 NEWSLETTER
NEWSLETTER
Understanding multi-page documents and news videos is a common task in people’s daily lives. To address these scenarios, large multimodal language models (MLLMs) need to be equipped with the ability to understand multiple images with rich and visually located text information. However, understanding document images is more challenging than natural images as it requires more detailed perception to recognize all texts. Existing approaches either add a high-resolution encoder or crop high-resolution images into low-resolution sub-images, both with limitations.
Previous researchers have attempted to solve the challenge of understanding document images using various techniques. Some works proposed adding a high-resolution encoder to better capture fine-grained textual information in document images. Others chose to crop high-resolution images into low-resolution sub-images and let the large language model understand their relationship.
While these approaches have achieved promising performance, they suffer from a common problem: the large number of visual tokens required to represent a single document image. For example, the InternVL 2 model costs an average of 3k visual tokens on the DocVQA single-page document understanding benchmark. Such long visual token sequences not only result in long inference times but also occupy a significant amount of GPU memory, which greatly limits their application in scenarios involving understanding entire documents or videos.
Researchers from Alibaba Group and Renmin University of China have proposed a robust compression architecture called High-resolution DocCompressor. This method uses the visual features of a low-resolution global image as a compression guide (query), since the global feature map can effectively capture the overall layout information of the document.
Instead of dealing with all high-resolution features, the high-resolution document compressor collects a set of high-resolution features with identical relative positions in the original image as the compressed objects for each global feature map query. This layout-aware approach helps to better summarize text information within a specific layout region.
Furthermore, the researchers argue that compressing visual features after the vision-to-text module of the Large Multimodal Language Model can better preserve textual semantics in document images, as this is analogous to summarizing texts in Natural Language Processing.
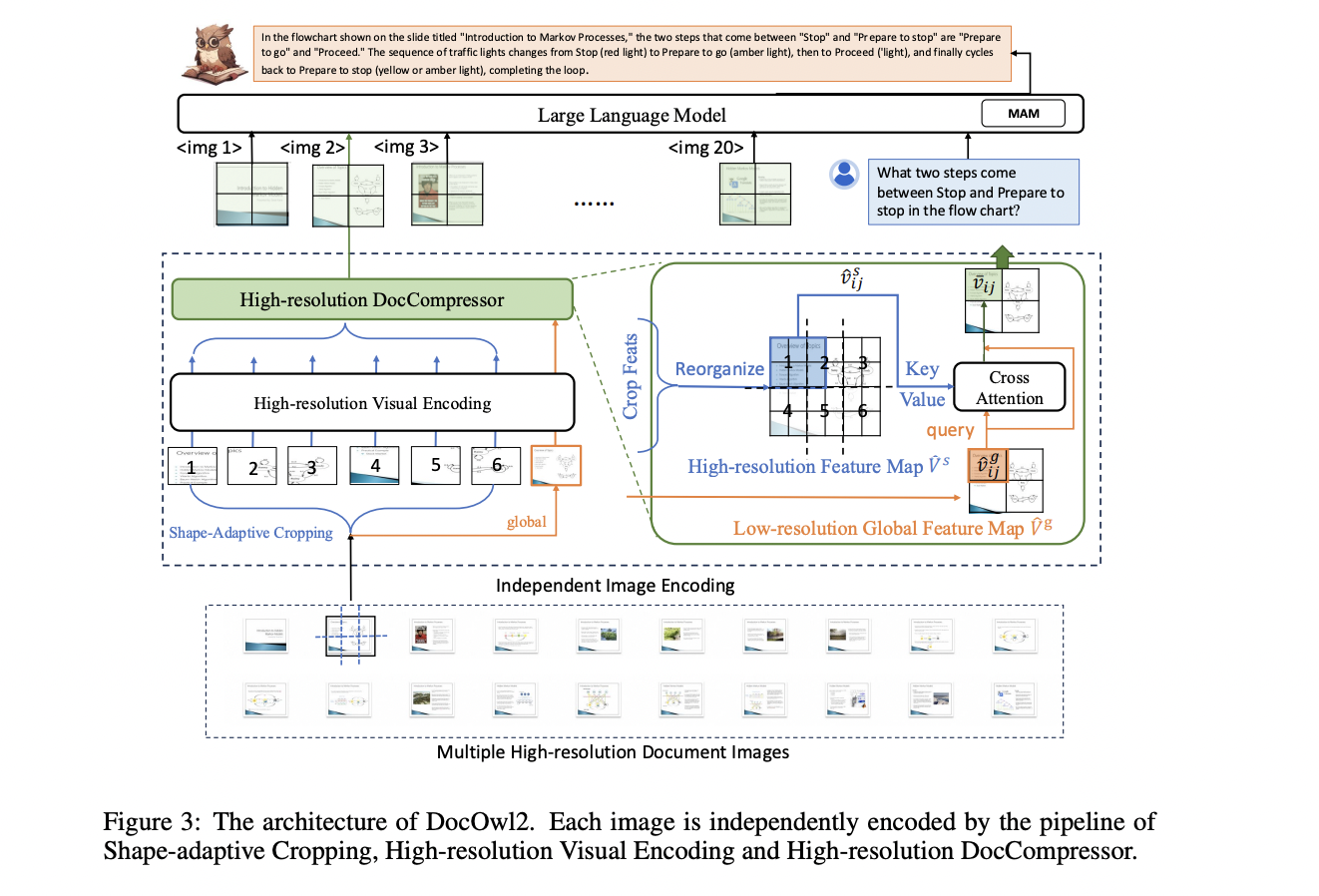
The DocOwl2 model uses a shape-adaptive crop module and a low-resolution vision encoder to encode high-resolution document images. The shape-adaptive crop module cuts the original image into multiple low-resolution sub-images, and the low-resolution vision encoder is used to encode both the sub-images and the global image. The model then uses a vision-to-text module called H-Reducer to pool the horizontal visual features and align the dimension of the visual features with the large language model. In addition to that, DocOwl2 includes a high-resolution compressor, which is the key component of the high-resolution document compressor. This compressor uses the visual features of the global low-resolution image as a query and collects a group of high-resolution features with identical relative positions in the original image as compression objects for each query. This layout-aware approach helps to better summarize text information within a specific layout region. Finally, compressed visual tokens from multiple images or pages are concatenated with text instructions and input into a Large Language Model for multimodal understanding.
The researchers compared the DocOwl2 model against state-of-the-art multimodal large language models on 10 single-image document understanding benchmarks, 2 multi-page document understanding benchmarks, and 1 text-heavy video understanding benchmark. They considered both question answering performance (as measured by ANLS) and first token latency (in seconds) to evaluate the effectiveness of their model. For the single-image document understanding task, the researchers split the baselines into three groups: (a) models without large language models as decoders, (b) multimodal LLMs with an average of more than 1000 visual tokens per document image, and (c) multimodal LLMs with fewer than 1000 visual tokens.
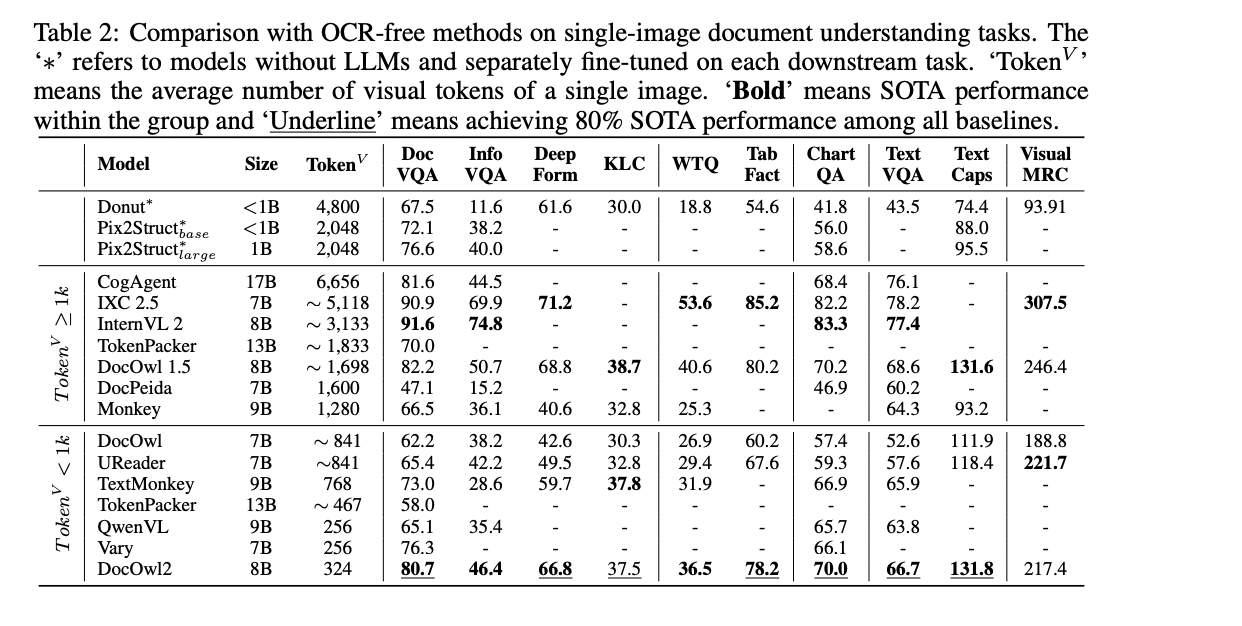
The results show that while models specifically tuned on each subsequent dataset performed well, the multimodal LLMs demonstrated the potential for generalized document understanding without OCR. Compared to other multimodal LLMs with fewer than 1000 visual tokens, the DocOwl2 model achieved better or comparable performance on all 10 benchmarks. Notably, with fewer visual tokens, DocOwl2 outperformed models such as TextMonkey and TokenPacker, which also aimed to compress visual tokens, demonstrating the effectiveness of the high-resolution DocCompressor.
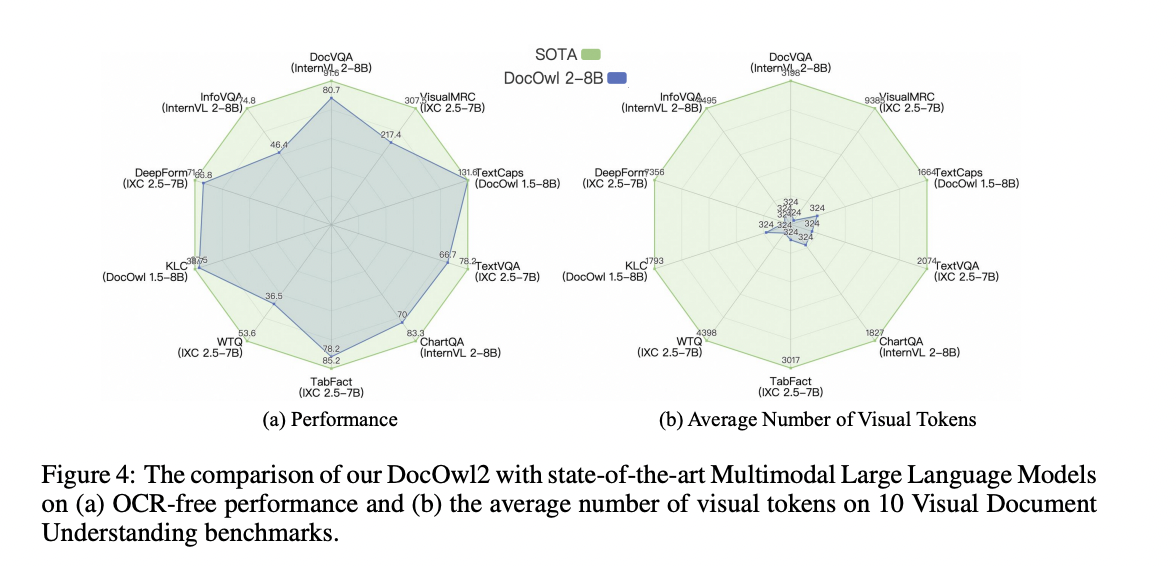
Furthermore, compared to state-of-the-art multimodal LLMs with over 1000 visual tokens, the DocOwl2 model achieved over 80% of their performance while using less than 20% of the visual tokens. For multi-page document understanding and text-heavy video understanding tasks, the DocOwl2 model also demonstrated superior performance and significantly lower first-token latency compared to other multimodal LLMs that can receive over 10 images using a single A100-80G GPU.
This study presents mPLUG-DocOwl2a multimodal large language model capable of efficiently understanding multi-page documents without OCR. DocCompressor’s robust high-resolution architecture compresses each high-resolution document image into just 324 tokens using cross-attention with global visual features as a guide. On single-image benchmarks, DocOwl2 outperforms existing compression methods and matches state-of-the-art MLLMs while using fewer visual tokens. It also achieves state-of-the-art performance without OCR on multi-page document and text-rich video understanding tasks with much lower latency. The researchers emphasize that using thousands of visual tokens per document page is often redundant and a waste of computational resources. They hope DocOwl2 will draw attention to the trade-off between efficient image representation and high-performance document understanding.
Take a look at the Paper and x-plug/mplug-docowl” target=”_blank” rel=”noreferrer noopener”>GitHub. All credit for this research goes to the researchers of this project. Also, don't forget to follow us on twitter.com/Marktechpost”>twitter and LinkedInJoin our Telegram Channel.
If you like our work, you will love our fact sheet..
Don't forget to join our SubReddit of over 50,000 ml
Asjad is a consultant intern at Marktechpost. He is pursuing Bachelors in Mechanical Engineering from Indian Institute of technology, Kharagpur. Asjad is a Machine Learning and Deep Learning enthusiast who is always researching the applications of Machine Learning in the healthcare domain.
<script async src="//platform.twitter.com/widgets.js” charset=”utf-8″>






{kind=link}