 NEWSLETTER
NEWSLETTER
In recent years, the evolution of artificial intelligence has generated increasingly sophisticated large language models (LLM). However, training these models remains a complex challenge due to their immense computational requirements. Traditionally, training these models has only been possible in centralized environments with high-bandwidth interconnections, typically within large data centers controlled by a few technology giants. This centralized paradigm limits accessibility as it requires significant resources that only a few organizations can afford. These restrictions have raised concerns about equitable access to advanced ai technologies and their potential monopolization. To address these barriers, researchers have begun to explore collaborative and decentralized training approaches. The challenge lies in overcoming issues such as low inter-node bandwidth and unpredictable node availability, which make decentralized training more complex than its centralized counterpart.
The release of INTELLECT-1
PRIME Intellect has released INTELLECT-1 (Instruct + Base), the world's first collaboratively trained 10 billion parameter language model. This model demonstrates the feasibility of using decentralized, community-driven resources for advanced LLM training. PRIME Intellect used its <a target="_blank" href="https://github.com/PrimeIntellect-ai/prime” target=”_blank” rel=”noreferrer noopener”>MAIN Framespecifically designed to overcome the challenges of decentralized training, including network unreliability and the dynamic addition or removal of computing nodes. The framework used up to 112 H100 GPUs across three continents and achieved a compute utilization rate of up to 96% under optimal conditions, demonstrating that decentralized training can match the performance levels of traditional setups. This approach expands access to high-performance ai models and fosters a collaborative research environment where contributors from around the world can participate in ai development.
Technical details
According to the official statement, INTELLECT-1 was developed using a diverse combination of high-quality data sets, including publicly available data and proprietary data sets curated by PRIME Intellect and its partners. The model was trained on 1 billion tokens, ensuring it has a broad understanding of multiple domains. The training process involved 14 simultaneous nodes spread across three continents, with compute sponsors dynamically joining and leaving as needed. This dynamic approach allowed for significant flexibility, which is crucial for real-world deployment scenarios. PRIME Intellect also ensured training stability through innovations such as live checkpoints and fault-tolerant communication, enabled by the PRIME framework.
Technically, the training of INTELLECT-1 was made possible by innovations in the PRIME framework, which addressed the limitations of geographically distributed nodes. PRIME introduces ElasticDeviceMesh, an abstraction that manages both communication over the Internet and local, fault-tolerant data exchange between nodes. Hybrid training approaches were implemented that combine fully fragmented data parallel (FSDP) techniques for intra-node efficiency and distributed low communication (DiLoCo) algorithms for minimal inter-node communication. To minimize bandwidth requirements, the PRIME framework included an 8-bit quantization strategy for gradient transfers, which reduced the communication payload by up to 400 times compared to traditional data-parallel training. Fault tolerance was managed through dynamic node management, allowing new nodes to join seamlessly and failed nodes to be removed with minimal disruption. These innovations facilitated effective training of decentralized models while maintaining high computational efficiency.
Results and implications of benchmarks
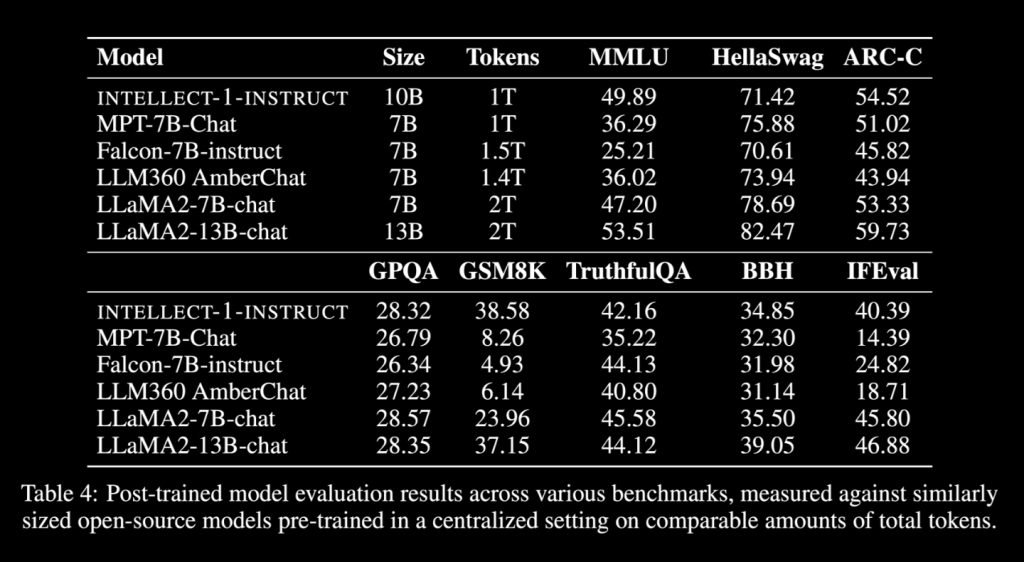
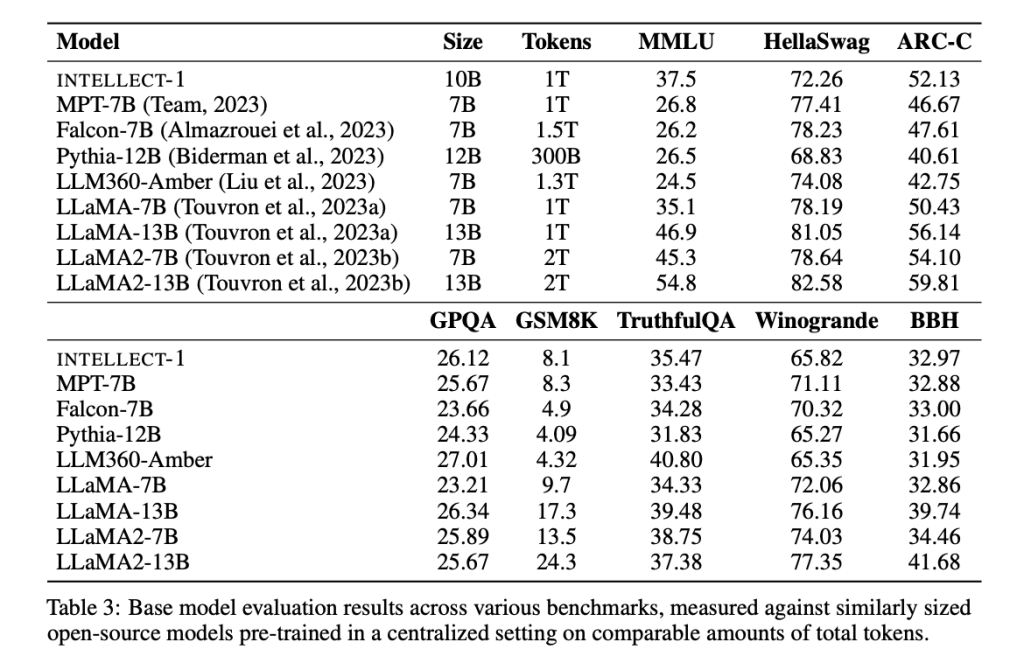
The launch of INTELLECT-1 marks an important step forward in making LLM training accessible beyond large corporations. The results of the training process reveal a model that competes with similarly sized models trained in centralized environments. For example, INTELLECT-1 achieved an accuracy of 37.5% on the MMLU benchmark and 72.26% on HellaSwag. Additionally, INTELLECT-1 outperformed several other open source models on specific benchmarks, including 65.82% on the WinoGrande challenge. Although these numbers are slightly behind some state-of-the-art centralized models, the results are notable given the challenges of decentralized training. More importantly, this experiment sets a precedent for large-scale collaborations and paves the way for future developments in community-led ai projects. The global network of 30 independent IT contributors not only ensured the success of the project but also highlighted the scalability of such efforts. As decentralized models grow in scale and communication strategies improve, the gap between centralized and decentralized training is likely to continue to close.
Conclusion
The launch of INTELLECT-1 represents a milestone in the quest for more accessible ai research. By leveraging decentralized resources to train a 10 billion-parameter language model, PRIME Intellect and its collaborators have demonstrated that advanced ai development does not have to be limited to a few elite corporations. Through innovations in distributed training frameworks and global collaboration, INTELLECT-1 sets a new standard for what is possible in open and inclusive ai research. The PRIME framework, along with the publicly available INTELLECT-1 model and training data, is expected to inspire more community-driven projects, helping to level the playing field in the ai space and opening doors for contributions. more diverse. This is an important step in making ai an accessible and inclusive resource for everyone.
Verify he <a target="_blank" href="https://github.com/PrimeIntellect-ai/prime/blob/main/INTELLECT_1_Technical_Report.pdf” target=”_blank” rel=”noreferrer noopener”>Paper, <a target="_blank" href="https://www.primeintellect.ai/blog/intellect-1-release” target=”_blank” rel=”noreferrer noopener”>Detailsand models hugging their faces (Instruct and Base). All credit for this research goes to the researchers of this project. Also, don't forget to follow us on <a target="_blank" href="https://twitter.com/Marktechpost”>twitter and join our Telegram channel and LinkedIn Grabove. If you like our work, you will love our information sheet.. Don't forget to join our 59k+ ML SubReddit.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of artificial intelligence for social good. Their most recent endeavor is the launch of an ai media platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is technically sound and easily understandable to a wide audience. The platform has more than 2 million monthly visits, which illustrates its popularity among the public.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}