 NEWSLETTER
NEWSLETTER
The approximate search for the nearest neighbor (ANNS) is a fundamental vector search technique that efficiently identifies similar elements in high -dimension vector spaces. Traditionally, Anns has served as a backbone for recovery engines and recommendation systems, however, struggle to maintain the rhythm of modern transformers architectures that use higher dimensions of dimensions and larger data sets. Unlike deep learning systems that can be scaled horizontally due to their nature without a state, Anns remains centralized, creating a severe performance of a single machine performance. Empirical tests with data sets at a scale of 100 million scale reveal that even the latest generation CPU implementations of the small navigable hierarchical algorithm (HNSW) cannot maintain adequate performance as vector dimensions increase.
Previous research on large -scale ANNs have explored two optimization routes: Hardware index and acceleration structure improvements. The improved spatial partition of multiple Éndex inverted through the quantization of multiple codes, while PQFASTSCAN improved performance with SIMD and ADAC optimizations. Diskann and Spann introduced disk -based indexation for data sets at the scale of billions, addressing the challenges of the memory hierarchy through different approaches. The song and the Caffle achieved impressive speeds through the parallel of GPU, but remain limited by the GPU memory capacity. Bang handled the data sets at the scale of billions through the hybrid CPU-GPU processing, but lacked critical comparisons of the CPU baseline. These methods often sacrifice compatibility, precision or require specialized hardware.
Researchers at the Chinese University of Hong Kong, perceptual and interactive intelligence center, and Huawei technology Laboratory theory have proposed Piloten, a Hybrid CPU-GPU system designed to overcome the limitations of existing ANS implementations. Piloten addresses the challenge: CPU implementations only fight with computational demands, while GPU solutions are limited by limited memory capacity. Solve this problem using both the abundant RAM of the CPU and the parallel processing capabilities of the GPUs. In addition, it uses a transverse process of three -stage graphics, an accelerated subrograph by transverse GPU using dimensionally reduced vectors, CPU refinement and precise search with complete vectors.
They are fundamentally reinvented by the vector search process through a “data -prepared data processing” paradigm. Minimizes the movement of data in the processing stages instead of adhering to the traditional models of “moving data for calculation”. It also consists of three stages: GPU pilot with subrograph and reduced vectors dimensionally, residual refinement using subgraph with complete and transverse final vectors using complete graphics and complete vectors. The design shows profitability with a single GPU of basic products while it is effectively scale through the vector dimensions and the complexity of the graphics. The data transfer overload is minimized only the movement of the initial consultation vector to GPU and a small set of candidates that returns to CPU after the GPU pilot.
Experimental results show Pilotann's performance advantages in various large -scale data sets. Piloten achieves a performance acceleration 3.9 times in the 96-dimensional deep data set compared to the HNSW-CPU baseline, with even more impressive profits of 5.1-5.4 times in higher dimensional data sets. Piloten offers significant speeds even in the notoriously challenging T2i data set even though there are no specific optimizations for this reference point. In addition, it shows a remarkable profitability despite using more expensive hardware. While the GPU -based platform costs 2.81 USD/hour compared to the SOLLA CPU solution at 1.69 USD/hour, Piloten achieves 2.3 times the profitability of the effectiveness for the data sets of T2I, Wiki and Laion when the dollar yield is measured.
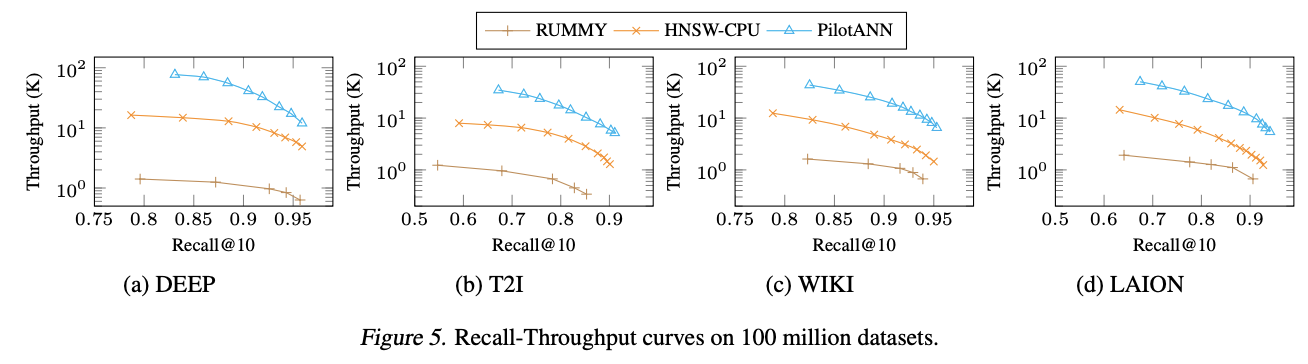
In conclusion, the researchers introduced pilotan, an advance in graphics based on CPU and GPU resources for emerging workloads. It shows great performance on existing CPU approaches only through the intelligent decomposition of the Top-K search in a CPU-GPU pipe of several stages and implementation of an efficient entry selection. Democratizes the search for closest high -performance neighbors by achieving competitive results with a single GPU of basic products, making advanced search capabilities accessible to researchers and organizations with limited computer resources. Unlike alternative solutions that require expensive high -end GPUs, pilotan allows efficient ANN implementation in common hardware configurations while searching for search accuracy.
Verify he Paper and Github page. All credit for this investigation goes to the researchers of this project. In addition, feel free to follow us <a target="_blank" href="https://x.com/intent/follow?screen_name=marktechpost” target=”_blank” rel=”noreferrer noopener”>twitter And don't forget to join our 85k+ ml of submen.

Sajad Ansari is an undergraduate last year of Iit Kharagpur. As an enthusiastic of technology, it deepens the practical applications of ai with an approach to understanding the impact of ai technologies and their implications of the real world. Its objective is to articulate complex concepts of ai in a clear and accessible way.






{kind=link}