
Generating accurate and aesthetically appealing visual texts in text-to-image generation models presents a significant challenge. While diffusion-based models have succeeded in creating diverse, high-quality images, they often struggle to produce readable, well-placed visual text. Common problems include spelling errors, omitted words, and incorrect text alignment, particularly when generating languages other than English, such as Chinese. These limitations restrict the applicability of such models in real-world use cases, such as digital media production and advertising, where accurate generation of visual text is essential.
Current methods for visual text generation typically embed text directly into the latent space of the model or impose positional constraints during image generation. However, these approaches have limitations. Byte pair encoding (BPE), commonly used for tokenization in these models, breaks words into subwords, making it difficult to generate coherent, readable text. Furthermore, the cross-attention mechanisms in these models are not fully optimized, resulting in weak alignment between the generated visual text and the input tokens. Solutions like TextDiffuser and GlyphDraw attempt to solve these problems with rigid positional constraints or painting techniques, but this often leads to limited visual diversity and inconsistent text integration. Additionally, most current models only handle English text, leaving gaps in their ability to generate accurate text in other languages, especially Chinese.

Researchers from Xiamen University, Baidu Inc., and Shanghai artificial intelligence Laboratory introduced two core innovations: input granularity control and glyph recognition training. The mixed-granularity input strategy represents whole words instead of subwords, which avoids the challenges posed by BPE tokenization and allows for more coherent text generation. Additionally, a new training regimen was introduced that incorporates three key losses: (1) attention alignment loss, which improves cross-attention mechanisms by improving text-to-token alignment; (2) local MSE loss, which ensures that the model focuses on critical text regions within the image; and (3) OCR recognition loss, designed to boost accuracy in generated text. These combined techniques improve the visual and semantic aspects of text generation while maintaining the quality of image synthesis.
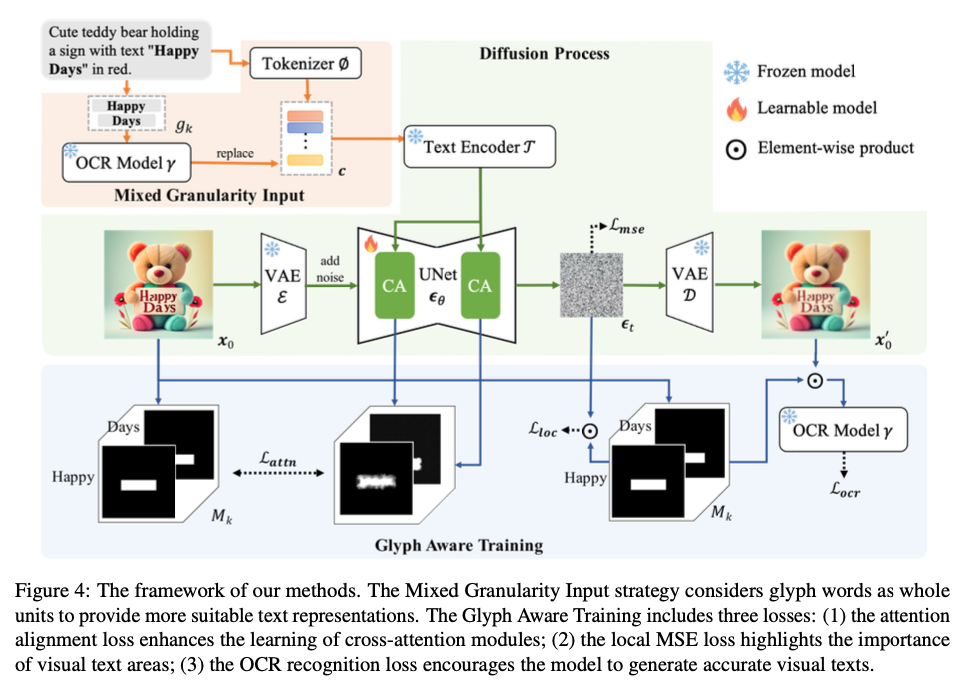
This approach uses a latent diffusion framework with three main components: a variational autoencoder (VAE) to encode and decode images, a UNet denoiser to manage the diffusion process, and a text encoder to handle input cues. To counter the challenges posed by BPE tokenization, the researchers employed a mixed-granularity input strategy, treating words as whole units rather than subwords. An OCR model is also integrated to extract glyph-level features, refining the text embeddings used by the model.
The model is trained using a data set comprising 240,000 English samples and 50,000 Chinese samples, filtered to ensure high-quality images with clear and consistent visual text. SD-XL and SDXL-Turbo backbone models were used, and training was performed over 10,000 steps at a learning rate of 2e-5.
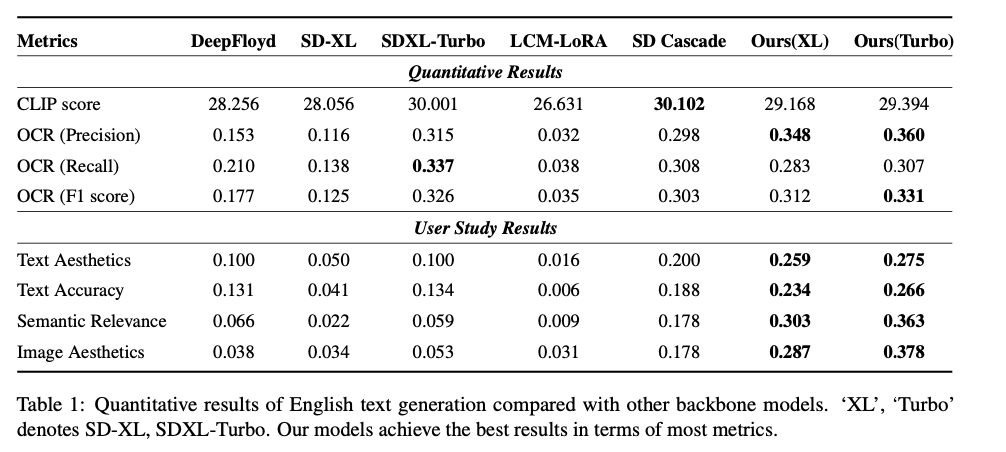
This solution shows significant improvements in both text generation accuracy and visual appeal. The precision, recall, and F1 scores for English and Chinese text generation significantly outperform those of existing methods. For example, the accuracy of OCR reaches 0.360, outperforming other basic models such as SD-XL and LCM-LoRA. The method generates more readable and visually appealing text and integrates it more seamlessly into images. Additionally, the new glyph-aware training strategy enables multilingual support, and the model effectively handles Chinese text generation, an area where previous models fall short. These results highlight the model's superior ability to produce accurate and aesthetically coherent visual text, while maintaining the overall quality of images generated in different languages.

In conclusion, the method developed here advances the field of visual text generation by addressing critical challenges related to tokenization and cross-attention mechanisms. The introduction of input granularity control and glyph recognition training enables the generation of accurate and aesthetically pleasing text in both English and Chinese. These innovations improve practical applications of text-to-image models, particularly in areas that require accurate generation of multilingual text.

look at the Paper. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter and join our Telegram channel and LinkedIn Grabove. If you like our work, you will love our information sheet.. Don't forget to join our SubReddit over 50,000ml
(Next Event: Oct 17, 202) RetrieveX – The GenAI Data Recovery Conference (Promoted)
Aswin AK is a consulting intern at MarkTechPost. He is pursuing his dual degree from the Indian Institute of technology Kharagpur. He is passionate about data science and machine learning, and brings a strong academic background and practical experience solving real-life interdisciplinary challenges.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}