
GitHub Copilot is an ai-powered code completion assistant developed by GitHub and in collaboration with OpenAI, leveraging the ChatGPT model. It is designed to help developers speed up their coding process and minimize errors. The underlying model is trained with a combination of licensed code from GitHub’s own repositories and publicly available code, giving it a broad understanding of programming paradigms.
On the other hand, Databricks, an open, cloud-based analytics platform founded by the original creators of Apache Spark, enables organizations to seamlessly build data analytics and machine learning pipelines, thereby accelerating innovation. In addition, it encourages collaborative work between users.
GitHub Copilot’s integration with Databricks enables data analytics and machine learning engineers to deploy solutions efficiently and time-efficiently. This integration facilitates smoother code development, improves code quality and standardization, increases efficiency in multiple languages, accelerates prototype development, and assists in documentation, consequently raising the productivity and efficiency of engineers. .
Prerequisites for GitHub Copilot and Databricks integration:
Data Bricks Account setting.
Setting up GitHub Copilot.
Download and install visual studio code.
Install the Databricks plugin in the Visual Studio Code Marketplace.
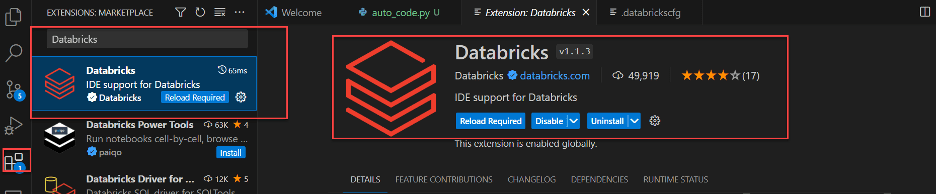
Configure the Databricks plugin in Visual Studio Code. If you have used the Databricks CLI before, it is already configured locally in the databrickscfg file. Otherwise, create the following content in the ~/.databrickscfg file.
(DEFAULT)
host = https://xxx
token = <token>
jobs-api-version = 2.0Click on the “Configure Databricks” option, then choose the first option from the drop-down menu, which shows the hostname configured in the previous step, and continue with the “DEFAULT” profile.
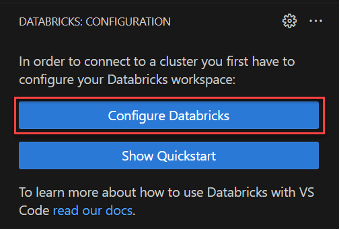
After you complete the setup, a Databricks connection is established with Visual Studio Code. You can view the cluster and workspace configuration details when you click the Databricks plugin.
Once a user completes GitHub Copilot account setup, ensure they have access to GitHub Copilot. Install the GitHub Copilot and GitHub Copilot Chat plugins in VSCode via Marketplace.

Once a user installs the GitHub Copilot and Copilot Chat plugins, they will be prompted to sign in to GitHub Copilot through the Visual Studio IDE. If you are not prompted for authorization, click the bell icon in the bottom panel of the Visual Studio Code IDE.

Now is the time to develop with GitHub Copilot
Data engineers can use GitHub Copilot to write data engineering processes at their fingertips at a faster pace, including documentation, in no time. Below are steps to create a simple data engineering pipeline with prompting techniques.
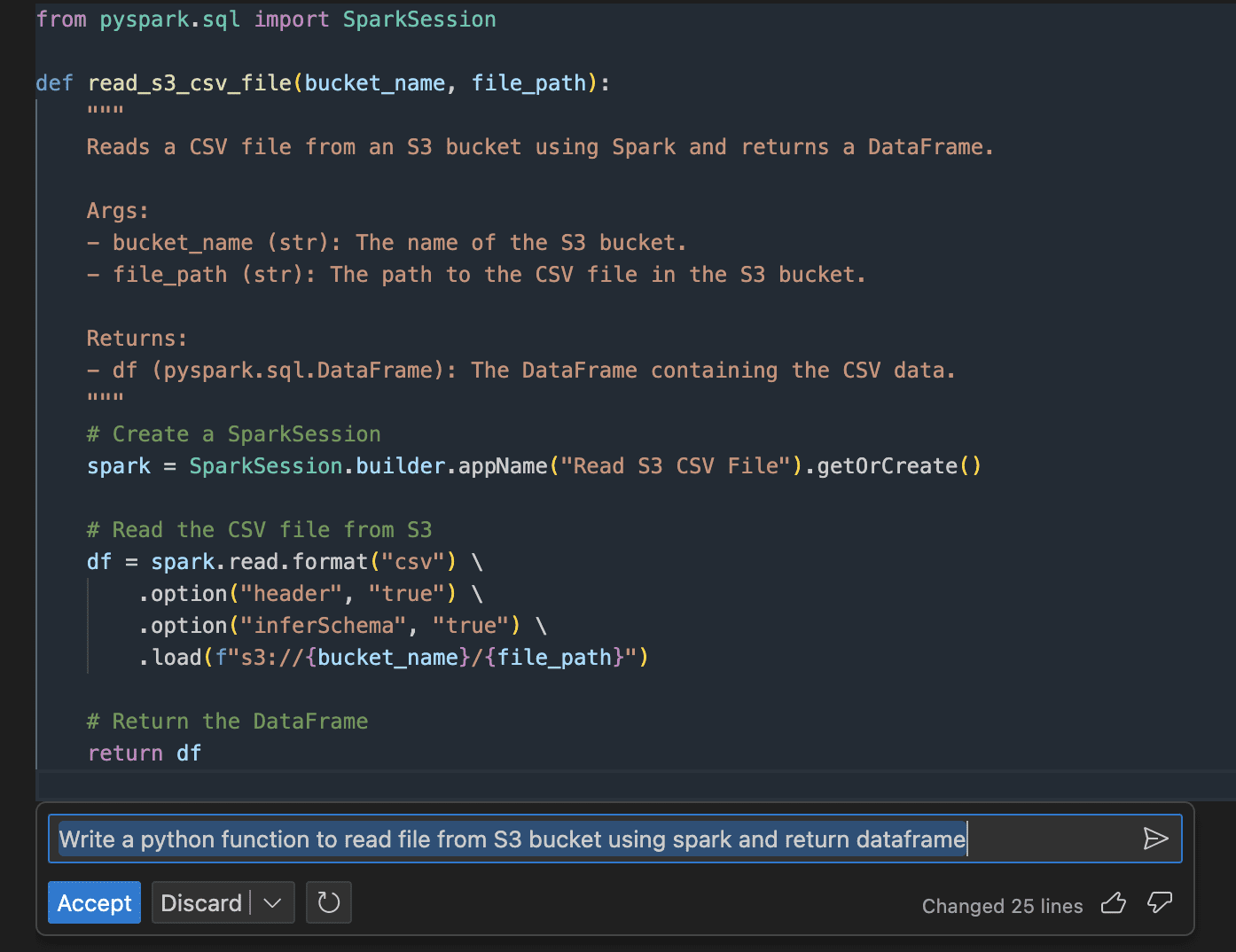
Read files from S3 bucket using Python and Spark framework.
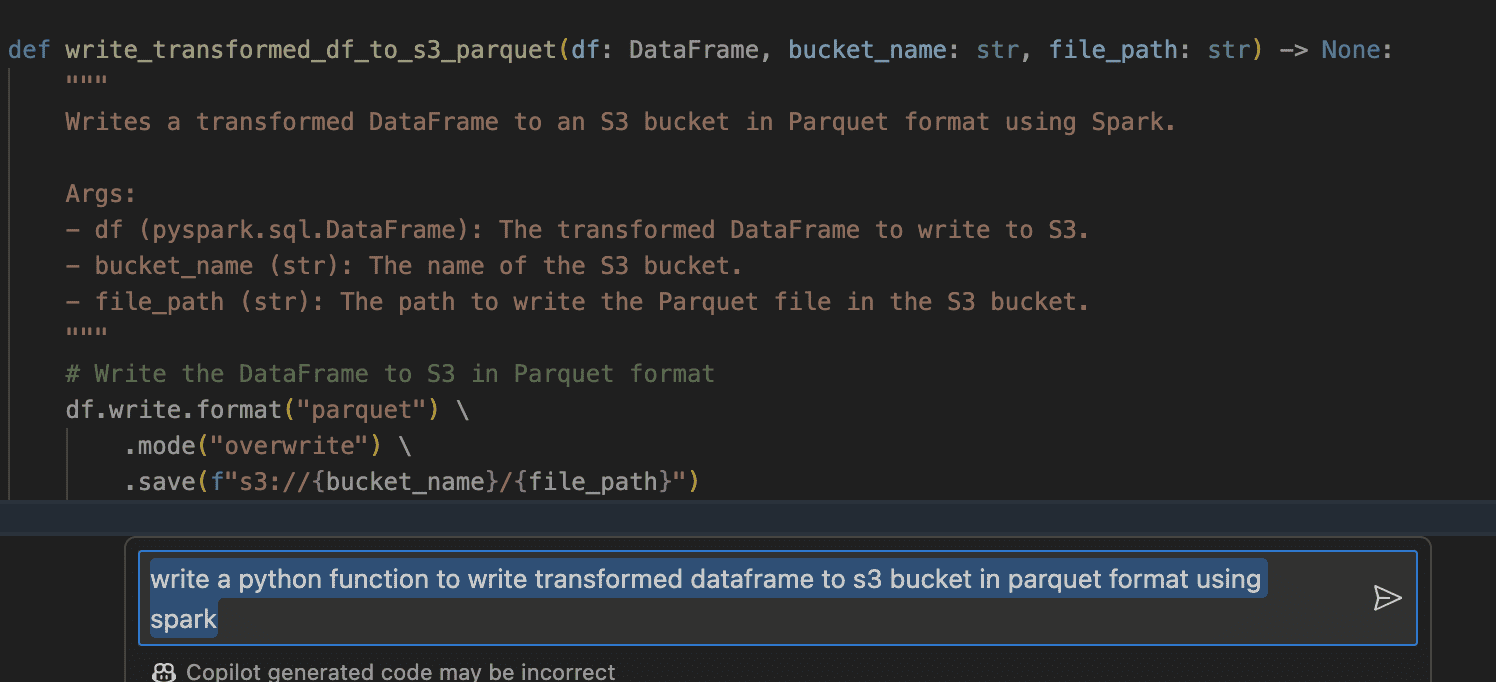
Write a data frame to S3 bucket using Python and Spark framework
Execute the functions through the main method: represented in the message and code result with the execution steps.
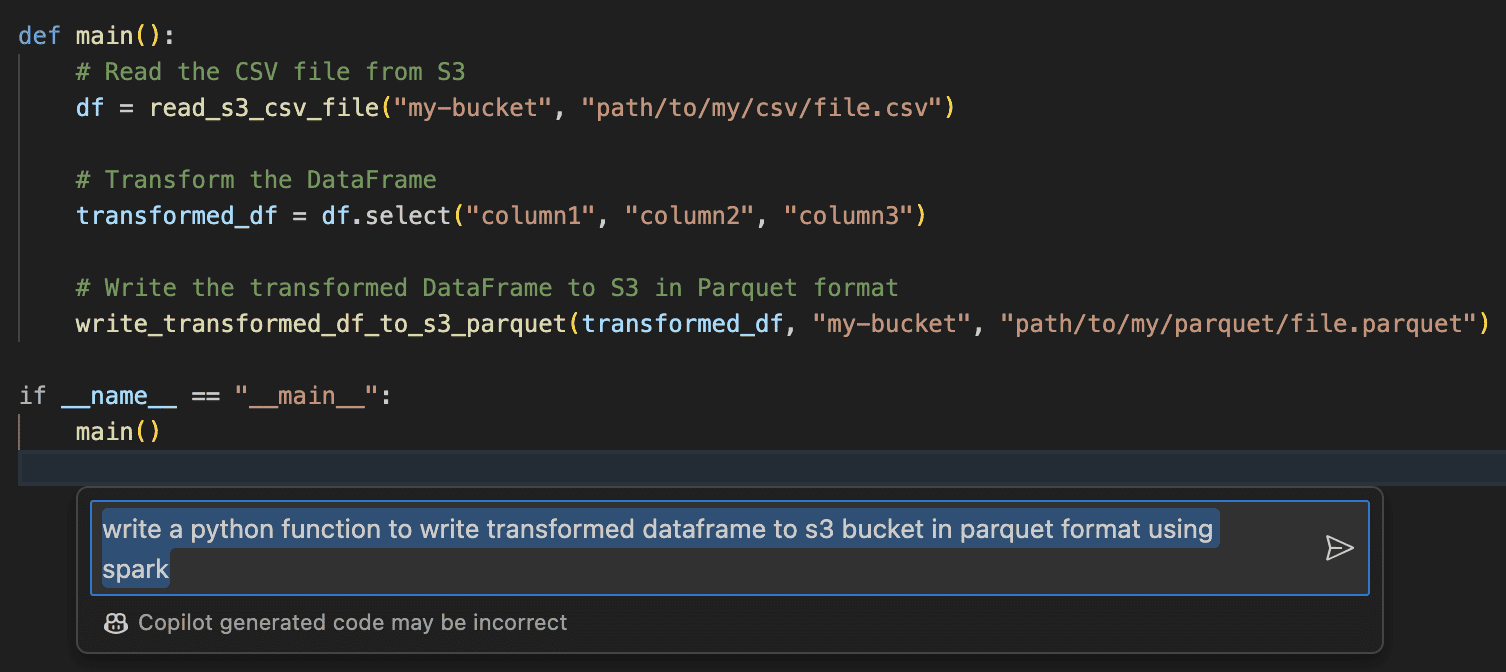
- Good ai pair programming tool for quick and sensible suggestions and provides boilerplate code.
- Top-level tips for optimizing code and runtime.
- Better documentation and ASCII representation for logical steps.
- Faster data pipeline implementation with minimal errors.
- Explain in detail the existing simple/complex functionality and suggest smart code refactoring techniques.
- Opens a Co-pilot text/search bar where you can enter your directions.

Windows: (Cltr) + (I)Mac: Command + (I)
- Discard an online suggestion.
Windows/Mac: Esc
- Accept a suggestion.
Windows/Mac: tab
- See suggestions above.
Windows: (Alt) + (
Mac: (option) + (
- See the next tip
Windows: (Alt) + )
Mac: (option) + )
Integrating ai pair programming tools with integrated development environments helps developers accelerate development with real-time code suggestions, reducing time spent consulting documentation for boilerplate code and syntaxes, and allows developers to focus on innovations and business problem-solving use cases. .
Additional Resources
Naresh Vurukonda is a principal architect with over 10 years of experience building data engineering and machine learning projects in healthcare and life sciences organizations and media networks.






{kind=link}