
El conjunto de datos de cadena de pensamiento (CoT) para Qwen2.5-Math es una colección completa de problemas matemáticos destinados a mejorar las capacidades de razonamiento del modelo. Incluye:
- 580.000 problemas en inglés y 500.000 matemáticos, incluidos elementos anotados y sintetizados.
- Los datos anotados se derivan de fuentes como GSM8K, MATH y NuminaMath.
Conjunto de datos de razonamiento integrado en herramientas (TIR)
Para abordar los desafíos computacionales y algorítmicos que enfrentan las indicaciones de CoT, como resolver ecuaciones cuadráticas o calcular valores propios, se introdujo el conjunto de datos de razonamiento integrado en herramientas (TIR). Este conjunto de datos mejora la competencia del modelo en manipulación simbólica y cálculos precisos al permitirle utilizar un intérprete de Python para tareas de razonamiento. Incluye:
- 190.000 problemas de puntos de referencia como GSM8K, MATH, CollegeMath y NuminaMath.
- Problemas de 205k creados utilizando técnicas de MuggleMath y DotaMath para desarrollar consultas dentro de conjuntos de entrenamiento GSM8K y MATH.
Entrenamiento de modelos eficientes
Dado que el modelo Qwen2.5-Math es la versión mejorada del modelo Qwen2-Math, su entrenamiento se deriva de Qwen2-Math de la siguiente manera:
- Los modelos Qwen2-Math se entrenan en Qwen Math Corpus v1, un conjunto de datos de alta calidad que contiene aproximadamente 700 mil millones de tokens de contenido matemático.
- Los desarrolladores entrenan un modelo de recompensa específico para matemáticas, Qwen2-Math-RM, derivado del modelo Qwen2-Math-72B.
- Los modelos básicos de la serie Qwen2.5 sirven para la inicialización de parámetros, mejorando la comprensión del lenguaje, la generación de código y las capacidades de razonamiento de texto.
- Después de entrenar el modelo base Qwen2.5-Math, los desarrolladores entrenan un modelo de recompensa específico para matemáticas, Qwen2.5-Math-RM-72B, basado en Qwen2.5-Math-72B. Este modelo de recompensa evoluciona los datos SFT a través de Muestreo de rechazo para el modelo SFT (Qwen2.5-Math-SFT).
- Al final se construye un modelo de instrucción (Qwen2.5-Math-Instruct) para pulir la calidad de las respuestas. Este modelo se crea mediante una iteración adicional utilizando los modelos Qwen2-Math-Instruct y Qwen2.5-Math-RM-72B. El proceso incorpora datos de razonamiento integrado en herramientas (TIR) y datos SFT, refinados mediante optimización de políticas relativas al grupo (GRPO), para pulir aún más el rendimiento del modelo.
Optimización del rendimiento del modelo
Mejorar el rendimiento del modelo es clave para ofrecer resultados más rápidos y precisos, garantizando eficiencia y confiabilidad en las aplicaciones.
Rendimiento de los modelos básicos
Los modelos base Qwen2.5-Math-1.5B/7B/72B lograron mejoras significativas en los puntos de referencia de matemáticas en inglés (GSM8K, Matemáticasy MMLU-STEM) y puntos de referencia de matemáticas chinos (CMATH, GaoKao Math Cloze y GaoKao Math QA) en comparación con Qwen2-Math-1.5B/7B/72B.
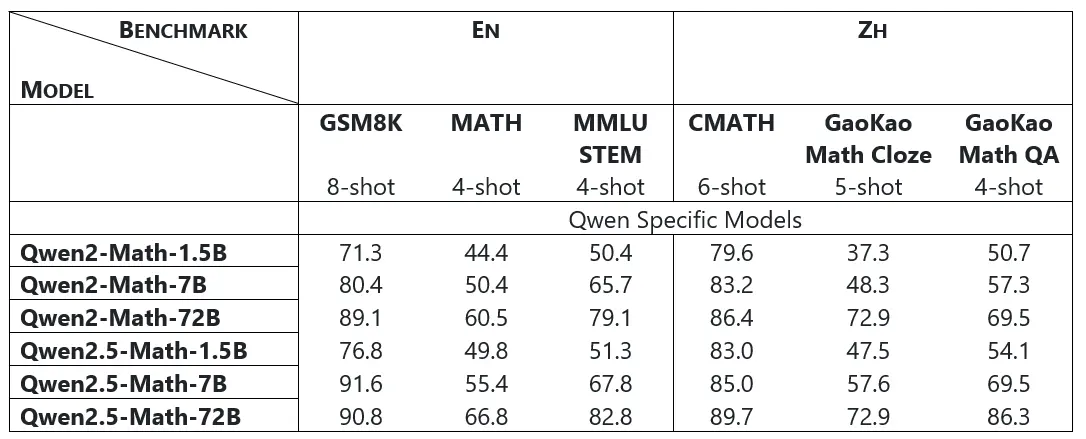
Por ejemplo, los modelos Qwen2.5-Math-1.5B/7B/72B muestran una mejora significativa de 5,4, 5,0, 6,3 en MATEMÁTICAS y una mejora en la puntuación de 3,4, 12,2, 19,8 en GaoKao Math QA.
Rendimiento de los modelos adaptados a las instrucciones
El modelo Qwen2.5-Math-72B-Instruct superó tanto a los modelos de código abierto como a los mejores modelos de código cerrado, como GPT-4o y Gemini Math-Specialized 1.5 Pro.
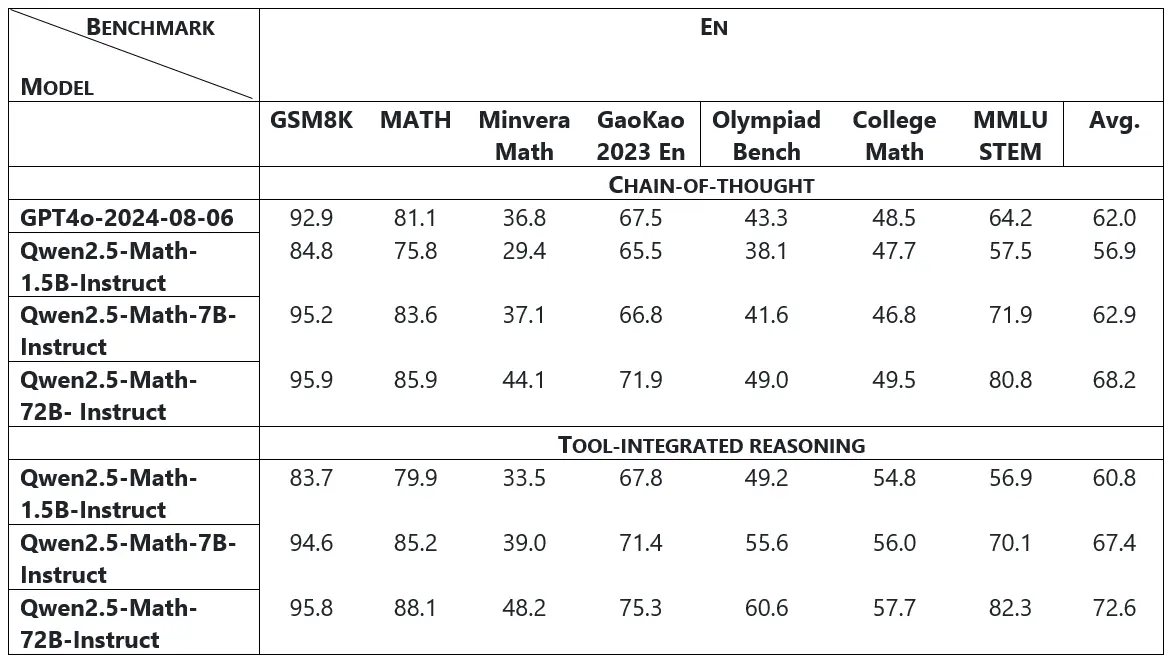
El modelo Qwen2.5-Math-72B-Instruct supera a su predecesor (el modelo Qwen2-Math-72B-Instruct) por una media de 4,4 puntos en inglés y 6,1 puntos en chino. Este desempeño marca su posición como el modelo matemático de código abierto líder disponible en la actualidad.
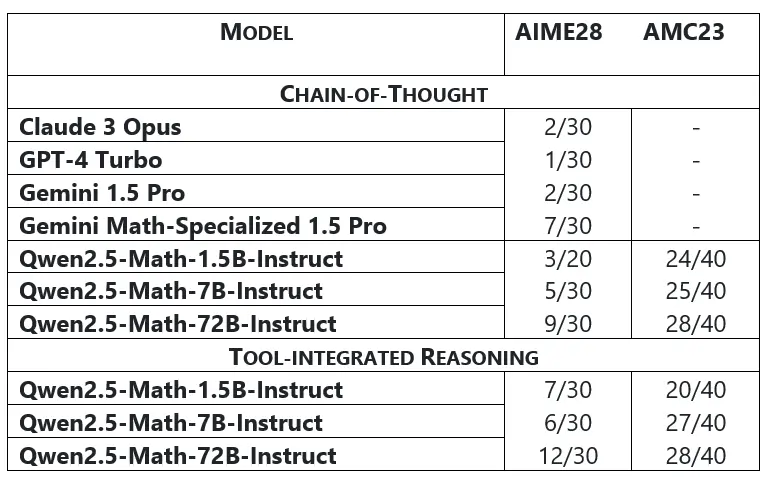
En pruebas de referencia extremadamente desafiantes como AIME 2024 y AMC23, modelos como Claude3 Opus, GPT-4 Turbo y Gemini 1.5 Pro resuelven solo 1 o 2 de 30 problemas. Por el contrario, Qwen2.5-Math-72B-Instruct demuestra un rendimiento notable, resolviendo 9 problemas en el modo CoT de decodificación Greedy y 12 problemas en el modo TIR. Además, con la ayuda del modelo de recompensa (RM), Qwen2.5-Math-7B-Instruct logra la impresionante cifra de 21 problemas resueltos, lo que demuestra sus capacidades superiores de resolución de problemas matemáticos.
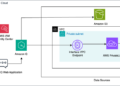
Ejecutando demostración
Veamos la demostración de Qwen2.5-Math usando el espacio HuggingFace aquí.
Este espacio proporciona una interfaz de usuario basada en web para ingresar problemas matemáticos o aritméticos en formato de imagen o texto para probar las capacidades del modelo.
Para admitir multimodalidades, este espacio utiliza Qwen2-VL para OCR y Qwen2.5-Math para razonamiento matemático.
Qwen-VL (Qwen Large Vision Language Model) es el modelo de lenguaje de visión multimodal que admite imágenes y texto como entradas. Naturalmente, admite inglés y chino para realizar diversas tareas de generación de imagen a texto, como subtítulos de imágenes, respuesta visual a preguntas, razonamiento visual, reconocimiento de texto, etc.
La serie Qwen-VL contiene muchos modelos como Qwen-VL, Qwen-VL-Chat, Qwen-VL-Plus, Qwen-VL-Max
etc. Qwen-VL-Max es el modelo de lenguaje visual grande más capaz de Qwen para ofrecer un rendimiento óptimo en una gama aún más amplia de tareas complejas.
El sistema utiliza el modelo qwen-vl-max-0809 para comprender, procesar y extraer información textual de las imágenes de entrada. La función Process_Image() primero recibe la imagen de entrada y extrae el contenido relacionado con las matemáticas, asegurando una transcripción precisa de cualquier fórmula LaTeX. Luego, el sistema aplica el siguiente mensaje estándar para extraer el contenido textual relacionado con las matemáticas de la imagen.
El mensaje indica: “Describe el contenido relacionado con las matemáticas en esta imagen, asegurando una transcripción precisa de cualquier fórmula LaTeX. No describas detalles no matemáticos”.
import os
os.system('pip install dashscope -U')
import tempfile
from pathlib import Path
import secrets
import dashscope
from dashscope import MultiModalConversation, Generation
from PIL import Image
YOUR_API_TOKEN = os.getenv('YOUR_API_TOKEN')
dashscope.api_key = YOUR_API_TOKEN
math_messages = ()
def process_image(image, shouldConvert=False):
global math_messages
math_messages = () # reset when upload image
uploaded_file_dir = os.environ.get("GRADIO_TEMP_DIR") or str(
Path(tempfile.gettempdir()) / "gradio"
)
os.makedirs(uploaded_file_dir, exist_ok=True)
name = f"tmp{secrets.token_hex(20)}.jpg"
filename = os.path.join(uploaded_file_dir, name)
if shouldConvert:
new_img = Image.new('RGB', size=(image.width, image.height), color=(255, 255, 255))
new_img.paste(image, (0, 0), mask=image)
image = new_img
image.save(filename)
messages = ({
'role': 'system',
'content': ({'text': 'You are a helpful assistant.'})
}, {
'role': 'user',
'content': (
{'image': f'file://{filename}'},
{'text': 'Please describe the math-related content in this image, ensuring that any LaTeX formulas are correctly transcribed. Non-mathematical details do not need to be described.'}
)
})
response = MultiModalConversation.call(model="qwen-vl-max-0809", messages=messages)
os.remove(filename)
return response.output.choices(0)("message")("content")#import csvPaso 2: razonamiento matemático usando Qwen2.5-Math
Este paso extrae la descripción de la imagen, que luego se pasa al modelo Qwen2.5 junto con la pregunta del usuario para generar la respuesta. El modelo qwen2.5-math-72b-instruct realiza el razonamiento matemático en este proceso.
def get_math_response(image_description, user_question):
global math_messages
if not math_messages:
math_messages.append({'role': 'system', 'content': 'You are a helpful math assistant.'})
math_messages = math_messages(:1)
if image_description is not None:
content = f'Image description: {image_description}\n\n'
else:
content=""
query = f"{content}User question: {user_question}"
math_messages.append({'role': 'user', 'content': query})
response = Generation.call(
model="qwen2.5-math-72b-instruct",
messages=math_messages,
result_format="message",
stream=True
)
answer = None
for resp in response:
if resp.output is None:
continue
answer = resp.output.choices(0).message.content
yield answer.replace("\\", "\\\\")
print(f'query: {query}\nanswer: {answer}')
if answer is None:
math_messages.pop()
else:
math_messages.append({'role': 'assistant', 'content': answer})Habiendo conocido los modelos utilizados en este espacio, veamos algunos ejemplos para
evaluar la capacidad del modelo para resolver problemas matemáticos o aritméticos.
Ejemplo1
Una imagen de entrada que contiene el siguiente planteamiento del problema:
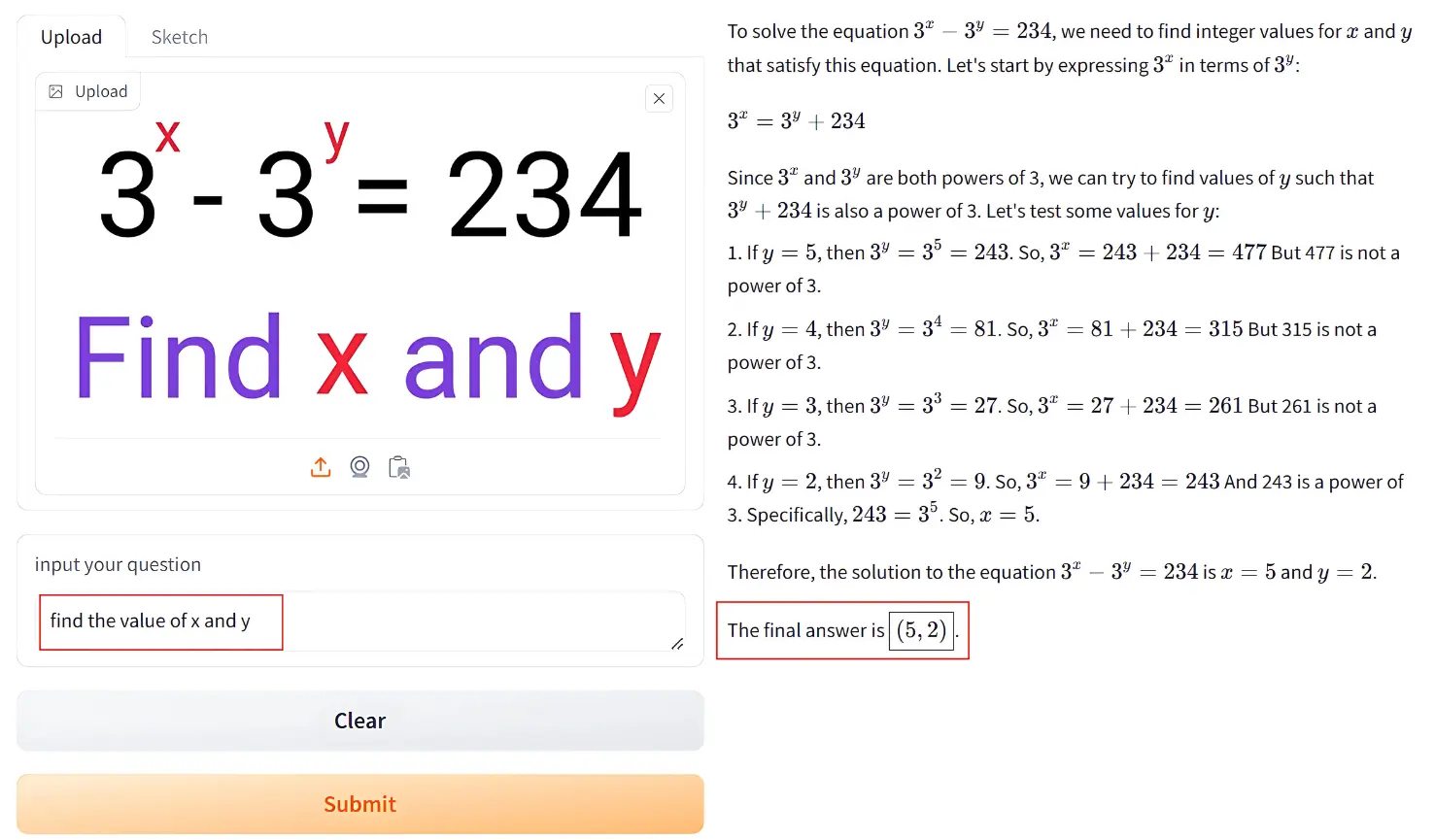
El modelo encuentra los valores de x como 5 e y como 2. También proporciona instrucciones paso a paso.
Razonamiento en lenguaje natural mientras encuentra los valores de x e y.
Ejemplo2
Una imagen de entrada que contiene el siguiente planteamiento del problema:
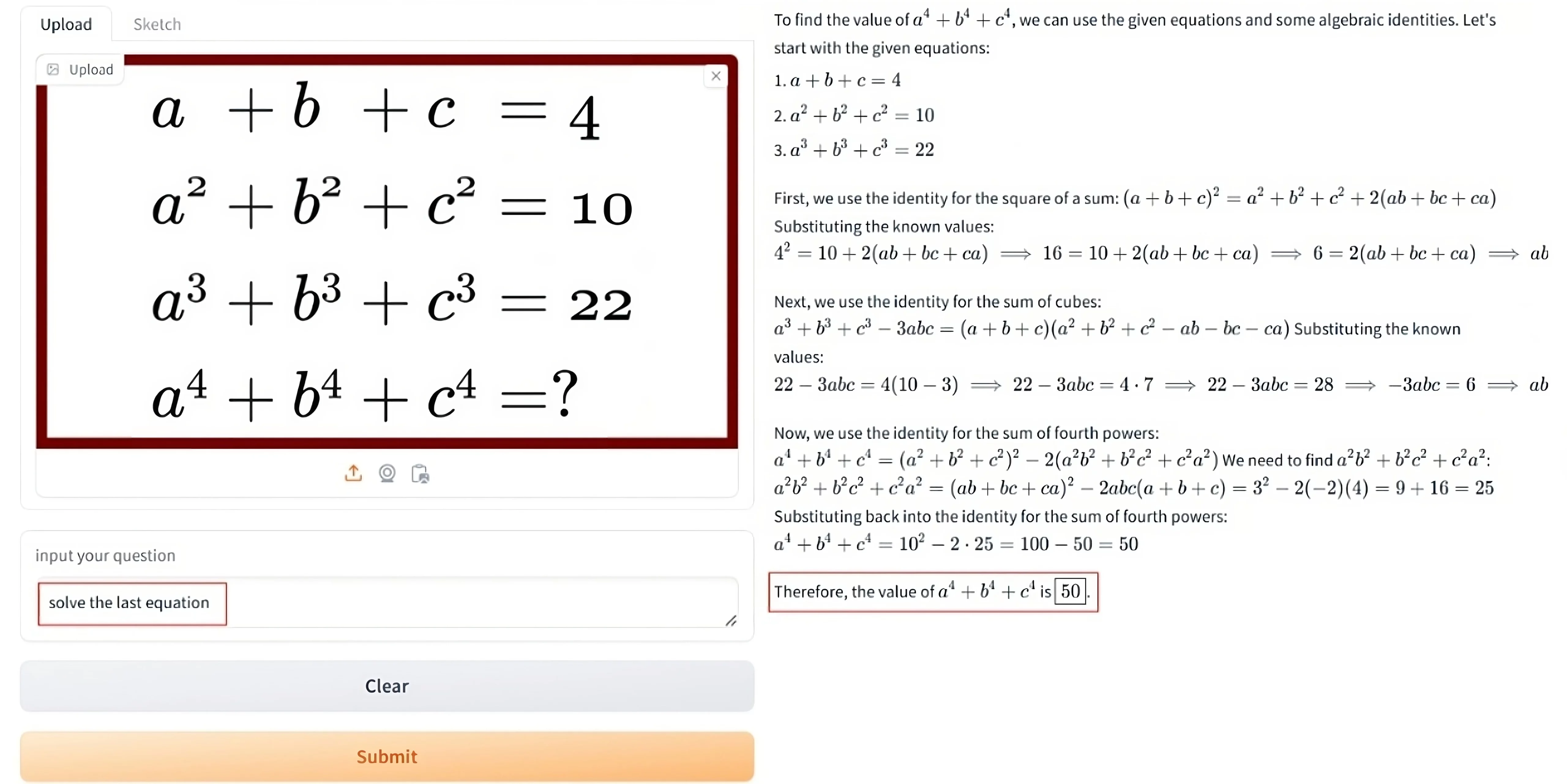
El modelo descubre que el valor de la última expresión es 50.
Ejemplo3
Una imagen de entrada que contiene el siguiente planteamiento del problema:

El modelo descubre que el valor de la expresión anterior es 5.
Conclusión
En este artículo, exploramos Qwen2.5-Math, una serie de modelos matemáticos con sólidas capacidades de razonamiento. Examinamos sus componentes, datos de entrenamiento, arquitectura y rendimiento en varios puntos de referencia estándar. Además, revisamos la demostración y la probamos con una variedad de ejemplos de moderados a complejos.
Conclusiones clave
- Los modelos Qwen2.5-Math admiten chino e inglés y muestran capacidades avanzadas de razonamiento matemático. Utiliza técnicas como la cadena de pensamiento (CoT) y el razonamiento integrado en herramientas (TIR).
- La serie Qwen2.5 incluye múltiples variantes según la cantidad de parámetros, con modelos disponibles en parámetros 1.5B, 7B y 72B.
- Los modelos Qwen2.5-Math aprovechan 1 billón de tokens para el entrenamiento previo, un aumento sustancial en comparación con los 700 mil millones de tokens utilizados para Qwen2-Math.
- Qwen2.5-Math supera a Qwen2-Math en varios puntos de referencia en inglés y chino. Además, supera a modelos como Claude3 Opus, GPT-4 Turbo y Gemini 1.5 Pro en puntos de referencia desafiantes como AIME 2024.
Preguntas frecuentes
R. Qwen2.5-Math es una versión mejorada de Qwen2-Math que ofrece rendimiento mejorado, mayor precisión en la resolución de problemas matemáticos complejos y técnicas de entrenamiento mejoradas.
R. Qwen2.5-Math normalmente supera a Qwen2-Math en tareas complejas debido a su capacitación avanzada y capacidades refinadas en razonamiento matemático.
R. Ambos modelos están diseñados para el razonamiento matemático, pero Qwen2.5 utiliza algoritmos y datos de entrenamiento más sofisticados para resolver problemas desafiantes de manera más efectiva.
R. Qwen2.5-Math se beneficia de un conjunto de datos más grande y diverso, lo que mejora su capacidad para generalizar y resolver problemas matemáticos complejos con mayor precisión que Qwen2-Math.
R. Qwen2.5 optimiza un procesamiento más rápido y proporciona respuestas más rápidas en comparación con Qwen2-Math manteniendo una alta precisión.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.

Un profesional de ciencia de datos con 7,5 años de experiencia en ciencia de datos, aprendizaje automático y programación. Experiencia práctica en diferentes dominios como análisis de datos, aprendizaje profundo, big data y procesamiento de lenguaje natural.