
Large language models (LLMs) have demonstrated notable in-context learning (ICL) capabilities, where they can learn tasks from demonstrations without requiring additional training. A critical challenge in this field is understanding and predicting the relationship between the number of proofs provided and the improvement in model performance, known as the ICL curve. There is a need to better understand this relationship despite its important implications for various applications. Accurate prediction of ICL curves is of crucial importance for determining optimal demonstration quantities, anticipating potential alignment failures in many-shot scenarios, and evaluating the tuning needed to control undesired behavior. The ability to model these learning curves effectively would improve decision making in implementation strategies and help mitigate potential risks associated with LLM implementations.
Various research approaches have attempted to decode the underlying mechanisms of in-context learning in large language models, with divergent theories emerging. Some studies suggest that LMs trained on synthetic data behave like Bayesian learners, while others propose that they follow gradient descent patterns, and some indicate that the learning algorithm varies depending on the complexity of the task, the scale of the model, and the progress of training. Power laws have emerged as a predominant framework for modeling LM behavior, including ICL curves in different environments. However, existing research has notable limitations. No previous work has directly modeled the ICL curve based on fundamental assumptions of the learning algorithm. Furthermore, post-training modifications have proven to be largely ineffective, with studies revealing that such changes are often superficial and easy to circumvent, which is particularly concerning because ICL can reinstate behaviors that were supposedly suppressed through adjustments.
The researchers propose a model that introduces Bayesian laws to model and predict learning curves in context in different language modeling scenarios. The study evaluates these laws using synthetic data experiments with GPT-2 models and real-world tests on standard benchmarks. The approach goes beyond simple curve fitting and provides interpretable parameters that capture prior task distribution, ICL efficiency, and example probabilities across different tasks. The research methodology encompasses two main experimental phases: first, comparing the performance of Bayesian laws with existing power law models in curve prediction and, second, analyzing how post-training modifications affect the behavior of ICL in both favored and disfavored tasks. The study culminates with extensive testing on full-scale models ranging from parameters 1B to 405B, including capabilities evaluation, security benchmarks, and a robust multi-shot jailbreak dataset.
The Bayesian scaling laws architecture for ICL is based on fundamental assumptions about how language models process and learn from examples in context. The framework begins by treating ICL as a Bayesian learning process, applying Bayes' theorem iteratively to model how each new example in context updates the previous task. A key innovation in the architecture is the introduction of parameter reduction techniques to avoid overfitting. This includes two different approaches to parameter binding, sampling and scoring, which help maintain model efficiency while scaling linearly with the number of distributions. The architecture incorporates an ICL efficiency coefficient 'K' that takes into account the token-by-token nature of LLM processing and variations in the informativeness of examples, effectively modulating the strength of Bayesian updates as a function of length and the complexity of the example.
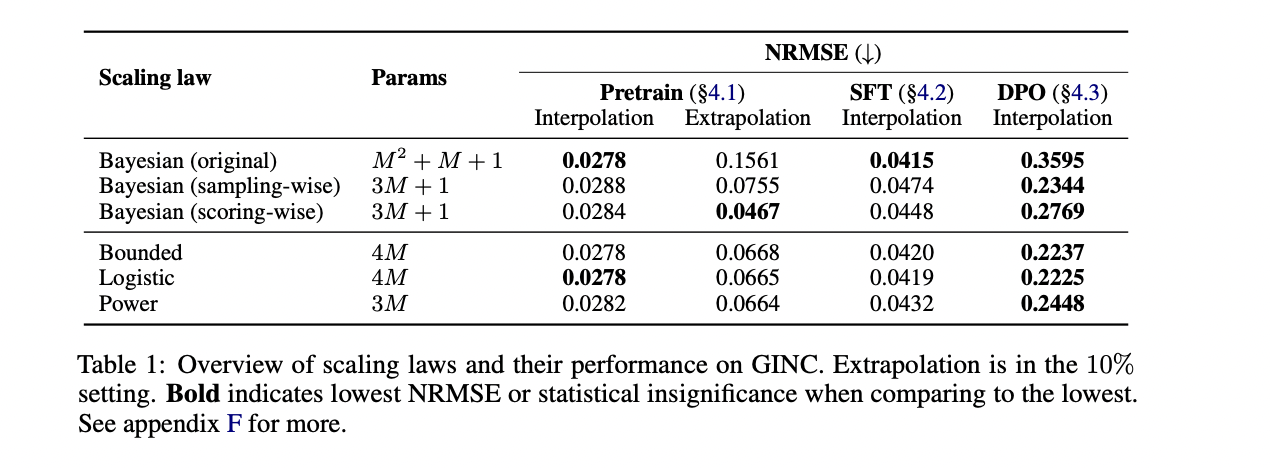
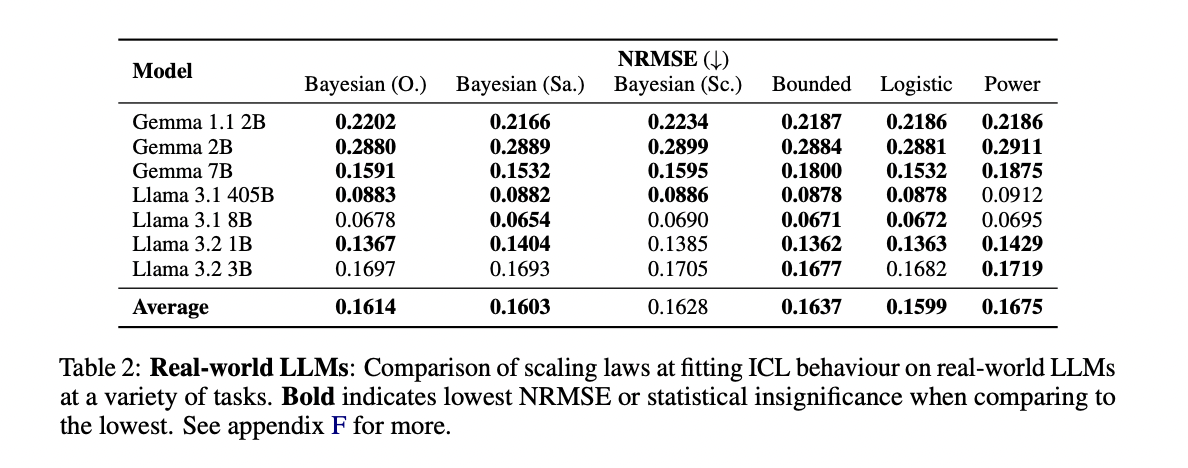
Experimental results demonstrate superior performance of Bayesian scaling laws compared to existing approaches. In interpolation tests, the original Bayesian scaling law achieved a significantly lower normalized root mean square error (NRMSE) at all model scales and path lengths, comparable only to a robust logistic baseline. The Bayesian scoring law particularly stood out in extrapolation tasks, showing the best performance in predicting the remaining 90% of the ICL curves using only the first 10% of the data points. Beyond numerical superiority, Bayesian laws offer interpretable parameters that provide meaningful information about model behavior. The results reveal that the prior distributions align with uniform pre-training distributions, and ICL efficiency is positively correlated with both model depth and example length, indicating that larger models achieve more in-context learning. fast, especially with more informative examples.
Comparing the Llama 3.1 8B Base and Instruct versions revealed crucial information about the effectiveness of instruction tuning. The results show that while instruction tuning successfully reduces the prior probability of unsafe behavior across several assessment metrics (including damage and personality assessments), it fails to effectively prevent multiple-attempt jailbreaking. The Bayesian scaling law demonstrates that posterior probabilities eventually saturate, regardless of the reduced prior probabilities achieved by instruction adjustment. This suggests that instruction tuning primarily modifies prior tasks rather than fundamentally altering the model's underlying task knowledge, possibly due to the relatively limited computational resources allocated to instruction tuning compared to pretraining.
The research successfully resolves two fundamental questions about learning in context by developing and validating Bayesian scaling laws. These laws demonstrate remarkable effectiveness in modeling ICL behavior in both small-scale LMs trained with synthetic data and large-scale models trained in natural language. The key contribution lies in the interpretability of the Bayesian formulation, which provides clear information about the background, learning efficiency, and conditional probabilities of the tasks. This framework has proven valuable in understanding scale-dependent ICL capabilities, analyzing the impact of adjustment on knowledge retention, and comparing base models to their instructionally adjusted counterparts. The success of this approach suggests that continued research into scaling laws could yield more crucial insights into the nature and behavior of learning in context, paving the way for more effective and controllable linguistic models.
look at the Paper and GitHub page. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter and join our Telegram channel and LinkedIn Grabove. If you like our work, you will love our information sheet.. Don't forget to join our SubReddit over 55,000ml.
(Sponsorship opportunity with us) Promote your research/product/webinar to over 1 million monthly readers and over 500,000 community members
Asjad is an internal consultant at Marktechpost. He is pursuing B.tech in Mechanical Engineering from Indian Institute of technology, Kharagpur. Asjad is a machine learning and deep learning enthusiast who is always researching applications of machine learning in healthcare.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>





{kind=link}