 NEWSLETTER
NEWSLETTER
Esta publicación fue escrita por Claudiu Bota, Oleg Yurchenko y Vladyslav Melnyk de AWS Partner Automat-It.
A medida que las organizaciones adoptan la IA y el aprendizaje automático (ML), están utilizando estas tecnologías para mejorar los procesos y mejorar los productos. Los casos de uso de IA incluyen análisis de video, predicciones de mercado, detección de fraude y procesamiento del lenguaje natural, todos dependiendo de modelos que analizan los datos de manera eficiente. Aunque los modelos logran una precisión impresionante con poca latencia, a menudo exigen recursos computacionales con un poder informático significativo, incluidas las GPU, para ejecutar inferencias. Por lo tanto, mantener el equilibrio adecuado entre el rendimiento y el costo es esencial, especialmente cuando se implementa modelos a escala.
Uno de nuestros clientes encontró este desafío exacto. Para abordar este problema, se comprometieron Automat-itun socio de primer nivel AWS, para diseñar e implementar su plataforma en AWS, específicamente utilizando el Servicio Elástico Kubernetes (amazon EKS). Automat-IT se especializa en ayudar a las nuevas empresas y escamas a crecer a través de servicios prácticos de las nubes, MLOPS y FINOPS. La colaboración tenía como objetivo lograr la escalabilidad y el rendimiento al tiempo que optimizaba los costos. Su plataforma requiere modelos altamente precisos con baja latencia, y los costos para tales tareas exigentes se intensifican rápidamente sin una optimización adecuada.
En esta publicación, explicamos cómo Automat-It ayudó a este cliente a lograr un ahorro de costos de más de doce veces al tiempo que mantiene el rendimiento del modelo de IA dentro de los umbrales de rendimiento requeridos. Esto se logró mediante un ajuste cuidadoso de la arquitectura, la selección de algoritmos y la gestión de la infraestructura.
Desafío del cliente
Nuestro cliente se especializa en el desarrollo de modelos de IA para soluciones de inteligencia de video utilizando Yolov8 y la Biblioteca Ultralítica. Una implementación de Yolov8 de extremo a extremo consta de tres etapas:
- Preprocesamiento – Prepara marcos de video en bruto a través del cambio de tamaño, la normalización y la conversión de formato
- Inferencia – en el que el modelo Yolov8 genera predicciones mediante la detección y clasificación de objetos en los marcos de video curados
- Posprocesamiento -en el que las predicciones se refinan utilizando técnicas como la supresión no máxima (NMS), el filtrado y el formato de salida.
Proporcionan a sus clientes modelos que analizan transmisiones de video en vivo y extraen información valiosa de los marcos capturados, cada uno personalizado a un caso de uso específico. Inicialmente, la solución requería que cada modelo se ejecutara en una GPU dedicada en tiempo de ejecución, lo que necesita instancias de GPU por cliente. Esta configuración condujo a recursos de GPU subutilizados y costos operativos elevados.
Por lo tanto, nuestro objetivo principal era optimizar la utilización de GPU al tiempo que reducía los costos generales de la plataforma y mantiene el tiempo de procesamiento de datos lo más mínimo posible. Específicamente, nuestro objetivo fue limitar los costos de infraestructura de AWS a $ 30 por cámara por mes mientras mantiene el tiempo total de procesamiento (preprocesamiento, inferencia y posprocesamiento) por debajo de 500 milisegundos. Lograr estos ahorros sin reducir el rendimiento del modelo, particularmente manteniendo la baja latencia de inferencia, los semillas esenciales para proporcionar el nivel de servicio deseado para cada cliente.
Enfoque inicial
Nuestro enfoque inicial siguió a una arquitectura de cliente cliente, dividiendo la implementación de Yolov8 de extremo a extremo en dos componentes. El componente del cliente, que se ejecuta en instancias de CPU, manejó las etapas de preprocesamiento y posprocesamiento. Mientras tanto, el componente del servidor, que se ejecuta en instancias de GPU, se dedicó a la inferencia y respondió a las solicitudes del cliente. Esta funcionalidad se implementó utilizando un envoltorio GRPC personalizado, que proporciona una comunicación eficiente entre los componentes.
El objetivo de este enfoque era reducir los costos mediante el uso de GPU exclusivamente para la etapa de inferencia en lugar de para toda la implementación de extremo a extremo. Además, supusimos que la latencia de comunicación cliente-servidor tendría un impacto mínimo en el tiempo de inferencia general. Para evaluar la efectividad de esta arquitectura, realizamos pruebas de rendimiento utilizando los siguientes parámetros de referencia:
- La inferencia se realizó en
g4dn.xlargeInstancias basadas en GPU porque los modelos del cliente estaban optimizados para ejecutarse en T4 GPU NVIDIA - Los modelos del cliente utilizaron el modelo YOLOV8N con Ultralytics versión 8.2.71
Los resultados se evaluaron en función de los siguientes indicadores de rendimiento clave (KPI):
- Tiempo de preprocesamiento – La cantidad de tiempo requerida para preparar los datos de entrada para el modelo
- Tiempo de inferencia – La duración tomada por el modelo Yolov8 para procesar la entrada y producir resultados
- Tiempo de postprocesamiento – El tiempo necesario para finalizar y formatear la salida del modelo para su uso
- Tiempo de comunicación de red – La duración de la comunicación entre el componente del cliente que se ejecuta en instancias de CPU y el componente del servidor que se ejecuta en instancias de GPU
- Tiempo total – La duración general desde cuando se envía una imagen al modelo Yolov8 hasta que se reciben los resultados, incluidas todas las etapas de procesamiento
Los hallazgos fueron los siguientes:
| Preprocesos (MS) | Inferencia (MS) | Postprocess (MS) | Comunicación de red (MS) | Total (MS) | |
| GRPC personalizado | 2.7 | 7.9 | 1.1 | 10.26 | 21.96 |
La instancia basada en GPU completó la inferencia en 7.9 ms. Sin embargo, la sobrecarga de comunicación de red de 10.26 ms aumentó el tiempo de procesamiento total. Aunque el tiempo de procesamiento total era aceptable, cada modelo requería una instancia dedicada basada en GPU para ejecutarse, lo que resultó en costos inaceptables para el cliente. Específicamente, el costo de inferencia por cámara fue de $ 353.03 mensualmente, superando el presupuesto del cliente.
Encontrar una mejor solución
Aunque los resultados de rendimiento fueron prometedores, incluso con la latencia adicional de la comunicación de la red, los costos por cámara aún eran demasiado altos, por lo que nuestra solución necesitaba una mayor optimización. Además, el envoltorio GRPC personalizado carecía de un mecanismo de escala automático para acomodar la adición de nuevos modelos y requirió un mantenimiento continuo, lo que se suma a su complejidad operativa.
Para abordar estos desafíos, nos alejamos del enfoque de cliente cliente e implementamos la calma de tiempo de GPU (fraccionalización), que implica dividir el acceso a la GPU en intervalos de tiempo discretos. Este enfoque permite que los modelos de IA compartan una sola GPU, cada una utilizando una GPU virtual durante su porción asignada. Es similar a la película de tiempo de la CPU entre procesos, optimizando la asignación de recursos sin reducir el rendimiento. Este enfoque se inspiró en varias publicaciones de blog de AWS que se pueden encontrar en la sección de referencias.
Implementamos el tiempo de escrutinio de GPU en el clúster EKS utilizando el Complemento del dispositivo Nvidia Kubernetes. Esto nos equipó para usar los mecanismos de escala nativos de Kubernetes, simplificando el proceso de escala para acomodar nuevos modelos y reducir la sobrecarga operativa. Además, al confiar en el complemento, evitamos la necesidad de mantener un código personalizado, simplificando tanto la implementación como el mantenimiento a largo plazo.
En esta configuración, la instancia de GPU se estableció para dividirse en 60 GPU virtuales con rodajas de tiempo. Utilizamos los mismos KPI que en la configuración anterior para medir la eficiencia y el rendimiento en estas condiciones optimizadas, asegurando que la reducción de costos se alinee con nuestros puntos de referencia de calidad de servicio.
Realizamos las pruebas en tres etapas, como se describe en las siguientes secciones.
Etapa 1
En esta etapa, corrimos una cápsula en un g4dn.xlarge Instancia basada en GPU. Cada POD ejecuta las tres fases de la implementación de Yolov8 de extremo a extremo en la GPU y procesa marcos de video desde una sola cámara. Los hallazgos se muestran en el siguiente gráfico y tabla.
| Preprocesos (MS) | Inferencia (MS) | Postprocess (MS) | Total (MS) | |
| 1 vaina | 2 | 7.8 | 1 | 10.8 |
Logramos con éxito un tiempo de inferencia de 7.8 ms y un tiempo de procesamiento total de 10.8 ms, que se alineó con los requisitos del proyecto. El uso de la memoria de GPU para un solo pod fue de 247MIB, y la utilización del procesador de GPU fue del 12%. El uso de la memoria por vaina indicó que podríamos ejecutar aproximadamente 60 procesos (o POD) en una GPU de 16GIB.
Etapa 2
En esta etapa, corrimos 20 vainas en un g4dn.2xlarge Instancia basada en GPU. Cambiamos el tipo de instancia de g4dn.xlarge a g4dn.2xlarge Debido a la sobrecarga de la CPU asociada con el procesamiento y la carga de datos. Los hallazgos se muestran en el siguiente gráfico y tabla.
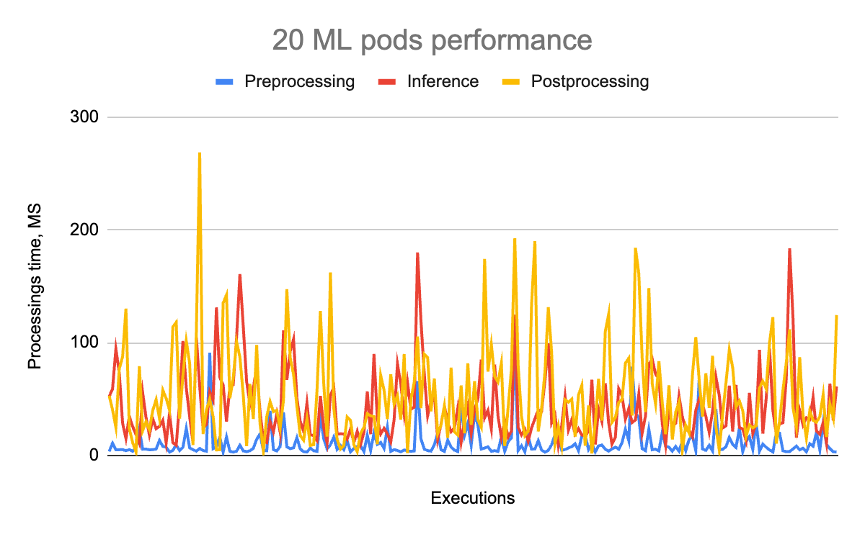
| Preprocesos (MS) | Inferencia (MS) | Postprocess (MS) | Total (MS) | |
| 20 vainas | 11 | 42 | 55 | 108 |
En esta etapa, el uso de la memoria de GPU alcanzó los 7,244 MIB, con la utilización del procesador de GPU alcanzando un alcance de la máxima visión del 95% y 99%. Un total de 20 vainas utilizaron la mitad de la memoria GIB de la GPU y consumieron completamente el procesador de GPU, lo que condujo a un aumento de los tiempos de procesamiento. Aunque tanto la inferencia como los tiempos de procesamiento totales aumentaron, este resultado se anticipó y se consideró aceptable. El siguiente objetivo fue determinar el número máximo de POD que la GPU podría admitir en su capacidad de memoria.
Etapa 3
En esta etapa, nuestro objetivo era ejecutar 60 vainas en un g4dn.2xlarge Instancia basada en GPU. Posteriormente, cambiamos el tipo de instancia desde g4dn.2xlarge a g4dn.4xlarge y luego a g4dn.8xlarge.
El objetivo era maximizar la utilización de la memoria de GPU. Sin embargo, el procesamiento de datos y la carga sobrecargaron la CPU de la instancia. Esto nos llevó a cambiar a instancias que todavía tenían una GPU pero ofrecían más CPU.
Los hallazgos se muestran en el siguiente gráfico y tabla.
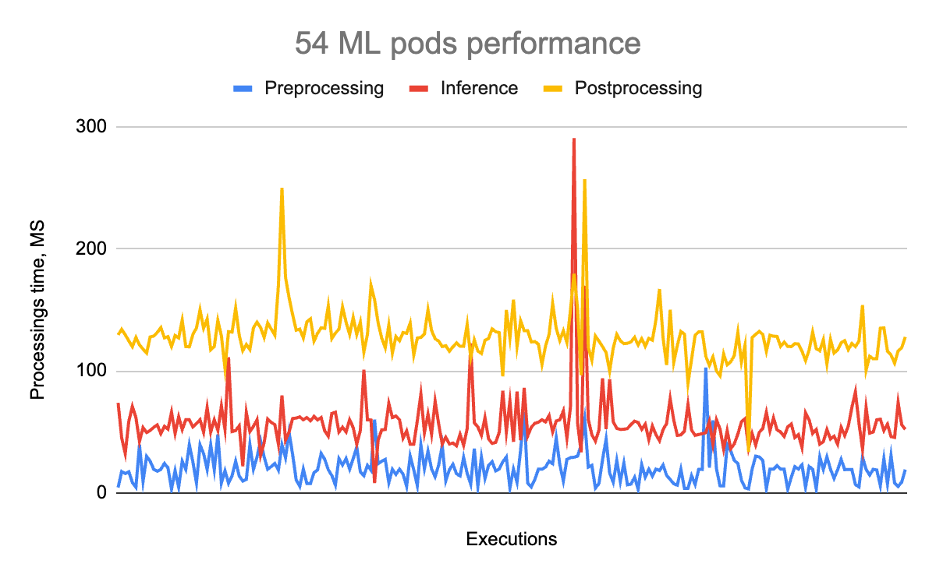
| Preprocesos (MS) | Inferencia (MS) | Postprocess (MS) | Total (MS) | |
| 54 vainas | 21 | 56 | 128 | 205 |
El uso de la memoria de GPU fue de 14780MIB, y la utilización del procesador de GPU fue del 99-100%. A pesar de estos ajustes, encontramos errores de GPU fuera de memoria que nos impidieron programar los 60 pods. En última instancia, podríamos acomodar 54 vainas, representando el número máximo de modelos de IA que podrían caber en una sola GPU.
En este escenario, los costos de inferencia por cámara asociados con el uso de GPU fueron de $ 27.81 por mes por cámara, una reducción de doce veces en comparación con el enfoque inicial. Al adoptar este enfoque, cumplimos con éxito con los requisitos de costos del cliente por cámara por mes mientras mantenemos niveles de rendimiento aceptables.
Conclusión
En esta publicación, exploramos cómo Automat-It ayudó a uno de nuestros clientes a lograr una reducción de costos de doce veces al tiempo que mantiene el rendimiento de sus modelos de IA basados en Yolov8 dentro de los rangos aceptables. Los resultados de la prueba demuestran que la película de tiempo de GPU permite que el número máximo de modelos de IA funcione de manera eficiente en un solo GPU, reduciendo significativamente los costos al tiempo que proporciona un alto rendimiento. Además, este método requiere un mantenimiento y modificaciones mínimas al código del modelo, mejorando la escalabilidad y la facilidad de uso.
Referencias
Para obtener más información, consulte los siguientes recursos:
AWS
Comunidad
Descargo de responsabilidad
El contenido y las opiniones en esta publicación son los del autor de terceros y AWS no es responsable del contenido o precisión de esta publicación.
Sobre los autores
 Claudiu Bota es un arquitecto de soluciones senior en Automat-It, que ayuda a los clientes de toda la región de EMEA migrando a AWS y optimizar sus cargas de trabajo. Se especializa en contenedores, tecnologías sin servidor y microservicios, centrándose en la creación de soluciones en la nube escalables y eficientes. Fuera del trabajo, a Claudiu le gusta leer, viajar y jugar al ajedrez.
Claudiu Bota es un arquitecto de soluciones senior en Automat-It, que ayuda a los clientes de toda la región de EMEA migrando a AWS y optimizar sus cargas de trabajo. Se especializa en contenedores, tecnologías sin servidor y microservicios, centrándose en la creación de soluciones en la nube escalables y eficientes. Fuera del trabajo, a Claudiu le gusta leer, viajar y jugar al ajedrez.
 Oleg Yurchenko es el director de DevOps en Automat-It, donde encabeza la experiencia de la compañía en las mejores prácticas y soluciones de DevOps. Sus áreas de enfoque incluyen contenedores, kubernetes, sin servidor, infraestructura como código y CI/CD. Con más de 20 años de experiencia práctica en administración del sistema, DevOps y tecnologías en la nube, Oleg es un defensor apasionado de sus clientes, guiándolos en la construcción de soluciones en la nube modernas, escalables y rentables.
Oleg Yurchenko es el director de DevOps en Automat-It, donde encabeza la experiencia de la compañía en las mejores prácticas y soluciones de DevOps. Sus áreas de enfoque incluyen contenedores, kubernetes, sin servidor, infraestructura como código y CI/CD. Con más de 20 años de experiencia práctica en administración del sistema, DevOps y tecnologías en la nube, Oleg es un defensor apasionado de sus clientes, guiándolos en la construcción de soluciones en la nube modernas, escalables y rentables.
 Vladyslav melnyk es ingeniero senior de MLOPS en Automat-It. Es un entusiasta experimentado del aprendizaje profundo con pasión por la inteligencia artificial, cuidando los productos de IA a través de su ciclo de vida, desde la experimentación hasta la producción. Con más de 9 años de experiencia en IA en entornos de AWS, también es un gran fanático de aprovechar herramientas geniales de código abierto. Orientado a los resultados y ambicioso, con un fuerte enfoque en MLOPS, Vladyslav garantiza transiciones suaves y una implementación de modelo eficiente. Es experto en entregar modelos de aprendizaje profundo, siempre aprendiendo y adaptándose para mantenerse a la vanguardia en el campo.
Vladyslav melnyk es ingeniero senior de MLOPS en Automat-It. Es un entusiasta experimentado del aprendizaje profundo con pasión por la inteligencia artificial, cuidando los productos de IA a través de su ciclo de vida, desde la experimentación hasta la producción. Con más de 9 años de experiencia en IA en entornos de AWS, también es un gran fanático de aprovechar herramientas geniales de código abierto. Orientado a los resultados y ambicioso, con un fuerte enfoque en MLOPS, Vladyslav garantiza transiciones suaves y una implementación de modelo eficiente. Es experto en entregar modelos de aprendizaje profundo, siempre aprendiendo y adaptándose para mantenerse a la vanguardia en el campo.





{kind=link}